如何看待机器学习中的"稳定性"?

本文作者阿萨姆,本文首发于作者的知乎专栏《数据说》, AI研习社获其授权发布。
前言
机器学习的过程往往被人戏称为“炼丹”,这大概要归功于其中难以估量的不确定性。
在道观(实验室)里,我们可以放心的让算法在丹炉(GPU)上无休无止的炼(跑)下去,而仅仅追求模型的低误分率及高精度(丹药的纯度)。而在工业界,除却误分率这种直观的表现以外,我们更在意一个模型是否稳定。
到底什么是稳定?千人千面。而是否高阶的炼丹师有独特手法更稳定的练出“金丹”,降低失败率呢?让我们带着疑问进入今天的正片环节:)
计算的稳定性(Computational Stability)
计算稳定性特指模型运算性能的鲁棒性(Robustness),我猜计算机背景的朋友肯定不会对此感到陌生。举个简单例子,如果我们让整数型(int)的变量来储存的一个浮点变量(float),那么我们会损失精度。在机器学习中,我们往往涉及了大量的计算,受限于计算机的运算精度,很多时候我们必须进行凑整(Rounding),将无理数近似到浮点数。这个过程中不可避免的造成了大量的微小误差,随着凑整误差累计积少成多,最终会导致系统报错或者模型失败。我们一起来看看机器学习中几种常见的的计算稳定性风险。
1.1.下溢(Underflow)和上溢(Overflow)
顾名思义,溢出是代表内容超过了容器的极限。在机器学习当中,因为我们大量的使用概率(Probability),而概率的区间往往在0至1之间,这就导致了下溢发生的可能性大大提高。
举个简单的例子,我们常常需要将多个概率相乘,假设每个概率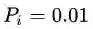
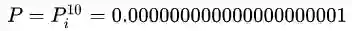
从此可以看出,仅仅需要是个1%的概率相乘就可以得到一个极小的结果。而机器学习中往往是成百上千个数字相乘,类似的情况导致计算机无法分辨0和和一个极小数之间的区别。在这种情况下,下溢可能导致模型直接失败。
相似的,上溢也是很容易发生的状况。试想我们需要将多个较大的数相乘,很轻易的就可以超过计算机的上限。64位计算机的数值上限并没有大家想象中那么大:
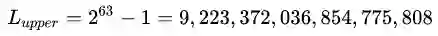
因此在实际模型中,我们会避免将多个概率相乘,而转为求其对数(Log),举例:
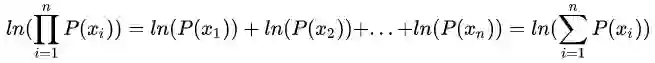
这样我们就成功的将多项连乘转化为了多项加法,避免了可能发生的溢出。而对数还有更多优美的数学的性质,例如其单调递增性,易转化为概率模型,凸优化性等。
1.2.平滑(Smoothing)与0
和下溢和上溢类似,我们常常会发现机器学习中遇到“连乘式”中某个元素为0,导致运算失去意义。以朴素贝叶斯(Naive Bayes)为例:
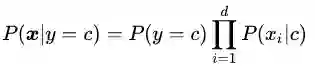
我们判别一个样本点属于某个分类 的概率为其各项特征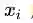
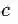
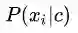
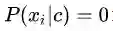
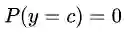
从某种意义上来说,这也属于一种计算上的不稳定。常见的做法是用拉普拉斯平滑(Laplace Smoothing)来修正这种计算不稳。简单的说就是人为的给每种可能性加一个例子,使其概率不再为0。
于是某个特征取特定值在分类下的概率就会被修正为:
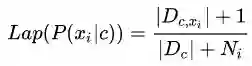
在这种平滑处理后,我们所有乘子的取值都不会为0。相似的做法在自然语言处理(NLP)中也常常会用到,比如N-gram模型的语言模型也往往需要平滑来进行处理,此文中暂时不表。
