视觉语言如何协同学习?港科大等最新《视觉语言智能》综述论文,全面阐述VL的任务、表示学习和大模型
来自香港科技大学、IDEA、中科院、清华、微软等发表《视觉语言智能》综述论文,从时间的角度对视觉语言智能进行了全面的研究。非常值得关注!

本文从时间的角度对视觉语言智能进行了全面的研究。这项研究的灵感来自于计算机视觉和自然语言处理的显著进展,以及从单一模态处理到多模态理解的最新趋势。我们将这一领域的发展总结为三个时期,即任务特定方法,视觉语言预训练(VLP)方法,以及由大规模弱标记数据训练的大模型。我们首先以一些常见的VL任务为例,介绍了特定于任务的方法。然后我们重点介绍了VLP方法,并全面回顾了模型结构和训练方法的关键组成部分。之后,我们展示了最近的工作是如何利用大规模的原始图像-文本数据来学习语言对齐的视觉表示,这种视觉表示在零或少数样本学习任务中得到了更好的泛化。最后,我们讨论了在模态协同、统一表示和知识整合方面的一些潜在的未来趋势。我们相信这篇综述将有助于人工智能和ML的研究人员和实践者,特别是那些对计算机视觉和自然语言处理感兴趣的人。
引言
计算机视觉(CV)和自然语言处理(NLP)是人工智能(AI)的两个分支,它们专注于在视觉和语言上模拟人类智能。近十年来,深度学习在这两个领域极大地推进了单模态学习,并在一系列任务上取得了最先进的成果。深度学习的显著进步的核心在于快速发展的GPU和大规模数据集的可用性,这允许在大规模上加速深度模型的训练。
随着深度学习的发展,我们看到了一系列功能强大的神经网络的发展。传统的神经网络通常是多层感知器(MLP),由多个堆叠的线性层和非线性激活组成(Rosenblatt, 1957, 1961)。LeCun等人(1998)提出了卷积神经网络(CNN),将平移不变特性作为对2D视觉输入更好的诱导偏差,这启发了大量的深度神经网络,包括AlexNet (Krizhevsky et al., 2012)、VGGNet (Simonyan and Zisserman, 2015a)、googlet (Szegedy et al., 2015)、和ResNet (He et al., 2016a)。另一个突出的突破是自然语言处理(NLP)领域的循环神经网络(RNN),它提出了循环细胞用于顺序数据建模(Rumelhart et al., 1985; Hochreiter and Schmidhuber, 1997a)。为了缓解长序列训练中梯度的消失和爆炸问题,提出了RNN的一种变体LSTM (Hochreiter and Schmidhuber, 1997a)和LSTM的一种更高效的版本GRU (Chung et al., 2014)。NLP的另一个重大突破是Transformer (Vaswani et al., 2017),它利用注意力机制追求更好的语言表征。使用多个堆叠的注意力层,Transformer可以以高并行性在全局范围内融合语言标记上的信息,这有利于强大的表示和大规模的训练。
