独家 | Python利用深度学习进行文本摘要的综合指南(附教程)

作者:ARAVIND PAI
翻译:和中华
校对:申利彬
本文约7500字,建议阅读15分钟。
本文介绍了如何利用seq2seq来建立一个文本摘要模型,以及其中的注意力机制。并利用Keras搭建编写了一个完整的模型代码。
介绍
“我不想要完整的报告,只需给我一个结果摘要”。我发现自己经常处于这种状况——无论是在大学还是在职场中。我们准备了一份综合全面的报告,但教师/主管却仅仅有时间阅读摘要。
听起来很熟悉?好吧,我决定对此采取一些措施。手动将报告转换为摘要太耗费时间了,对吧?那我可以依靠自然语言处理(NLP)技术来帮忙吗?
自然语言处理(NLP)
https://courses.analyticsvidhya.com/courses/natural-language-processing-nlp?utm_source=blog&utm_medium=comprehensive-guide-text-summarization-using-deep-learning-python
这就是使用深度学习的文本摘要真正帮助我的地方。它解决了以前一直困扰着我的问题——现在我们的模型可以理解整个文本的上下文。对于所有需要把文档快速摘要的人来说,这个梦想已成现实!
我们使用深度学习完成的文本摘要结果如何呢?非常出色。因此,在本文中,我们将逐步介绍使用深度学习构建文本摘要器的过程,其中包含构建它所需的全部概念。然后将用Python实现我们的第一个文本摘要模型!
注意:本文要求对一些深度学习概念有基本的了解。 我建议阅读以下文章。
A Must-Read Introduction to Sequence Modelling (with use cases)
https://www.analyticsvidhya.com/blog/2018/04/sequence-modelling-an-introduction-with-practical-use-cases/?
utm_source=blog&utm_medium=comprehensive-guide-text-summarization-using-deep-learning-python
Must-Read Tutorial to Learn Sequence Modeling (deeplearning.ai Course #5)
https://www.analyticsvidhya.com/blog/2019/01/sequence-models-deeplearning/?utm_source=blog&utm_medium=comprehensive-guide-text-summarization-using-deep-learning-python
Essentials of Deep Learning: Introduction to Long Short Term Memory
https://www.analyticsvidhya.com/blog/2017/12/fundamentals-of-deep-learning-introduction-to-lstm/?utm_source=blog&utm_medium=comprehensive-guide-text-summarization-using-deep-learning-python
目录
1. NLP中的文本摘要是什么?
2. 序列到序列(Seq2Seq)建模简介
3. 理解编码器(Encoder)-解码器(Decoder)架构
4. 编码器-解码器结构的局限性
5. 注意力机制背后的直觉
6. 理解问题陈述
7. 使用Keras在Python中实现文本摘要模型
8. 注意力机制如何运作?
我在本文的最后面保留了“注意力机制如何运作?”的部分。这是一个数学密集的部分,并不强制了解Python代码的工作原理。但是,我鼓励你通读它,因为它会让你对这个NLP概念有一个坚实的理解。
1. NLP中的文本摘要是什么?
在了解它是如何工作之前,我们先来看看文本摘要是什么。如下是一个简洁的定义,我们开始吧:
“自动文本摘要的任务是生成简明扼要的摘要,同时保留关键信息内容和整体含义”
- 文本摘要技术:简要调查,
2017
大致有两种不同的方法用于文本摘要:
抽取式摘要(Extractive Summarization)
生成式摘要(Abstractive Summarization)
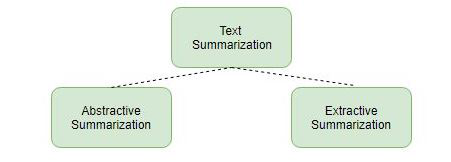
让我们更详细地看一下这两种类型。
抽取式摘要
这个名字透露了这种方法的作用。我们从原文中找出重要的句子或短语,并从中抽取。这些抽取出的句子将成为我们的总结。下图简要说明了抽取式摘要:
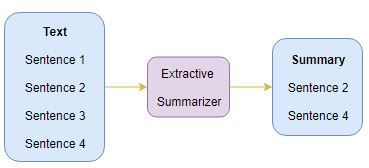
我建议你通读这篇文章,它介绍了如何使用TextRank算法构建一个抽取式文本摘要器:
An Introduction to Text Summarization using the TextRank Algorithm (with Python implementation)
https://www.analyticsvidhya.com/blog/2018/11/introduction-text-summarization-textrank-python/
生成式摘要
这是一个非常有趣的方法。当中,我们会从原文中生成新的句子。这与我们之前看到的抽取方法形成了对比,之前我们只使用了现存的句子。通过生城式摘要生成的句子可能并未出现在原文中:
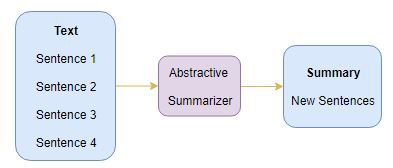
你可能已经猜到了——我们将在本文中使用深度学习构建一个生成式文本摘要器! 在深入实现这部分之前,我们先了解一些构建文本摘要生成模型所需的概念。
前方高能!
