本文是对中科院自动化所和腾讯微信AI团队共同完成,被 AAAI2020 录用的论文《DMRM: A Dual-channel Multi-hop Reasoning Model for Visual Dialog》进行解读,相关工作已开源。
![]()
论文地址:https://arxiv.org/abs/1912.08360
代码地址:https://github.com/phellonchen/DMRM
为解决目前视觉对话系统中视觉语言两个模态之间的多轮指代、推理以及信息对齐等问题,自动化所陈飞龙博士、许家铭副研究员和徐波研究员等人与腾讯一起共建了一种双通道多步推理视觉对话生成模型,使得模型从视觉和语言两个方面丰富问题的语义表示,更好地针对问题生成高质量答复。
由于自然语言处理和计算机视觉技术的快速发展,多模态问题受到了越来越多的关注。视觉对话是一种视觉语言交互任务,需要AI智能体与人类围绕同一个输入图像进行交流。这是一项具有挑战性的任务,要求模型能够充分理解人类当前轮对话的提问,同时有效整合对话历史的语言模态和输入图像的视觉模态,以关注与当前问题相关的语义信息并进行推理,给出高质量答复。研究团队就视觉对话任务提出一种双通道多步推理模型(简称DMRM)。
![]()
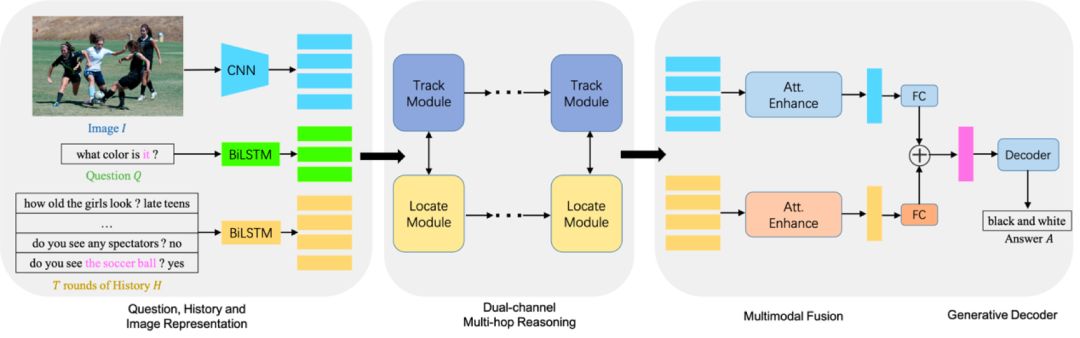
DMRM通过利用双通道推理同步地从对话历史和输入图像中捕获信息,以丰富问题的语义表示。
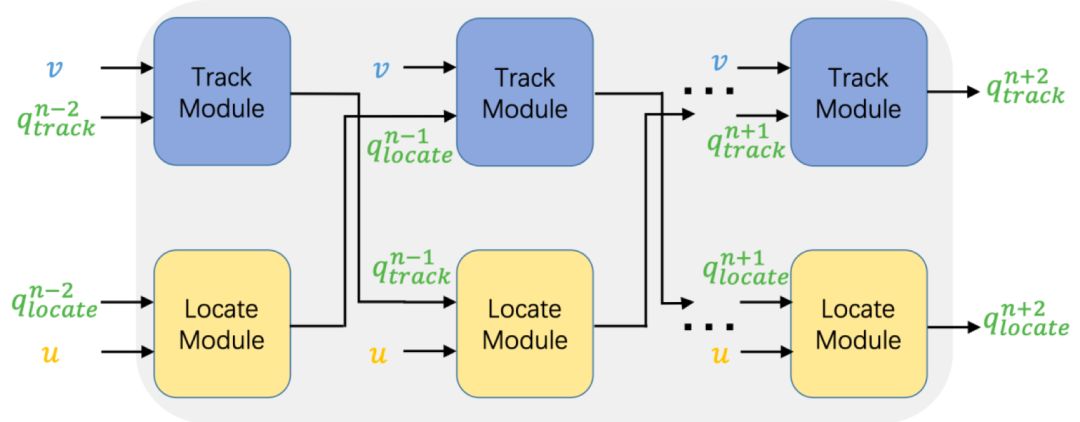
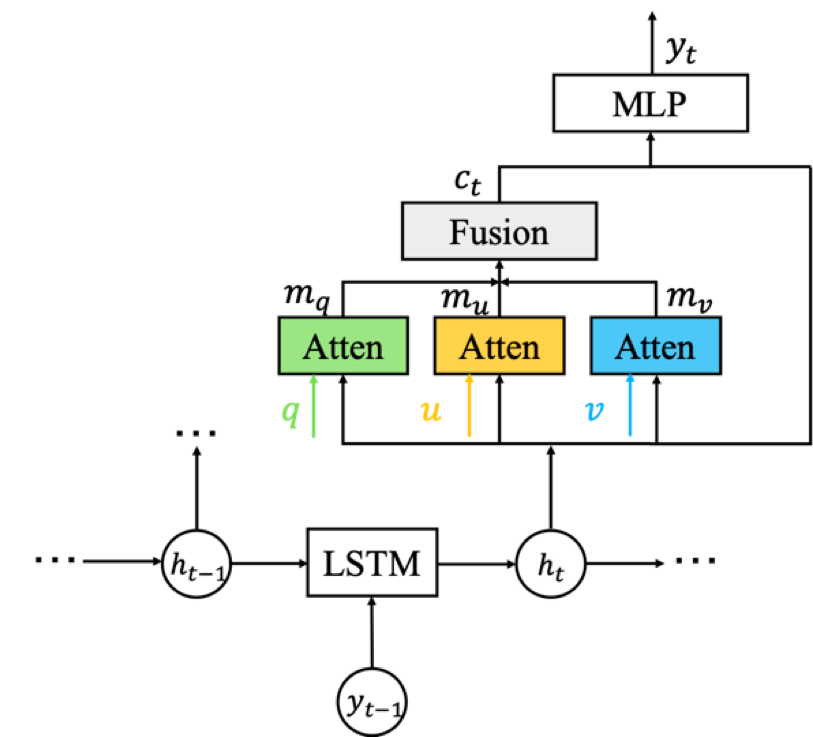
具体地说,DMRM维护一个跨模态交互的双通道(如图1所示,Track Module负责从视觉方面丰富问题的语义表示,Locate Module负责从对话历史方面丰富问题的语义表示),通过每个通道中的多步推理过程(如图2所示)获得与当前问题和对话历史相关的视觉特征,以及当前问题和输入图像相关的语言特征。此外,团队还设计了一种多模态注意机制,以进一步增强解码器来生成更准确的答复。
![]()
团队在视觉对话任务中的解码端引入多模态注意机制,有效地缓解了只利用编码端输出多模态信息融合的局限性,在解码过程中能够较好的进行一些错误纠正及语义丰富。
![]()