1.3. 算法稳定性(Algorithmic Stability)与扰动(Perturbation)
在机器学习或统计学习模型中,我们常常需要考虑算法的稳定性,即算法对于数据扰动的鲁棒性。相信关注专栏的读者应该已经听我无数次提起过:“模型的泛化误差由误差(Bias)和方差(Variance)共同决定,而高方差是不稳定性的罪魁祸首”。
简单的说就是,如果一个算法在输入值发生微小变化时就产生了巨大的输出变化,我们就可以说这个算法是不稳定的。此处的算法不仅仅是说机器学习算法,也代表“中间过程”所涉及的其他算法,给出几个具体的例子:
矩阵求逆(Inverting a Matrix)的过程就属于不稳定的,我们常常会选择避开矩阵求逆。有兴趣的读者可以进一步了解其原因。
另一个有趣的例子是神经网络中的批量学习(Batch Learning),即训练神经网络时不一个个例子的训练而是批量的学习训练数据。在选择对应的批量尺寸(Batch Size)和相对应的学习速率(Learning Rate)时需要特别小心,错误的学习率和尺寸会导致不稳定的学习过程。当我们以小批量进行学习的时候,小样本中的高方差(High Variance)导致我们学到的梯度(Gradient)很不精确,在这种情况下,应该使用小学习速率防止我们步子迈得太大!相反的,当我们的批量尺寸选的较大时,可以放心的使用较大的速率。
决策树(Decision Tree)的性质导致它也属于一种不稳定的模型。训练数据中的微小变化甚至可以改变决策树的结构,以至于我们对于决策树的可信度总是画上一个问号。为了解决其不稳定的问题,研究人员发明了集成学习(Ensemble Learning),其中的Bagging就通过降低其方差的方法来增强其稳定性。
于是为了方便,我们归纳出一部分稳定模型。比较常见的模型有各种支持向量机(SVM)的衍生模型,这也是SVM在本世纪初大火的原因的之一:)
数据的稳定性(Data Stability)
严格意义上说,数据稳定性往往特指的是时间序列(Time Series)的稳定性。而笔者此处指的是广义上的数据,不仅仅是时间序列。从根本上说,数据的稳定性主要取决于其Variance。
2.1. 独立同分布(Independent Identically Distributed)与泛化能力(Generalization Ability)
一个机器学习模型的泛化能力指的是其在新样本上的拟合能力。模型能够获得强泛化能力的数据保证就是其训练数据是独立同分布从母体分布上采样而得。让我们用一点点统计学的知识....
假设我们有一个母体(Population),它的分布是1到100的正整数:
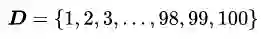
假设我们有3个从D中得到的采样:

我们会发现第一个采样好像都是平方数,第二个采样都是十的倍数,而第三个采样似乎都是小于10的连续整数。在这种采样下,我们可以大胆的猜测学习模型无法通过学习这三个数据集而得到良好的泛化能力....因为它们并不是独立同分布的采样。
那么读者会问了,那什么才算是独立同分布的采样,首先:
我们希望采样的数据不是故意的挑选的,比如刻意挑出了一堆平方数
我们希望采样的数据是从同一个分布里面挑的,而不是从几个分布中各挑几个...
因此如何保证我们的训练数据足够稳定呢?笔者有几句看起来像废话的建议:
训练数据越多越好...这样可以降低数据中的偶然性,降低Variance
确保训练数据和母体数据及预测数据来自于一个分布。举例,你不能用统计学家的平均智商来预测生物学家的平均智商,这不公平...至于对哪一方不公平,留给读者思考。
因此数据的稳定性的基本前提就是独立同分布,且数量越多越好。稳定的数据可以保证模型的经验误差(Empirical Risk)约等于其泛化误差(Generalization Risk)。
2.2. 新常态: 类别不平衡
越来越多的机器学习问题都会遭遇不平衡的数据分布,此处的不平衡可以指很多事情,比如二分类问题中的正例和反例数量悬殊。但需要注意的是,如果母体的分布本身就是不平衡的,千万不要通过采样来使其分布平衡。这样就违反了独立同分布的采样!