2. 序列到序列(Seq2Seq)建模简介
我们可以针对涉及顺序信息的任何问题构建Seq2Seq模型。顺序信息的一些非常常见的应用包括情感分类,神经网络机器翻译和命名实体识别。
在神经网络机器翻译的情况下,输入是某一种语言的文本,输出是另一种语言的文本:

在命名实体识别中,输入是一个单词序列,而输出是输入序列中每个单词的标记序列:
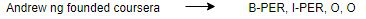
我们的目标是构建一个文本摘要生成器,其中输入是一个单词的长序列(文本正文),输出是一个简短的摘要(也是一个序列)。 因此,我们可以将其建模为多对多Seq2Seq问题。 以下是一个典型的Seq2Seq模型架构:
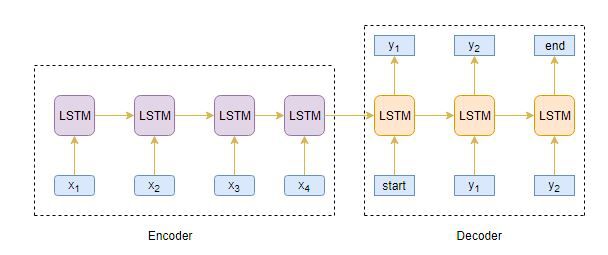
Seq2Seq模型有两个主要组件:
编码器
解码器
我们来详细了解一下这两个组件。这些对于理解文本摘要是如何工作的代码至关重要。你还可以查看本教程以更详细地了解序列到序列建模。
教程:
https://www.analyticsvidhya.com/blog/2018/03/essentials-of-deep-learning-sequence-to-sequence-modelling-with-attention-part-i/?utm_source=blog&utm_medium=comprehensive-guide-text-summarization-using-deep-learning-python
3. 理解编码器-解码器架构
编码器-解码器架构主要用于解决输入和输出序列长度不同的序列到序列(Seq2Seq)问题。
让我们从文本摘要的角度来理解这一点。输入是一长串单词,输出是输入序列的简短版本。
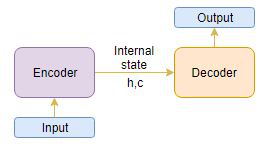
通常,循环神经网络(RNN)的变体,比如门控循环神经网络(GRU)或长短时记忆(LSTM),将优选作为编码器和解码器组件。这是因为它们能够通过克服梯度弥散问题来捕获长期依赖性。
我们可以分两个阶段设置编码器-解码器:
训练阶段
推理阶段
让我们通过LSTM模型来理解这些概念。
训练阶段
在训练阶段,我们将首先设置编码器和解码器。然后,我们将训练模型以预测偏移一个时间步长的目标序列。我们详细了解一下如何设置编码器和解码器。
编码器
编码器长短时记忆模型(LSTM)读取整个输入序列,其中在每个时间步,一个单词被送到编码器。然后,它在每个时间步处理信息并捕获输入序列中存在的上下文信息。
下图说明了这个过程:
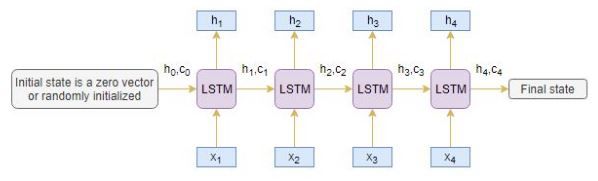
最后一个时间步的隐藏状态(hi)和单元状态(ci)用于初始化解码器。请记住,这是因为编码器和解码器是两套LSTM架构。
解码器
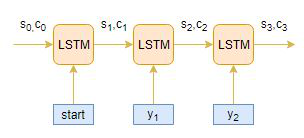
解码器也是LSTM网络,它逐字读取整个目标序列并在每一个时间步预测相同的序列偏移。训练解码器以达到,给定前一个词预测序列中的下一个词。
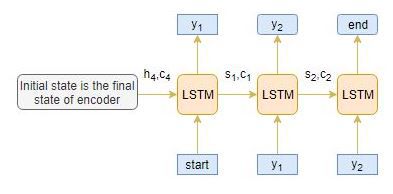
<start>和<end>是在将其提供给解码器之前添加到目标序列的特殊标记。解码测试序列时,目标序列是未知的。因此,我们通过将第一个字(始终是<start>标记)传递给解码器来开始预测目标序列,并且<end>标记表示句子的结尾。
到目前为止非常直观。
推理阶段
训练后,用目标序列未知的新序列来测试模型。因此,我们需要设置推理架构来解码测试序列:
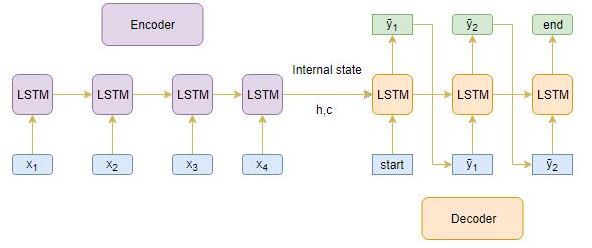
推理过程如何工作?
以下是解码测试序列的步骤:
1. 对整个输入序列进行编码,并使用编码器的内部状态初始化解码器
2. 将<start>标记作为解码器的输入
3. 使用内部状态运行解码器一个时间步
4. 输出将是下一个单词的概率。将选择具有最大概率的单词
5. 在下一个时间步中将采样的字作为输入传递给解码器,并使用当前时间步更新内部状态
6. 重复步骤3-5,直到我们生成<end>标记或达到目标序列的最大长度
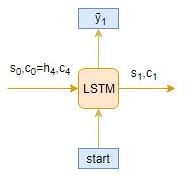
我们举一个例子,测试序列由[x1,x2,x3,x4]给出。推理过程如何作用于此测试序列?希望你在往下看之前先自己考虑一下。
1. 将测试序列编码为内部状态向量
2. 观察解码器如何在每个时间步预测目标序列:
Timestep: t=1
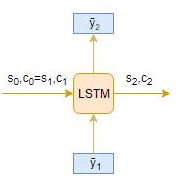
Timestep: t=2
Timestep: t=3
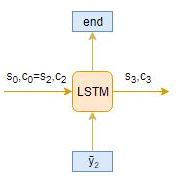
4. 编码器-解码器结构的局限性
尽管这种编码器-解码器架构很有用,但它也有一些限制。
编码器将整个输入序列转换为固定长度的向量,然后解码器预测输出序列。这仅适用于短序列,因为解码器需要查看整个输入序列来预测
长序列的问题是,编码器难以将长序列记忆成一个固定长度的向量
“这种编码器-解码器方法的潜在问题是神经网络需要能够将源句子的所有必要信息压缩成固定长度的向量。这可能使神经网络难以应对长句。随着输入句子长度的增加,基本的编码器-解码器性能将迅速恶化。“
-Neural Machine Translation by Jointly Learning to Align and Translate
那么我们如何克服长序列这个问题呢?这就是注意力机制被引入的地方。它旨在通过仅仅查看序列的一些特定部分而不是整个序列来预测单词。这听起来就很棒!
