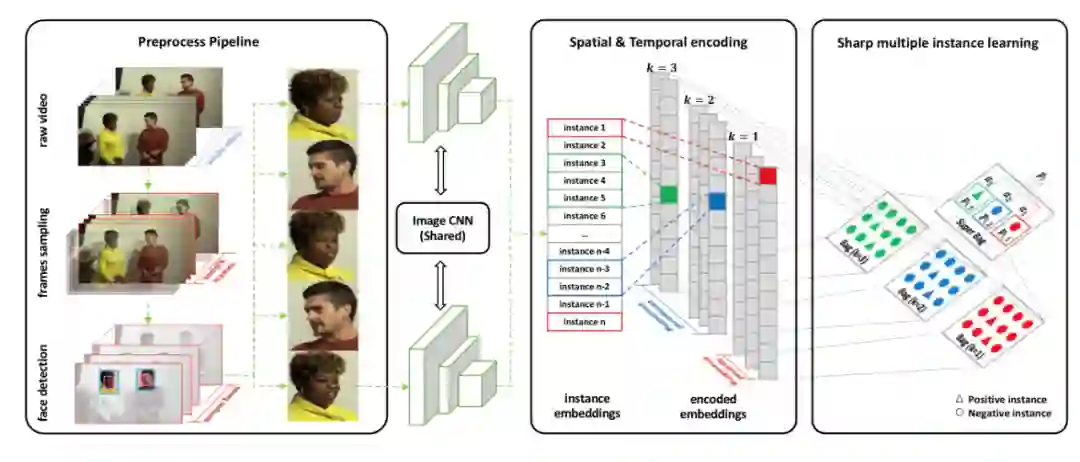
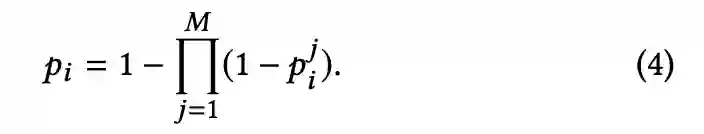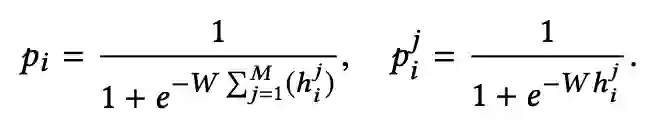近日,阿里安全图灵实验室和中科院计算所合作提出一种只需要视频级别标注的新型 DeepFake 视频检测方法,该方法更加关注现实中广泛存在的部分攻击(篡改)视频问题,能够从视频中准确识别出被篡改的人脸。
随着换脸技术的升级及相关应用的开源,换脸用途也从最初的娱乐逐渐演变成犯罪工具,对人们的名誉和社会的安定形成潜在的威胁。例如,今年 2 月份在德里议会选举的前一天,一个被 DeepFake 篡改过的政客讲话视频在 WhatsApp 上流传,对选举造成了极大的影响 [1];而在某成人视频网站上,某女星的脸被「安」在了成人视频女主角脸上,给女星的名誉带来了负面影响……
鉴于这项技术所带来的伦理问题和潜在威胁,先进的 DeepFake 检测技术是非常必要的。
在以前的研究中,DeepFake 视频检测主要专注于在具备强监督标注的情况下,如何较好地检测到 DeepFake 图像或者人脸。不同于之前的工作,阿里安全图灵实验室和中科院计算所合作完成的一项研究更加关注现实中广泛存在的问题:部分攻击(篡改)的视频,即视频中只有部分人脸被篡改了。
如下图所示,图 1 左图显示的是完全 DeepFake 攻击,其原图里仅有一张人脸被替换。而图 1 右图中有多张人脸,但只有红框中的人脸是被替换过的。
![]()
图 1:完全 DeepFake 攻击 [2] 和部分 DeepFake 攻击 [3]。(图片来源:YouTube)
目前的 DeepFake 检测工作主要分为两类:帧级检测 [4][5] 和视频级检测 [6]。
基于帧级的检测方法不仅需要成本较高的帧级别标注,在转化到视频级任务时,还需要设计巧妙的融合方法才能较好地将帧级预测转化为视频级预测。简单的平均值或者取最大值极易导致漏检或误检。
而之前基于视频级别的检测工作,比如 LSTM 等,在 DeepFake 视频检测时,过多专注于时序建模,导致 DeepFake 视频检测效果受到一定限制。
![]()
为了更好地检测部分篡改的 DeepFake 视频,阿里研究人员提出了一种只需要视频级别标注的新型 DeepFake 视频检测方法。
论文链接:https://arxiv.org/pdf/2008.04585.pdf
由于在视频检测任务中,人脸或帧级标注是缺失的,如果像基于帧级检测的方法那样,直接将视频标签当作每张人脸的标签,会引入训练噪声,训练很可能无法收敛。
回顾 DeepFake 视频的定义:只要视频中有一张人脸被篡改,那么该视频就被定义为 DeepFake 视频。这和多实例学习是吻合的。在多实例学习中,一个包由多个实例组成,只要其中有一个实例是正类,那么该包就是正类的,否则就是负类。
