独家 | 一文读懂深度学习(附学习资源)

原文标题:Want to know how Deep Learning works? Here’s a quick guide for everyone
作者:Radu Raicea
翻译:程思衍
校对:冯羽
本文长度为2500字,建议阅读6分钟
Medium上获得超过一万五千赞的深度学习入门指南,结合图文为你缕清深度学习中的各个基础概念的内涵。
人工智能(AI)
(https://en.wikipedia.org/wiki/Artificial_intelligence)
和机器学习(ML)
(https://en.wikipedia.org/wiki/Machine_learning)
都属于目前最热门的话题。
在日常生活中,AI这个术语我们随处可见。你或许会从立志高远的开发者哪那里听说她(他)们想要学习AI。你又或许会从运营者那里听到他们想要在他们的的服务中实施AI。但往往这些人中的绝大多数都并不明白什么是AI。
在你阅读完这篇文章之后,你将会了解AI和ML的基本知识。而更重要的是,你将会明白深度学习(https://en.wikipedia.org/wiki/Deep_learning),这类最热门的机器学习,是如何运作的。
这篇教程适用于所有人,所以本文并没有涉及高级数学。
背景
理解深度学习如何工作的第一步是掌握下列重要术语之间的区别。
人工智能(AI)v.s.机器学习(ML)
人工智能是人类智能在计算机上的复制。
AI的研究之初,那时的研究人员尝试着复制人类智能来完成像玩游戏这样特定的任务。
他们引入了大量的计算机需要遵守的规则。有了这些规则,计算机就有了一份包含各种可能行动的清单,并基于这些规则作出决定(https://en.wikipedia.org/wiki/Expert_system)。
机器学习,指的是机器使用大量数据集而非硬编码规则来进行学习的能力。
ML允许计算机通过自身来学习。这种学习方法得益于现代计算机的强大性能,性能保证了计算机能够轻松处理样本数巨大的数据集。
监督学习 v.s. 非监督学习
监督学习
(https://en.wikipedia.org/wiki/Supervised_learning)
指的是利用已标注数据集进行的学习,该数据中包含输入和期望输出。
当你利用监督学习来训练AI时,你提供给它一份输入,并告诉它预期的输出。
如果AI所生成的输出是错误的(译者注:与期望输出不同),它将重新调整计算(注:应该是对公式的参数进行重新计算)。这个过程将会在数据集上迭代运行,直到AI不再犯错误。
预测天气的AI便是监督学习的一个典型例子。它通过学习过往数据来预测未来天气。该训练数据拥有输入(气压,湿度,风速)和输出(温度)。
非监督学习
(https://en.wikipedia.org/wiki/Unsupervised_learning)
是机器学习应用没有指定结构的数据集来进行学习的任务。
当你应用非监督学习来训练AI时,你可以让AI对数据进行逻辑分类。
电商网站上的行为预测AI便是非监督学习的一个例子。它无法通过拥有输入和输出的已标注数据集来进行学习。相反地,它在输入数据上创建它自己的分类。它将会告诉你哪一种用户最可能购买差异化的商品。
深度学习又是如何运作的呢?