5. 注意力机制背后的直觉
我们来考虑一个简单的例子来理解注意力机制的工作原理:
源序列:“你最喜欢哪项运动?(Which sport do you like the most?)
目标序列:“我喜欢板球”(I love cricket)
目标序列中的第一个单词'I',与源序列中的第四个单词'you'相连,对吗? 类似地,目标序列中的第二个单词“love”与源序列中的第五个单词“like”相关联。
因此,我们可以增加源序列中特定部分(正是这部分与目标序列相关)的重要性,而不是查看源序列中的所有单词。这正是注意力机制背后的基本思想。
根据参与的上下文向量的派生方式,有2种不同类型的注意力机制:
全局注意力(Global Attention)
局部注意力(Local Attention)
让我们简要介绍一下这些分类。
全局注意力
这种情况下,注意力集中在所有源位置上。换句话说,编码器的所有隐藏状态都被考虑用于导出参与的上下文向量:
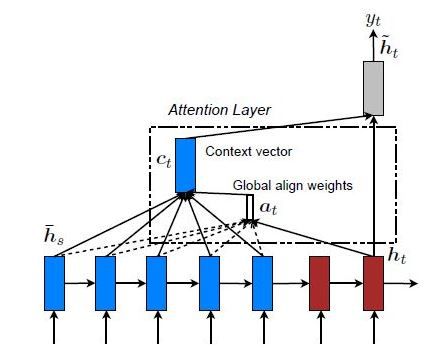
局部注意力
这种情况下,只关注几个源位置。仅考虑编码器的几个隐藏状态来导出参与的上下文向量:
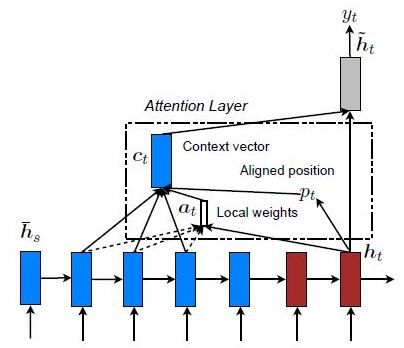
我们将在本文中使用全局注意力机制。
6. 理解问题陈述
客户评论通常很长且具有描述性。正如你可以想象的那样,手动分析这些评论非常耗时。这是自然语言处理可用于生成长评论摘要的地方。
我们将基于一个非常酷的数据集来工作。我们的目标是使用之前学到的基于生成式的方法生成亚马逊美食评论的摘要。
可以从此处下载数据集。
https://www.kaggle.com/snap/amazon-fine-food-reviews
7. 使用Keras在Python中实现文本摘要
现在是时候开启我们的Jupyter notebook了!让我们马上深入了解实施细节。
自定义注意力层
Keras官方没有正式支持注意力层。 因此,我们要么实现自己的注意力层,要么使用第三方实现。在本文中我们采用后者。你可以从此处下载注意力层,并将其复制到名为attention.py的文件中。
https://github.com/thushv89/attention_keras/blob/master/layers/attention.py
将它导入我们的环境:
1. from attention import AttentionLayer
导入库
1. import numpy as np
2. import pandas as pd
3. import re
4. from bs4 import BeautifulSoup
5. from keras.preprocessing.text import Tokenizer
6. from keras.preprocessing.sequence import pad_sequences
7. from nltk.corpus import stopwords
8. from tensorflow.keras.layers import Input, LSTM, Embedding, Dense, Concatenate, TimeDistributed, Bidirectional
9. from tensorflow.keras.models import Model
10. from tensorflow.keras.callbacks import EarlyStopping
11. import warnings
12. pd.set_option("display.max_colwidth", 200)
13. warnings.filterwarnings("ignore")
读取数据集
该数据集包括亚马逊美食的评论。 这些数据涵盖了超过10年的时间,截至2012年10月的所有约500,000条评论。这些评论包括产品和用户信息,评级,纯文本评论和摘要。它还包括来自所有其他亚马逊类别的评论。
我们将抽样出100,000个评论,以缩短模型的训练时间。如果你的机器具有强大的计算能力,也可以使用整个数据集来训练模型。
1. data=pd.read_csv("../input/amazon-fine-food-reviews/Reviews.csv",nrows=100000)
删除重复项和NA值
1. data.drop_duplicates(subset=['Text'],inplace=True) #dropping duplicates
2. data.dropna(axis=0,inplace=True) #dropping na
预处理
在我们进入模型构建部分之前,执行基本的预处理步骤非常重要。使用脏乱和未清理的文本数据是一个潜在的灾难性举措。因此,在此步骤中,我们将从文本中删除不影响问题目标的所有不需要的符号,字符等。
这是我们用于扩展缩略形式的字典:
1. contraction_mapping = {"ain't": "is not", "aren't": "are not","can't": "cannot", "'cause": "because", "could've": "could have", "couldn't": "could not",
2.