虽然在单一模态领域取得了令人鼓舞的进展,但现实世界的问题往往涉及多种模态。例如,自动驾驶汽车应该能够处理人类的命令(语言)、交通信号(视觉)、道路状况(视觉和声音)。即使是单模态学习也能从多模态学习中受益。例如,语言学习需要感知,而感知是许多语义公理的基础(Bisk et al., 2020)。感知是人类理解物质世界的方式,决定了人类语言背后的假设。因为我们都听到和看到同样的事情,我们会留下一些知识作为常识,这些知识在我们的语言中是不成文的(Bisk et al., 2020)。即使局限于语言,言语也比文本包含更多有用的信息,例如,韵律可以暗示情感。注意到多模态感知在多模态和单模态任务中都有帮助,有大量的研究工作。多模的领域内, 视觉和语言的集成得到太多的关注, 因为视觉是人类最重要的感知理解环境和l语言对齐视觉特征可以极大地提高视觉任务的表现和视觉语言任务。此外,视觉语言智能的普及还得益于该领域丰富的数据集和基准。
解决许多特定于任务的VL问题的动力推动了VL学习的初步发展。这些VL问题包括图像描述、视觉问答(VQA)、图像-文本匹配等。Xu et al. (2015); Karpathy et al. (2014); Vinyals et al. (2015)集成了一个CNN图像编码器和一个RNN文本解码器用于图像描述。Antol et al. (2015); Yang et al. (2016); Anderson et al. (2018b) 通过将图像和文本映射到相同的潜在空间并从潜在表征中预测答案来解决VQA任务。Kiros et al. (2014); Karpathy et al. (2014); Huang et al. (2016); Lee et al. (2018)通过计算图像和文本在句子级别或标记级别上的相似度来进行图像-文本匹配。这些模型是为各种数据集的特定问题量身定制的,每个模型只能解决一个任务。
受普遍存在的语言(Devlin et al., 2018)和视觉的预训练和微调的启发,视觉和语言跨学科领域迎来了一个新时代:通过图像-文本对的预训练来学习视觉和语言的联合表征。VLP模型的兴起主要是受到了架构设计和训练方法中的语言模型的启发。例如,最近的许多研究(Li et al., 2019b; Lu et al., 2019; Zhang et al., 2021; Tan and Bansal, 2019; Li et al., 2020b; Yu et al., 2020; Chen et al., 2020)采用了BERT-like (Devlin et al., 2018)架构和训练方法。由于缺乏足够大规模的人工标注数据,VL学习的发展面临着严峻的挑战。最近,一些研究(Radford et al., 2021; Jia et al., 2021; Wang et al., 2021; Li et al., 2021b)通过采用对比学习和利用大规模网络爬行数据学习视觉语言特征,打破了这一限制,这些特征可用于零样本学习。