面对天生不平衡的数据,我们有很多做法可以进行处理,比较常见的再平衡做法包括:
过采样(Over-Sampling): 将数据量较少的的分类重复利用
欠采样(Down-Sampling):将数据量较多的分类选择性丢弃一部分。
在类似的情况下,往往集成学习的表现非常好,这都需要归功于集成学习可以有效的降低Variance。读者必须注意,无论是过采样还是欠采样都会带来问题,比如过采样容易导致过拟合但欠采样其实浪费了数据。
因此不平衡往往也带来了稳定性问题,而究其根本还是因为过高的Variance。
性能的稳定性 - “理论卫道士”
评估机器学习模型的稳定性(Stability)和评估机器学习的表现(Performance)有本质上的不同,不能简单的通过评估准确率这种指标来说一个机器学习稳定与否。举个最简单的例子,假设一个模型一会儿表现特别好,一会儿比较特别差,我们敢用这个模型于实际生产中吗?说白了,稳定性还是由于数据的方差Variance决定。
那么有小伙伴说了,我们或许可以用交叉验证(cross-validation)来评估一个算法模型的稳定性。没错这是个正确的思路,但最大的问题,就是交叉验证太慢了。不管是五折(5-fold)还是十折(10-fold)都需要较长的时间及重复运算。生命是宝贵的,1s都不能浪费!
因此我们一般通过计算学习理论(Computational Learning Theory)有时候也叫统计计算理论(Statistical Learning Theory)来对算法进行分析。介绍两个框架供大家参考:
概率近似正确框架(Probably Approximately Correct, PAC)。PAC框架主要回答了一个问题:一个学习算法是否可以在多项式函数的时间复杂度下从样本 中近似的学到一个概念,并保证误差在一定的范围之内。
界限出错框架(Mistake Bound Framework, MBF)。MBF从另一个角度回答了一个问题,即一个学习模型在学习到正确概念前在训练过程中会失误多少次?
有鉴于篇幅以及这个概念的深度和广度,笔者会在以后的文章中以专题的形式展开。但计算学习理论为量化学习模型稳定性指出了一个方向,同时也缓和了统计学习对机器学习长久以来的偏见--机器学习缺乏理论基础。
只打算进行实践而不打算在机器学习领域进行研究的读者,不必过分深究到底什么是PAC,因为其实用性是有限的,而且还会用到很多概率论的知识。
后记 - 求稳还是求创新?
本文的目的不是列出所有的稳定性问题,也不是想让大家杯弓蛇影,怀疑一切。笔者只是单纯想借着这篇文章说明机器学习是一门交叉学科,它不仅需要你了解计算机上面的浮点精度防止溢出,还需要你了解统计中的数据采样过程。
从这个角度出发,计算机科学出身的读者要放宽自己的视野,还有很多其他领域与机器学习息息相关;而统计学或者数学出身的朋友也不要觉得计算机仅仅是运算工具,你们碰到的很多问题其实说白了是运算性问题。
上世纪末,小平同志曾说过:"稳定压倒一切",将其引申到机器学习领域似乎也不为过。
然而,在稳定之外,对于未知领域的探索,才是创新。因此放宽“稳定”的界限,不断探寻真理的边界,是我辈知识分子对于这个动荡未知世界所能表达的最后的人文关怀。

上海交通大学博士讲师团队
从算法到实战应用
涵盖CV领域主要知识点
手把手项目演示
全程提供代码
深度剖析CV研究体系
轻松实战深度学习应用领域!
▼▼▼
(限时早鸟票~)

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
从零开始入门机器学习算法实践
▼▼▼