3. "didn't": "did not", "doesn't": "does not", "don't": "do not", "hadn't": "had not", "hasn't": "has not", "haven't": "have not",
4.
5. "he'd": "he would","he'll": "he will", "he's": "he is", "how'd": "how did", "how'd'y": "how do you", "how'll": "how will", "how's": "how is",
6.
7. "I'd": "I would", "I'd've": "I would have", "I'll": "I will", "I'll've": "I will have","I'm": "I am", "I've": "I have", "i'd": "i would",
8.
9. "i'd've": "i would have", "i'll": "i will", "i'll've": "i will have","i'm": "i am", "i've": "i have", "isn't": "is not", "it'd": "it would",
10.
11. "it'd've": "it would have", "it'll": "it will", "it'll've": "it will have","it's": "it is", "let's": "let us", "ma'am": "madam",
12.
13. "mayn't": "may not", "might've": "might have","mightn't": "might not","mightn't've": "might not have", "must've": "must have",
14.
15. "mustn't": "must not", "mustn't've": "must not have", "needn't": "need not", "needn't've": "need not have","o'clock": "of the clock",
16.
17. "oughtn't": "ought not", "oughtn't've": "ought not have", "shan't": "shall not", "sha'n't": "shall not", "shan't've": "shall not have",
18.
19. "she'd": "she would", "she'd've": "she would have", "she'll": "she will", "she'll've": "she will have", "she's": "she is",
20.
21. "should've": "should have", "shouldn't": "should not", "shouldn't've": "should not have", "so've": "so have","so's": "so as",
22.
23. "this's": "this is","that'd": "that would", "that'd've": "that would have", "that's": "that is", "there'd": "there would",
24.
25. "there'd've": "there would have", "there's": "there is", "here's": "here is","they'd": "they would", "they'd've": "they would have",
26.
27. "they'll": "they will", "they'll've": "they will have", "they're": "they are", "they've": "they have", "to've": "to have",
28.
29. "wasn't": "was not", "we'd": "we would", "we'd've": "we would have", "we'll": "we will", "we'll've": "we will have", "we're": "we are",
30.
31. "we've": "we have", "weren't": "were not", "what'll": "what will", "what'll've": "what will have", "what're": "what are",
32.
33. "what's": "what is", "what've": "what have", "when's": "when is", "when've": "when have", "where'd": "where did", "where's": "where is",
34.
35. "where've": "where have", "who'll": "who will", "who'll've": "who will have", "who's": "who is", "who've": "who have",
36.
37. "why's": "why is", "why've": "why have", "will've": "will have", "won't": "will not", "won't've": "will not have",
38.
39. "would've": "would have", "wouldn't": "would not", "wouldn't've": "would not have", "y'all": "you all",
40.
41. "y'all'd": "you all would","y'all'd've": "you all would have","y'all're": "you all are","y'all've": "you all have",
42.
43. "you'd": "you would", "you'd've": "you would have", "you'll": "you will", "you'll've": "you will have",
44.
45. "you're": "you are", "you've": "you have"}
我们需要定义两个不同的函数来预处理评论并生成摘要,因为文本和摘要中涉及的预处理步骤略有不同。
a)文字清理
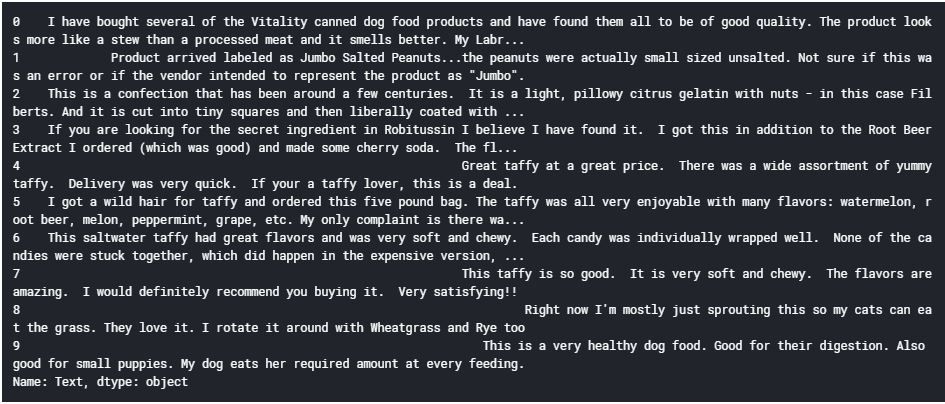
让我们看一下数据集中的前10个评论,以了解该如何进行文本预处理步骤:
1. data['Text'][:10]
输出:
我们将为我们的数据执行以下预处理任务:
将所有内容转换为小写
删除HTML标签
缩略形式映射
删除('s)
删除括号内的任何文本()
消除标点符号和特殊字符
删除停用词
删除简短的单词
让我们定义一下这个函数:
1. stop_words = set(stopwords.words('english'))
2. def text_cleaner(text):
3. newString = text.lower()
4. newString = BeautifulSoup(newString, "lxml").text
5. newString = re.sub(r'\([^)]*\)', '', newString)
6. newString = re.sub('"','', newString)
7. newString = ' '.join([contraction_mapping[t] if t in contraction_mapping else t for t in newString.split(" ")])
8. newString = re.sub(r"'s\b","",newString)
9. newString = re.sub("[^a-zA-Z]", " ", newString)
10. tokens = [w for w in newString.split() if not w in stop_words]
11. long_words=[]
12. for i in tokens:
13. if len(i)>=3: #removing short word
14. long_words.append(i)
15. return (" ".join(long_words)).strip()
16.