基于这个观察,该研究提出了基于多实例学习的 DeepFake 检测框架,将人脸和输入视频分别当作多实例学习 (Multiple Instance Learning, MIL) 里的实例和包进行检测。但是传统的多实例学习存在梯度消失问题 [7],为此,研究人员提出了 Sharp-MIL (S-MIL),将多个实例的聚合由输出层提前到特征层,一方面使得聚合更加灵活,另一方面也利用伪造检测的目标函数直接指导实例级深度表征的学习,从而缓解传统多实例学习面临的梯度消失难题。该研究通过理论证明了 S-MIL 可以缓解传统 MIL 存在的梯度消失问题。
![]()
其中,p_i 和 p^j_i 分别是第 i 个包及其包里第 j 个实例的正类概率,M 为包里的实例数。
![]()
其中 e 是网络参数,h^j_i 是包 i 中实例 j 对应的特征。
在实例设计上,与传统多实例学习的设定一样,该研究中实例与实例间是相互独立的。但由于 DeepFake 是单帧篡改的,这导致同一人脸在相邻帧上会有一些抖动,如图 3 所示。
![]()
图 3:DeepFake 篡改导致时序抖动示意图 [8]
于是,该研究设计了时空实例,用来刻画帧间一致性,辅助 DeepFake 检测。具体而言,研究人员使用文本分类里常用的 1-d 卷积,使用不同大小的核对输入的人脸序列从多视角上进行编码,从而得到时空实例,用于最终检测。
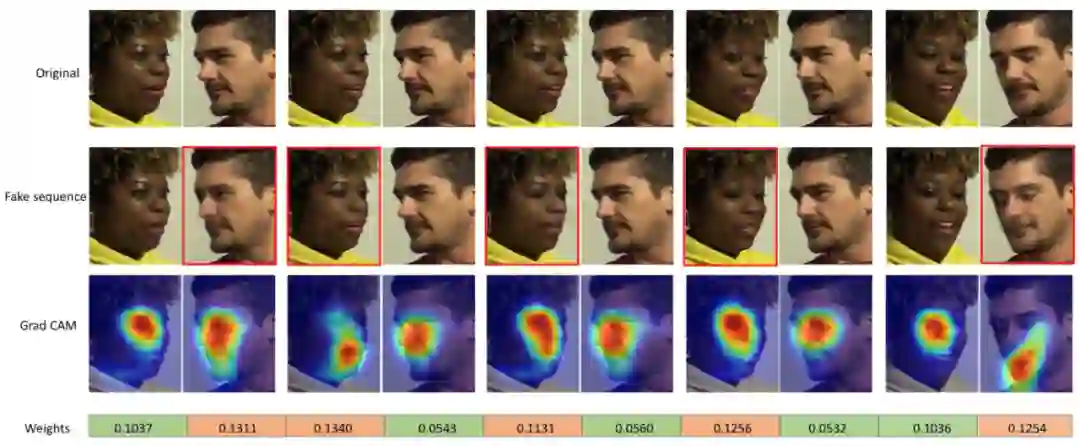
S-MIL 算法的最终检测效果图如下所示,从中可以看到,假脸的权重较高。这说明 S-MIL 方法在仅需视频级标签的情况下,可以很好地定位到假脸,且具有一定的可解释性。
![]()
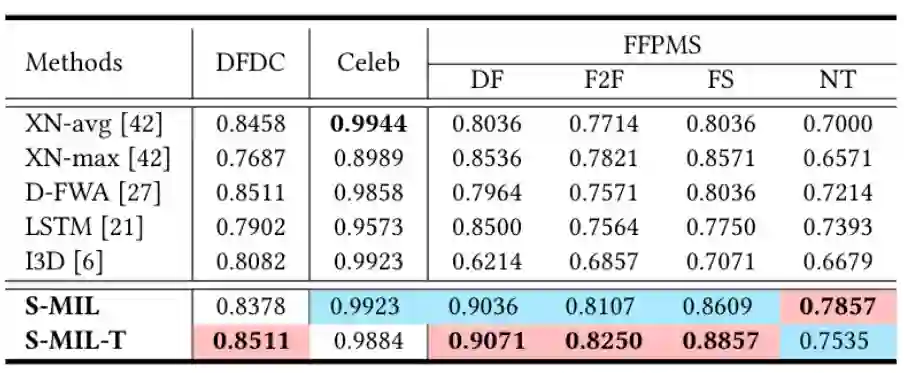
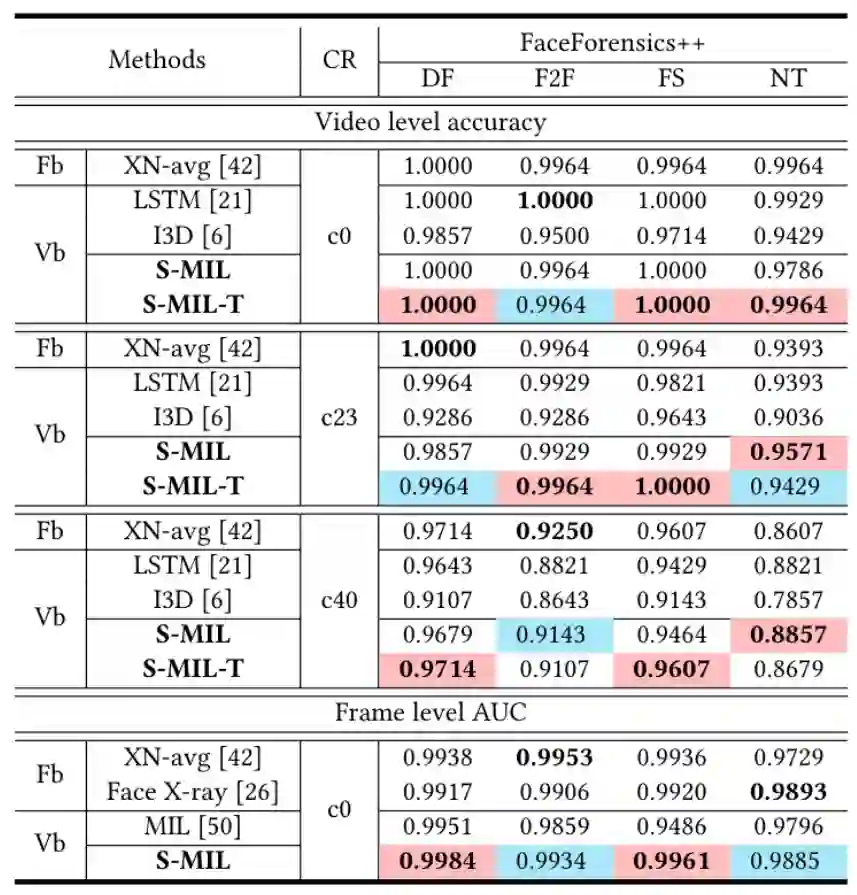
该算法在公开数据集上的表现如下图所示,从中可以看出,该方法在视频检测方面能到达到 state-of-the-art 的效果:
![]()
![]()
在上述技术革新下,阿里安全图灵实验室 DeepFake 检测技术在视频检测和帧级检测领域排名前列。该技术的共同研究者、中科院计算所副研究员王树徽认为,除了部分换脸检测任务之外,该研究成果对于一般性的视频多实例学习与标注技术研究也具有重要的启发意义。
今年 3 月,阿里发布新一代安全架构,致力于从源头防范安全威胁,构建安全体系,并打造数字基建安全样板间。DeepFake 检测技术作为新一代安全架构技术底座中的核心 AI 技术,对数字基建的安全建设起到重要作用,并成功实现落地应用。
阿里安全图灵实验室资深算法专家华棠介绍道:「虽然已有一些政策强制要求 DeepFake 视频在传播时必须标注属于 DeepFake 视频,但 DeepFake 视频一旦传播,对个人、对群体造成的伤害都是巨大的,所以要遏制源头。目前,我们已经将这个检测技术使用在内容安全场景中,后续也会在直播场景进行布局。」