现在你已经准备好去理解什么是深度学习,以及它是如何运作的。
深度学习是机器学习中的一种方法。在给予它一组输入后,它使我们能够训练AI来预测结果。监督学习和非监督学习都能够用来训练AI。
我们将通过建立一个假设的机票价格预估系统来阐述深度学习是如何运作的。我们将应用监督学习方法来训练它。
我们想要该机票价格预估系统基于下列输入来进行预测(为了简洁,我们除去了返程机票):
起飞机场
到达机场
起飞日期
航空公司
神经网络
接下来我们将视角转向我们的AI的大脑内部。
和动物一样,我们预估系统AI的大脑中有神经元。将它们用圆圈表示。这些神经元在内部都是相互连接的。
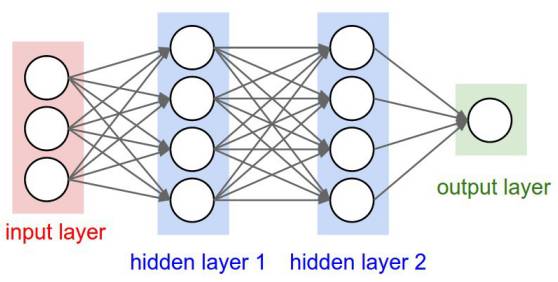
这些神经元又被分为三种层次:
输入层
隐藏层
输出层
输入层接收输入数据。在本案例中,在输入层中有4个神经元:起飞机场,到达机场,起飞日期以及航空公司。输入层将输入传递给第一个隐藏层。
隐藏层针对我们的输入进行数学运算。创建神经网络的一大难点便是决定隐藏层的层数,以及每层中神经元的个数。
深度学习中的“深度”所指的是拥有多于一层的隐藏层。
输出层返回的是输出数据。在本案例中,输出层返回的是价格预测。
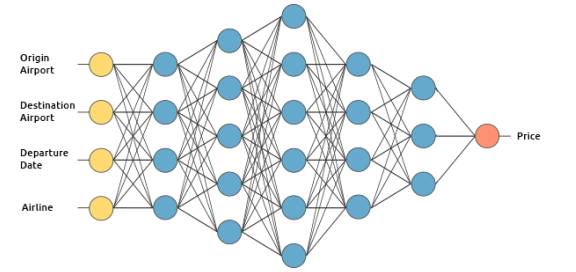
那么它到底是如何来运算价格预测的呢?
这便是我们将要揭晓的深度学习的奇妙之处了。
每两个神经元之间的连接,都对应着一个权重。该权重决定了输入值的重要程度。初始的权重会被随机设定。
当预测机票价格时,起飞日期是决定价格的最重要的因素之一。因此,与起飞日期这个神经元相连的连接将会有更高的权重。
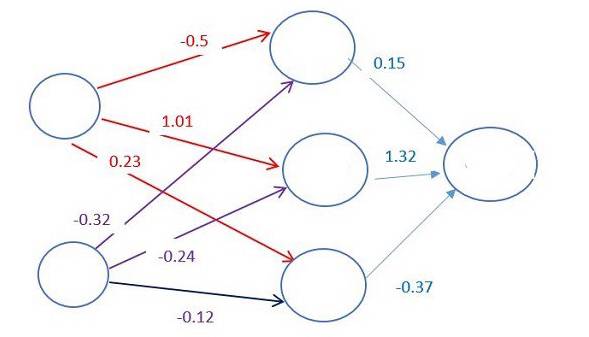
Image credit: CodeProject
每个神经元都有一个激活函数(https://en.wikipedia.org/wiki/Activation_function)。若没有数学推导,这些函数十分晦涩难懂。
简而言之,激活函数的作用之一便是将神经元的结果“标准化”。
一旦一组输入数据通过了神经网络的所有层,神经网络将会通过输出层返回输出数据。
一点也不复杂,是吧?
训练神经网络
训练AI是深度学习中最难的部分了。这又是为什么呢?
你需要一个庞大的数据集
你还需要强大的算力
对于我们的机票价格预估系统,我们需要得到过往的票价数据。由于起始机场和起飞时间拥有大量可能的组合,所以我们需要的是一个非常庞大的票价列表。
为了训练机票价格预估系统的AI,我们需要将数据集的数据给予该系统,然后将它输出的结果与数据集的输出进行比对。因为此时AI仍然没有受过训练,所以它的输出将会是错误的。
一旦我们遍历完了整个数据集,我们便能创造出一个函数,该函数告诉我们AI的输出和真实输出到底相差多少。这个函数我们称为损失函数。
在理想情况下,我们希望我们的损失函数为0,该理想情况指的是AI的输出和数据集的输出相等之时。
如何减小损失函数呢?