17. cleaned_text = []
18. for t in data['Text']:
19. cleaned_text.append(text_cleaner(t))
b)摘要清理
现在,我们将查看前10行评论,以了解摘要列的预处理步骤:
1. data['Summary'][:10]
输出:
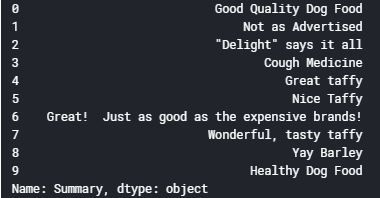
定义此任务的函数:
1. def summary_cleaner(text):
2. newString = re.sub('"','', text)
3. newString = ' '.join([contraction_mapping[t] if t in contraction_mapping else t for t in newString.split(" ")])
4. newString = re.sub(r"'s\b","",newString)
5. newString = re.sub("[^a-zA-Z]", " ", newString)
6. newString = newString.lower()
7. tokens=newString.split()
8. newString=''
9. for i in tokens:
10. if len(i)>1:
11. newString=newString+i+' '
12. return newString
13.
14. #Call the above function
15. cleaned_summary = []
16. for t in data['Summary']:
17. cleaned_summary.append(summary_cleaner(t))
18.
19. data['cleaned_text']=cleaned_text
20. data['cleaned_summary']=cleaned_summary
21. data['cleaned_summary'].replace('', np.nan, inplace=True)
22. data.dropna(axis=0,inplace=True)
请记住在摘要的开头和结尾添加START和END特殊标记:
1. data['cleaned_summary'] = data['cleaned_summary'].apply(lambda x : '_START_ '+ x + ' _END_')
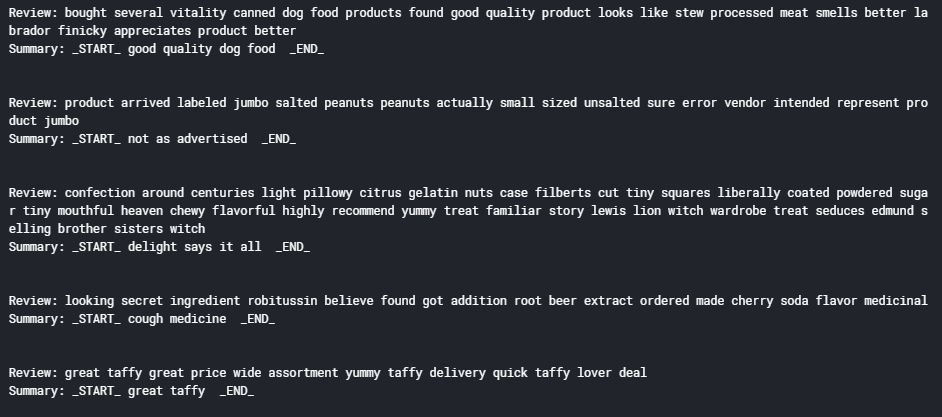
现在,我们来看看前5个评论及其摘要:
1. for i in range(5):
2. print("Review:",data['cleaned_text'][i])
3. print("Summary:",data['cleaned_summary'][i])
4. print("\n")
输出:
了解序列的分布
在这里,我们将分析评论和摘要的长度,以全面了解文本长度的分布。这将帮助我们确定序列的最大长度:
1. import matplotlib.pyplot as plt
2. text_word_count = []
3. summary_word_count = []
4.
5. # populate the lists with sentence lengths
6. for i in data['cleaned_text']:
7. text_word_count.append(len(i.split()))
8.
9. for i in data['cleaned_summary']:
10. summary_word_count.append(len(i.split()))
11.
12. length_df = pd.DataFrame({'text':text_word_count, 'summary':summary_word_count})
13. length_df.hist(bins = 30)
14. plt.show()
输出:
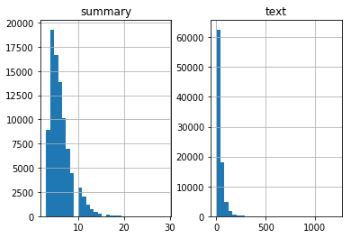
有趣。我们可以将评论的最大长度固定为80,因为这似乎是多数评论的长度。同样,我们可以将最大摘要长度设置为10:
1. max_len_text=80
2. max_len_summary=10
我们越来越接近模型的构建部分了。在此之前,我们需要将数据集拆分为训练和验证集。我们将使用90%的数据集作为训练数据,并在其余10%上评估(保留集)表现:
1. from sklearn.model_selection import train_test_split
2. x_tr,x_val,y_tr,y_val=train_test_split(data['cleaned_text'],data['cleaned_summary'],test_size=0.1,random_state=0,shuffle=True)
准备分词器(Tokenizer)
分词器构建词汇表并将单词序列转换为整数序列。继续为文本和摘要构建分词器:
a) 文本分词器
b) #prepare a tokenizer for reviews on training data
c) x_tokenizer = Tokenizer()
d) x_tokenizer.fit_on_texts(list(x_tr))
e)
f) #convert text sequences into integer sequences
g) x_tr = x_tokenizer.texts_to_sequences(x_tr)
h) x_val = x_tokenizer.texts_to_sequences(x_val)
i)
j) #padding zero upto maximum length
k) x_tr = pad_sequences(x_tr, maxlen=max_len_text, padding='post')
l) x_val = pad_sequences(x_val, maxlen=max_len_text, padding='post')
m)
n) x_voc_size = len(x_tokenizer.word_index) +1
b)摘要分词器
1. #preparing a tokenizer for summary on training data
2. y_tokenizer = Tokenizer()
3. y_tokenizer.fit_on_texts(list(y_tr))
4.
5. #convert summary sequences into integer sequences
6. y_tr = y_tokenizer.texts_to_sequences(y_tr)
7. y_val = y_tokenizer.texts_to_sequences(y_val)
8.