目前,阿里已将基于小规模图像的高效学习框架技术应用在内容安全中,并赋能内外的多个业务场景,内部业务包括淘宝视频、淘宝直播和优酷;对外通过绿网对外进行商业化输出,服务外部的大中小客户。
[1] https://www.qbitai.com/2020/02/11740.html
[2] https://www.youtube.com/watch?v=I5rLi7FXIe8&t=95s
[3] https://www.youtube.com/watch?v=BU9YAHigNx8
[4] Andreas Rossler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, and Matthias Niesner. 2019. Faceforensics++: Learning to detect manipulated 998 facial images. In arXiv preprint arXiv:1901.08971.
[5] Lingzhi Li, Jianmin Bao, Ting Zhang, Hao Yang, Dong Chen, Fang Wen, and Baining Guo. 2019. Face X-ray for More General Face Forgery Detection. CVPR.
[6] Ekraam Sabir, Jiaxin Cheng, Ayush Jaiswal, Wael AbdAlmageed, Iacopo Masi, and Prem Natarajan. 2019. Recurrent convolutional strategies for face manipulation 1000 detection in videos. Interfaces (GUI) 3 (2019), 1.
[7] Xinggang Wang, Yongluan Yan, Peng Tang, Xiang Bai, and Wenyu Liu. 2018. 1018 Revisiting multiple instance neural networks. Pattern Recognition 74 (2018), 15–24.
[8] https://ai.facebook.com/datasets/dfdc/
Amazon SageMaker 是一项完全托管的服务,可以帮助开发人员和数据科学家快速构建、训练和部署机器学习 模型。SageMaker完全消除了机器学习过程中每个步骤的繁重工作,让开发高质量模型变得更加轻松。
现在,企业开发者可以免费领取1000元服务抵扣券,轻松上手Amazon SageMaker,快速体验5个人工智能应用实例。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com