VL领域的快速发展推动了对该领域现有研究的全面综述。本文旨在提供一个结构化的综述,在VL领域的最新进展,以帮助研究人员获得一个整体的视图,并更好地理解最近的研究。我们将VL学习的发展分为三个阶段。第一个是从2014年到2018年,专门的模型被设计用于不同的任务。第二个时代是2019年至2021年,在此期间,通过对标记良好的VL数据集进行预训练,学习视觉和语言的联合表征。最后,随着2021年CLIP的出现,第三个时代开始了(Shen等人,2021年),研究人员寻求在更大的弱标记数据集上预先训练VL模型,并通过预训练VL获得强大的零样本/少样本视觉模型。
回顾VL智能的整个发展过程,我们发现总体目标是学习良好的视觉表征。一个好的视觉表示应该具有(Li et al., 2021b)中总结的三个属性,即对象级、语言对齐和语义丰富。对象级意味着视觉和语言特性的粒度应该分别与对象级和词级一样细。语言对齐强调与语言对齐的视觉特征可以帮助完成视觉任务。语义丰富是指不受领域限制地从大规模数据中学习表示。在VL的第一个时代,研究工作的目的是解决具体的问题,而不是学习上述好的表征。在第二个时代,研究人员训练模型的图像-文本对,以获得语言对齐的视觉特征。这个时代的一些作品采用检测到的区域作为图像表示,学习对象级的特征。只有在第三时代,研究人员才能处理大规模的数据集和预训练的语义丰富的特征。
据我们所知,这是第一次从时间段的角度总结研究的VL综述。本文的其余部分组织如下。我们从VL中的一些特定于任务的问题开始,如第二节中的图像标题、VQA和图像-文本检索。然后,我们在第三节中全面解释了预训练增强的视觉-语言联合表征学习。在第六节中,我们展示了一些直接从原始图像-文本数据学习语言对齐的视觉表示的工作,以及大规模的视觉语言训练。
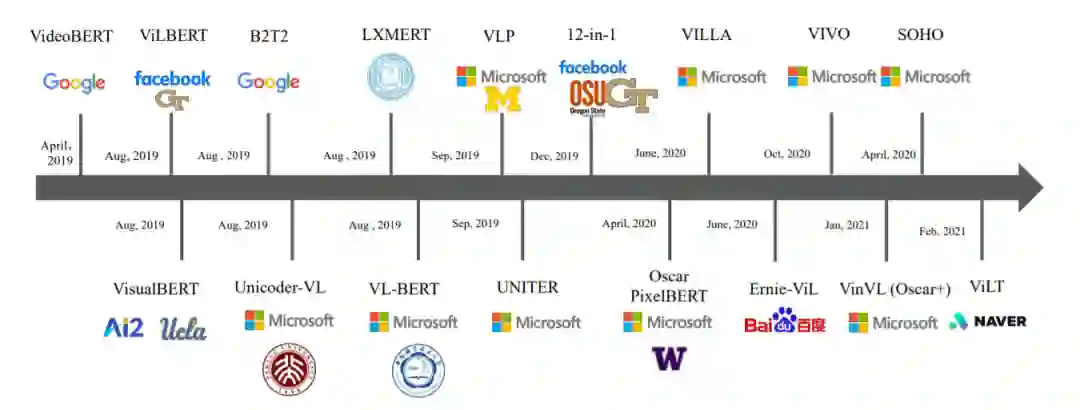
VLP方法发展概览
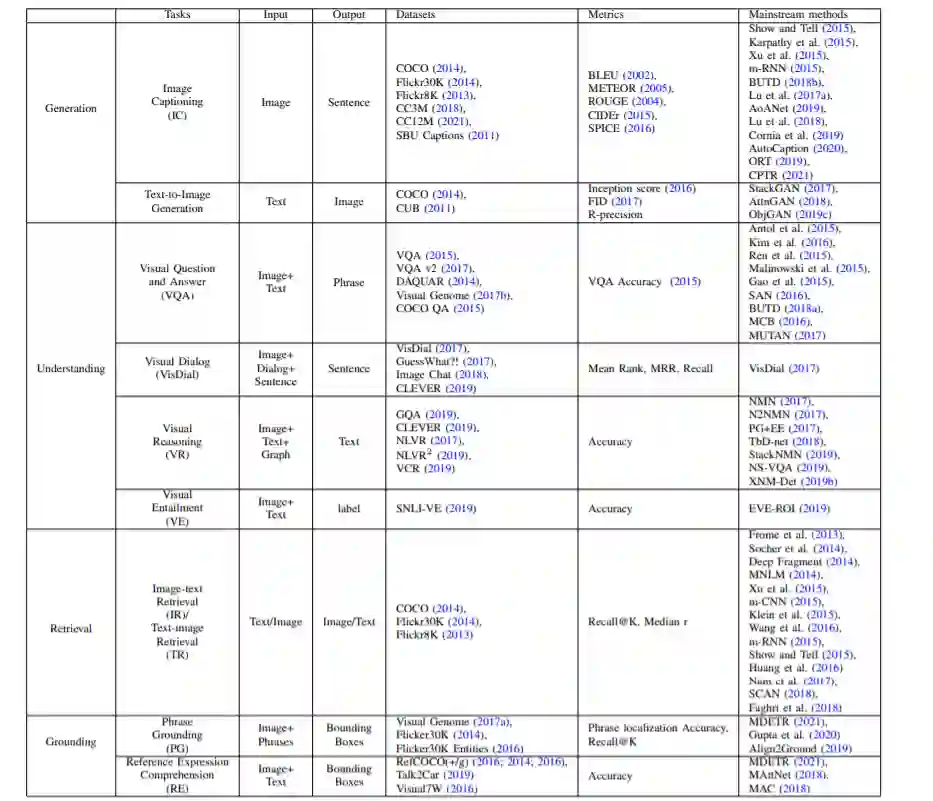
与特定任务问题的比较。任务分为四类。对于每个任务,我们总结了输入、输出、数据集、度量和主流方法。
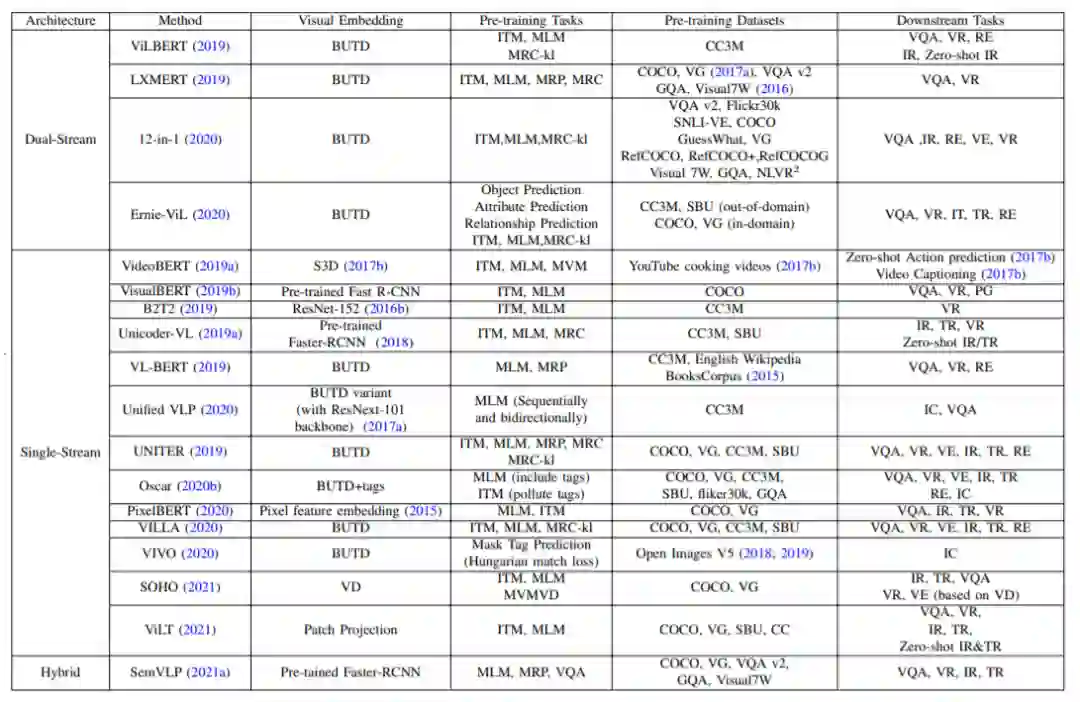
未来发展
通用统一模态
由于Transformer架构,研究人员在单模态和多模态表示学习方面都取得了显著进展。在前几节中,我们讨论了多模态表示和模态合作,它们以不同的方式连接视觉和语言。一个更雄心勃勃的目标是建立一个通用的表示模型,它可以统一多种模态。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“VLI” 就可以获取《视觉语言如何协同学习?港科大等最新《视觉语言智能》综述论文,全面阐述VL的任务、表示学习和大模型》专知下载链接