9. #padding zero upto maximum length
10. y_tr = pad_sequences(y_tr, maxlen=max_len_summary, padding='post')
11. y_val = pad_sequences(y_val, maxlen=max_len_summary, padding='post')
12.
13. y_voc_size = len(y_tokenizer.word_index) +1
模型构建
终于来到了模型构建的部分。但在构建之前,我们需要熟悉所需的一些术语。
Return Sequences = True:当return sequences参数设置为True时,LSTM为每个时间步生成隐藏状态和单元状态
Return State = True:当return state = True时,LSTM仅生成最后一个时间步的隐藏状态和单元状态
Initial State:用于在第一个时间步初始化LSTM的内部状态
Stacked LSTM:Stacked LSTM具有多层LSTM堆叠在彼此之上。这能产生更好地序列表示。我鼓励你尝试将LSTM的多个层堆叠在一起(这是一个很好的学习方法)
在这里,我们为编码器构建一个3层堆叠LSTM:
1. from keras import backend as K
2. K.clear_session()
3. latent_dim = 500
4.
5. # Encoder
6. encoder_inputs = Input(shape=(max_len_text,))
7. enc_emb = Embedding(x_voc_size, latent_dim,trainable=True)(encoder_inputs)
8.
9. #LSTM 1
10. encoder_lstm1 = LSTM(latent_dim,return_sequences=True,return_state=True)
11. encoder_output1, state_h1, state_c1 = encoder_lstm1(enc_emb)
12.
13. #LSTM 2
14. encoder_lstm2 = LSTM(latent_dim,return_sequences=True,return_state=True)
15. encoder_output2, state_h2, state_c2 = encoder_lstm2(encoder_output1)
16.
17. #LSTM 3
18. encoder_lstm3=LSTM(latent_dim, return_state=True, return_sequences=True)
19. encoder_outputs, state_h, state_c= encoder_lstm3(encoder_output2)
20.
21. # Set up the decoder.
22. decoder_inputs = Input(shape=(None,))
23. dec_emb_layer = Embedding(y_voc_size, latent_dim,trainable=True)
24. dec_emb = dec_emb_layer(decoder_inputs)
25.
26. #LSTM using encoder_states as initial state
27. decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True)
28. decoder_outputs,decoder_fwd_state, decoder_back_state = decoder_lstm(dec_emb,initial_state=[state_h, state_c])
29.
30. #Attention Layer
31. Attention layer attn_layer = AttentionLayer(name='attention_layer')
32. attn_out, attn_states = attn_layer([encoder_outputs, decoder_outputs])
33.
34. # Concat attention output and decoder LSTM output
35. decoder_concat_input = Concatenate(axis=-1, name='concat_layer')([decoder_outputs, attn_out])
36.
37. #Dense layer
38. decoder_dense = TimeDistributed(Dense(y_voc_size, activation='softmax'))
39. decoder_outputs = decoder_dense(decoder_concat_input)
40.
41. # Define the model
42. model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
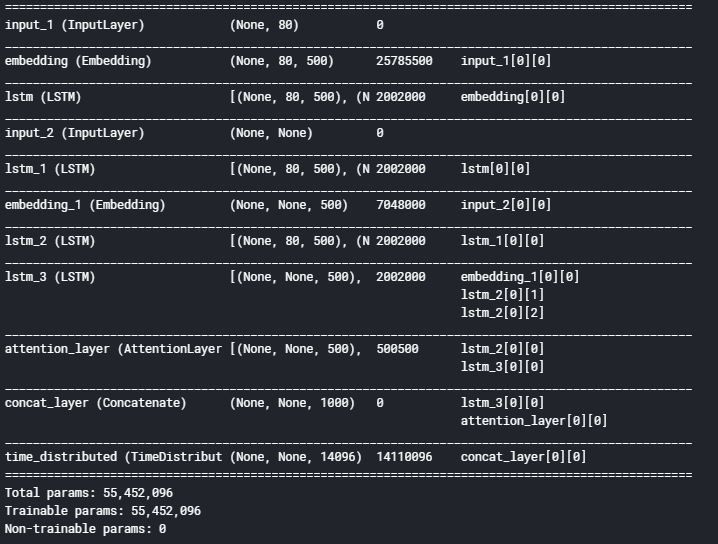
43. model.summary()
输出:
我使用sparse categorical cross-entropy作为损失函数,因为它在运行中将整数序列转换为独热(one-hot)向量。这克服了任何内存问题。
1. model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy')
还记得early stopping的概念吗?它用于通过监视用户指定的度量标准,在适当的时间停止训练神经网络。在这里,我监视验证集损失(val_loss)。一旦验证集损失反弹,我们的模型就会停止训练:
1. es = EarlyStopping(monitor='val_loss', mode='min', verbose=1)
我们将在批量大小为512的情况下训练模型,并在保留集(我们数据集的10%)上验证它:
1. history=model.fit([x_tr,y_tr[:,:-1]], y_tr.reshape(y_tr.shape[0],y_tr.shape[1], 1)[:,1:] ,epochs=50,callbacks=[es],batch_size=512, validation_data=([x_val,y_val[:,:-1]], y_val.reshape(y_val.shape[0],y_val.shape[1], 1)[:,1:]))
了解诊断图
现在,我们将绘制一些诊断图来了解模型随时间的变化情况:
1. from matplotlib import pyplot
2. pyplot.plot(history.history['loss'], label='train')
3. pyplot.plot(history.history['val_loss'], label='test')
4. pyplot.legend() pyplot.show()
输出:
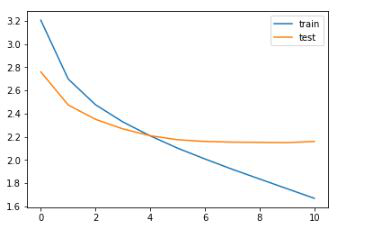
我们可以推断,在第10个周期(epoch)之后,验证集损失略有增加。因此,我们将在此之后停止训练模型。
接下来,让我们构建字典,将目标和源词汇表中的索引转换为单词:
1. reverse_target_word_index=y_tokenizer.index_word
2. reverse_source_word_index=x_tokenizer.index_word
3. target_word_index=y_tokenizer.word_index
推理
设置编码器和解码器的推理:
1. # encoder inference
2. encoder_model = Model(inputs=encoder_inputs,outputs=[encoder_outputs, state_h, state_c])
3.