改变神经元之间的权重。我们可以随机地改变这些权重直到损失函数足够小,但是这种方法并不够高效。
取而代之地,我们应用一种叫做梯度下降(https://en.wikipedia.org/wiki/Gradient_descent)的技巧。
梯度下降是一种帮助我们找到函数最小值的技巧。在本案例中,我们寻找损失函数的最小值。
在每次数据集迭代之后,该方法以小增量的方式改变权重。通过计算损失函数在一组确定的权重集合上的导数(梯度),我们便能够知悉最小值在哪个方向。
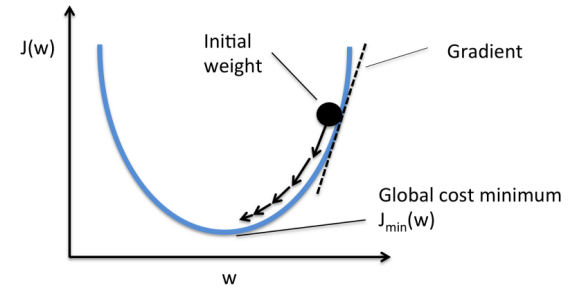
为了最小化损失函数,你需要多次迭代数据集。这便是需要高算力的原因了。
利用梯度下降更新权重的过程是自动进行的。这便是深度学习的魔力所在!
一旦我们训练好机票价格预估的AI之后,我们便能够用它来预测未来的价格了。
拓展阅读
神经网络有非常多的种类:用于计算机视觉(https://en.wikipedia.org/wiki/Computer_vision)的卷积神经网络(https://en.wikipedia.org/wiki/Convolutional_neural_network)以及应用于自然语言处理(https://en.wikipedia.org/wiki/Natural_language_processing)的循环神经网络(https://en.wikipedia.org/wiki/Recurrent_neural_network)。
如果你想要学习深度学习的技术细节,我建议你参加一个在线课程。
吴恩达(https://medium.com/@andrewng)的深度学习专项课程(https://www.coursera.org/specializations/deep-learning)是当下最好的深度学习课程之一。如果你并不需要一个证书,你便可以免费旁听这门课程。
小结
1. 深度学习应用神经网络来模仿动物智能。
2. 神经网络中有三个层次的神经元:输入层、隐藏层以及输出层。
3. 神经元之间的连接对应一个权重,该权重决定了各输入数据的重要程度。
4. 神经元中应用一个激活函数来“标准化”神经元输出的数据。
5. 你需要一个庞大的数据集来训练神经网络。
6. 在数据集上迭代并与输出结果相比较,我们将会得到一个损失函数,损失函数能告诉我们AI生成的结果和真实结果相差多少。
7. 在每次数据集的迭代之后,都会利用梯度下降方法调整神经元之间的权重,以减小损失函数。
原文链接:
https://medium.freecodecamp.org/want-to-know-how-deep-learning-works-heres-a-quick-guide-for-everyone-1aedeca88076

程思衍,本科毕业于北航计算机系,美国南加州大学 Data Informatics 专业在读硕士。曾进行过问答系统、机器学习预测、高并发等方面的开发,目前主要从事问答领域的学习和研究。
翻译组招募信息
工作内容:将选取好的外文前沿文章准确地翻译成流畅的中文。如果你是数据科学/统计学/计算机专业的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友,数据派翻译组欢迎你们加入!
你能得到:提高对于数据科学前沿的认知,提高对外文新闻来源渠道的认知,海外的朋友可以和国内技术应用发展保持联系,数据派团队产学研的背景为志愿者带来好的发展机遇。
其他福利:和来自于名企的数据科学工作者,北大清华以及海外等名校学生共同合作、交流。
点击文末“阅读原文”加入数据派团队~
为保证发文质量、树立口碑,数据派现设立“错别字基金”,鼓励读者积极纠错。
若您在阅读文章过程中发现任何错误,请在文末留言,或到后台反馈,经小编确认后,数据派将向检举读者发8.8元红包。
同一位读者指出同一篇文章多处错误,奖金不变。不同读者指出同一处错误,奖励第一位读者。
感谢一直以来您的关注和支持,希望您能够监督数据派产出更加高质的内容
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THUID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。


点击“阅读原文”加入组织~