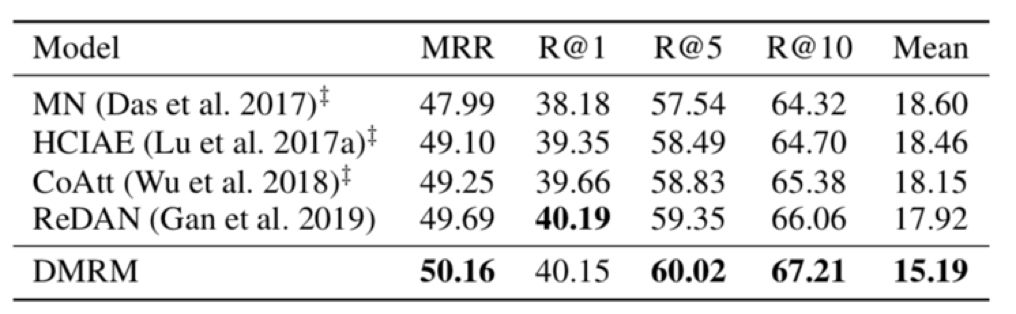
团队在VisDial v0.9和VisDial v1.0两个公开数据集上进行实验。VisDial v0.9包含了83k训练集,40k测试集,每一幅图像对应10轮对话和图像描述。VisDial v1.0包含了123k训练集,2k验证集和8k测试集。
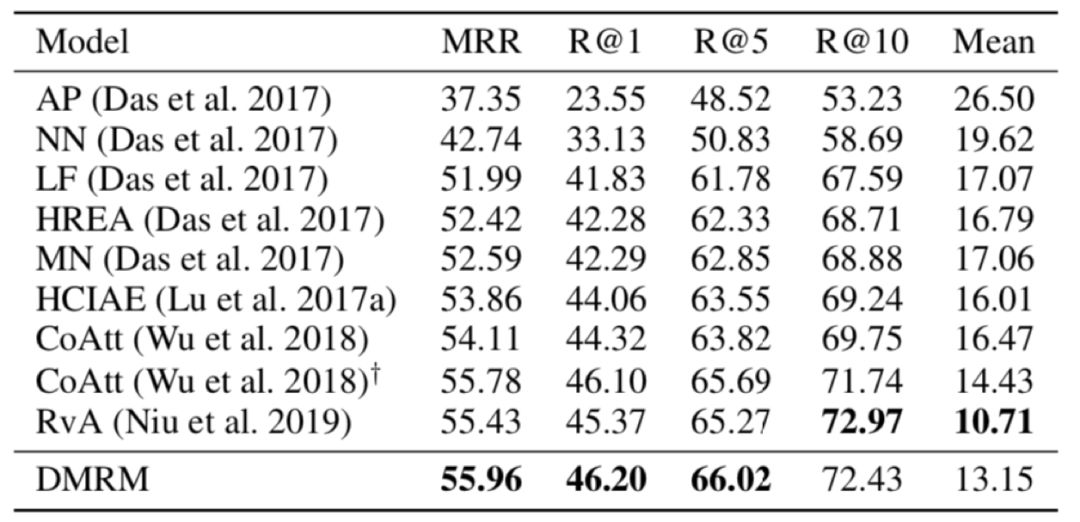
表1和表2给出了不同模型在两个数据集上的实验效果。可以看出,在大多数评价指标上,双通道多步推理视觉对话生成模型DMRM都优于其他模型(其中,MRR、R@k越高越好,Mean越低越好)。
![]()
表1 不同模型在VisDial v0.9数据集上的实验结果
![]()
表2 不同模型在VisDial v1.0数据集的实验结果
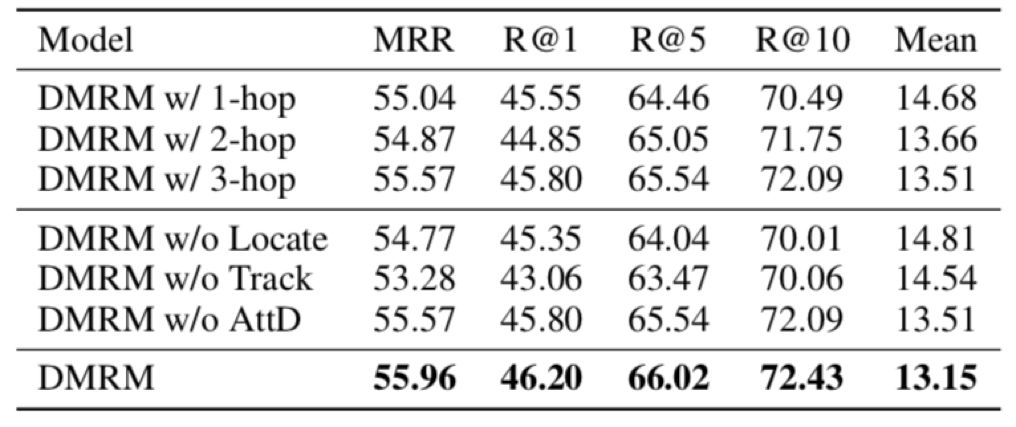
表3显示了双通道多步推理视觉对话生成模型DMRM的消融实验,分析了各个模块对于视觉对话任务效果的影响,可以看出双通道多步推理以及多模态解码器都起到了重要作用。
![]()