4. # decoder inference
5. # Below tensors will hold the states of the previous time step
6. decoder_state_input_h = Input(shape=(latent_dim,))
7. decoder_state_input_c = Input(shape=(latent_dim,))
8. decoder_hidden_state_input = Input(shape=(max_len_text,latent_dim))
9.
10. # Get the embeddings of the decoder sequence
11. dec_emb2= dec_emb_layer(decoder_inputs)
12.
13. # To predict the next word in the sequence, set the initial states to the states from the previous time step
14. decoder_outputs2, state_h2, state_c2 = decoder_lstm(dec_emb2, initial_state=[decoder_state_input_h, decoder_state_input_c])
15.
16. #attention inference
17. attn_out_inf, attn_states_inf = attn_layer([decoder_hidden_state_input, decoder_outputs2])
18. decoder_inf_concat = Concatenate(axis=-1, name='concat')([decoder_outputs2, attn_out_inf])
19.
20. # A dense softmax layer to generate prob dist. over the target vocabulary
21. decoder_outputs2 = decoder_dense(decoder_inf_concat)
22.
23. # Final decoder model
24. decoder_model = Model(
25. [decoder_inputs] + [decoder_hidden_state_input,decoder_state_input_h, decoder_state_input_c],
26. [decoder_outputs2] + [state_h2, state_c2])
下面我们定义了一个函数,是推理过程的实现(我们在上一节中介绍过):
1. def decode_sequence(input_seq):
2. # Encode the input as state vectors.
3. e_out, e_h, e_c = encoder_model.predict(input_seq)
4.
5. # Generate empty target sequence of length 1.
6. target_seq = np.zeros((1,1))
7.
8. # Chose the 'start' word as the first word of the target sequence
9. target_seq[0, 0] = target_word_index['start']
10.
11. stop_condition = False
12. decoded_sentence = ''
13. while not stop_condition:
14. output_tokens, h, c = decoder_model.predict([target_seq] + [e_out, e_h, e_c])
15.
16. # Sample a token
17. sampled_token_index = np.argmax(output_tokens[0, -1, :])
18. sampled_token = reverse_target_word_index[sampled_token_index]
19.
20. if(sampled_token!='end'):
21. decoded_sentence += ' '+sampled_token
22.
23. # Exit condition: either hit max length or find stop word.
24. if (sampled_token == 'end' or len(decoded_sentence.split()) >= (max_len_summary-1)):
25. stop_condition = True
26.
27. # Update the target sequence (of length 1).
28. target_seq = np.zeros((1,1))
29. target_seq[0, 0] = sampled_token_index
30.
31. # Update internal states
32. e_h, e_c = h, c
33.
34. return decoded_sentence
我们来定义函数,用于将摘要和评论中的整数序列转换为单词序列:
1. def seq2summary(input_seq):
2. newString=''
3. for i in input_seq:
4. if((i!=0 and i!=target_word_index['start']) and i!=target_word_index['end']):
5. newString=newString+reverse_target_word_index[i]+' '
6. return newString
7.
8. def seq2text(input_seq):
9. newString=''
10. for i in input_seq:
11. if(i!=0):
12. newString=newString+reverse_source_word_index[i]+' '
13. return newString
1. for i in range(len(x_val)):
2. print("Review:",seq2text(x_val[i]))
3. print("Original summary:",seq2summary(y_val[i]))
4. print("Predicted summary:",decode_sequence(x_val[i].reshape(1,max_len_text)))
5. print("\n")
以下是该模型生成的一些摘要:





这真的很酷。即使我们模型生成的摘要和实际摘要并不完全匹配,但它们都传达了相同的含义。我们的模型能够根据文本中的上下文生成清晰的摘要。
以上就是我们如何使用Python中的深度学习概念执行文本摘要。
我们如何进一步提高模型的性能?
你的学习并不止于此!你可以做更多的事情来尝试模型:
我建议你增加训练数据集大小并构建模型。随着训练数据集大小的增加,深度学习模型的泛化能力增强
尝试实现双向LSTM,它能够从两个方向捕获上下文,并产生更好的上下文向量
使用集束搜索策略(beam search strategy)解码测试序列而不是使用贪婪方法(argmax)
根据BLEU分数评估模型的性能
实现pointer-generator网络和覆盖机制
8. 注意力机制如何运作?
现在,我们来谈谈注意力机制的内部运作原理。正如我在文章开头提到的那样,这是一个数学密集的部分,所以将其视为可选部分。不过我仍然强烈建议通读来真正掌握注意力机制的运作方式。
编码器输出源序列中每个时间步j的隐藏状态(hj)。
类似地,解码器输出目标序列中每个时间步i的隐藏状态(si)。
我们计算一个被称为对齐分数(eij)的分数,基于该分数,源词与目标词对齐。使用得分函数从源隐藏状态hj和目标隐藏状态si计算对齐得分。由下面公式给出:
eij =score(si,hj)
其中eij表示目标时间步i和源时间步j的对齐分数。
根据所使用评分函数的类型,存在不同类型的注意力机制。我在下面提到了一些流行的注意力机制:

我们使用softmax函数标准化对齐分数以获得注意力权重(aij):
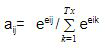
我们计算注意力权重aij和编码器hj的隐藏状态的乘积的线性和,以产生参与的上下文向量(Ci):
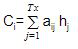
将参与的上下文向量和在时间步长i处的解码器的目标隐藏状态连接以产生参与的隐藏向量Si;
Si= concatenate([si; Ci])
然后将参与的隐藏向量Si送入dense层以产生yi;
yi= dense(Si)
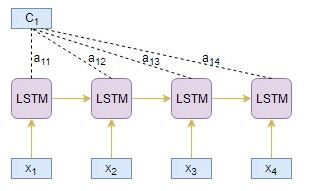
让我们借助一个例子来理解上面的注意力机制步骤。 将源序列视为[x1,x2,x3,x4],将目标序列视为[y1,y2]。
编码器读取整个源序列并输出每个时间步的隐藏状态,如h1,h2,h3,h4
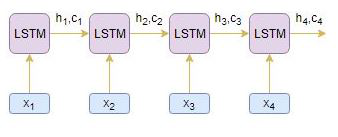
解码器读取偏移一个时间步的整个目标序列,并输出每个时间步的隐藏状态,如s1,s2,s3
目标时间步i = 1
使用得分函数从源隐藏状态hi和目标隐藏状态s1计算对齐得分e1j:
e11= score(s1, h1)
e12= score(s1, h2)
e13= score(s1, h3)
e14= score(s1, h4)
使用softmax标准化对齐分数e1j会产生注意力权重a1j:
a11= exp(e11)/((exp(e11)+exp(e12)+exp(e13)+exp(e14))
a12= exp(e12)/(exp(e11)+exp(e12)+exp(e13)+exp(e14))
a13= exp(e13)/(exp(e11)+exp(e12)+exp(e13)+exp(e14))
a14= exp(e14)/(exp(e11)+exp(e12)+exp(e13)+exp(e14))
参与的上下文向量C1由编码器隐藏状态hj和对齐分数a1j的乘积的线性和导出:
C1= h1 * a11 + h2 * a12 + h3 * a13 + h4 * a14
将参与的上下文向量C1和目标隐藏状态s1连接以产生参与的隐藏向量S1
S11= concatenate([s11; C1])
然后将隐藏向量S1送到全连接层中以产生y1
y1= dense(S1)
目标时间步i = 2
使用给出的得分函数从源隐藏状态hi和目标隐藏状态s2计算对齐分数e2j
e21= score(s2, h1)
e22= score(s2, h2)
e23= score(s2, h3)
e24= score(s2, h4)
使用softmax标准化对齐分数e2j会产生注意力权重a2j:
a21= exp(e21)/(exp(e21)+exp(e22)+exp(e23)+exp(e24))
a22= exp(e22)/(exp(e21)+exp(e22)+exp(e23)+exp(e24))
a23= exp(e23)/(exp(e21)+exp(e22)+exp(e23)+exp(e24))
a24= exp(e24)/(exp(e21)+exp(e22)+exp(e23)+exp(e24))
参与的上下文向量C2由编码器隐藏状态hi和对齐分数a2j的乘积的线性和导出:
C2= h1 * a21 + h2 * a22 + h3 * a23 + h4 * a24
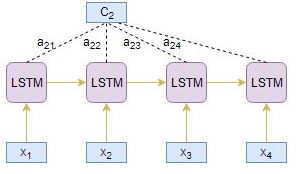
将参与的上下文向量C2和目标隐藏状态s2连接以产生参与的隐藏向量S2
S2= concatenate([s22; C22])
然后将隐藏向量S2送到全连接层中以产生y2
y2= dense(S2)
我们可以对目标时间步i = 3执行类似的步骤以产生y3。
我知道这部分数学和理论有点多,但理解这一点将帮助你掌握注意力机制背后的基本思想。它已经催生了NLP最近的许多发展,现在轮到你了!
代码
请在这里找到整个notebook。
https://github.com/aravindpai/How-to-build-own-text-summarizer-using-deep-learning/blob/master/How_to_build_own_text_summarizer_using_deep_learning.ipynb
结语
深吸一口气,我们在本文中介绍了很多内容。并祝贺你使用深度学习构建了第一个文本摘要模型!我们已经了解了如何使用Python中的Seq2Seq构建自己的文本摘要生成器。
如果你对本文有任何反馈意见或任何疑问,请在下面的评论部分分享,我会尽快回复。确保你尝试了我们在此建立的模型,并与社区分享你的模型结果!
你还可以参加以下课程来学习或提高NLP技能:
Natural Language Processing (NLP) using Python
https://courses.analyticsvidhya.com/courses/natural-language-processing-nlp?utm_source=blog&utm_medium=comprehensive-guide-text-summarization-using-deep-learning-python
Introduction to Natural Language Processing (NLP)
https://courses.analyticsvidhya.com/courses/Intro-to-NLP?utm_source=blog&utm_medium=comprehensive-guide-text-summarization-using-deep-learning-python
您还可以在Analytics Vidhya的Android APP上阅读这篇文章。
原文标题:
Comprehensive Guide to Text Summarization using Deep Learning in Python
原文链接:
https://www.analyticsvidhya.com/blog/2019/06/comprehensive-guide-text-summarization-using-deep-learning-python/
编辑:王菁
校对:林亦霖
译者简介

和中华,留德软件工程硕士。由于对机器学习感兴趣,硕士论文选择了利用遗传算法思想改进传统kmeans。目前在杭州进行大数据相关实践。加入数据派THU希望为IT同行们尽自己一份绵薄之力,也希望结交许多志趣相投的小伙伴。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

点击“阅读原文”拥抱组织