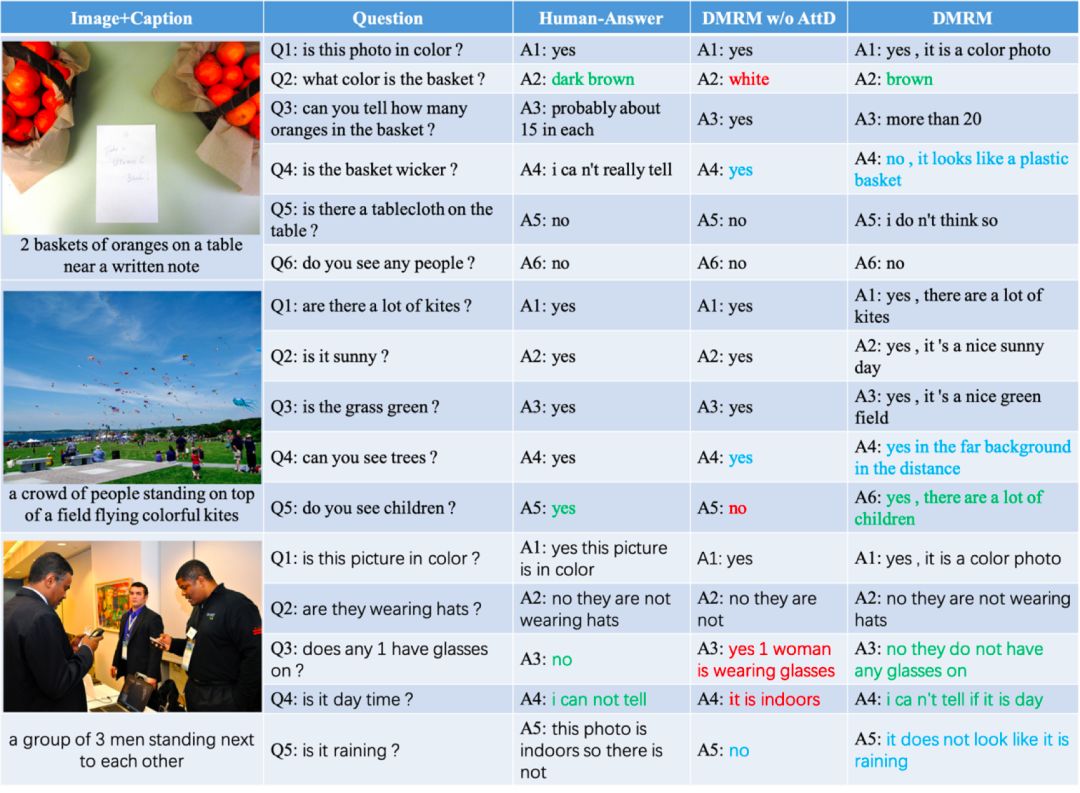
图4显示了DMRM模型生成的回答结果,融合了多模态解码器的DMRM模型在准确性和语义丰富性上表现更好。
![]()
AAAI 2020 报道:
新型冠状病毒疫情下,AAAI2020 还去开会吗?
美国拒绝入境,AAAI2020现场参会告吹,论文如何分享?
AAAI 2020 论文解读系列:
13. [中科院自动化所] 通过解纠缠模型探测语义和语法的大脑表征机制
14. [中科院自动化所] 多模态基准指导的生成式多模态自动文摘
15. [南京大学] 利用多头注意力机制生成多样性翻译
16. [UCSB 王威廉组] 零样本学习,来扩充知识图谱(视频解读)
17. [上海交大] 基于图像查询的视频检索,代码已开源!
![]()
更多AAAI 2020信息,将在「AAAI 2020 交流群」中进行,加群方式:添加AI研习社顶会小助手(AIyanxishe2),备注「AAAI」,邀请入群。
![]()
![]()
![]()
![]() 点击“阅读原文” 前往 AAAI 2020 专题页
点击“阅读原文” 前往 AAAI 2020 专题页