【NLP笔记】理论与实践详解词向量

作者:艾春辉
学校:华北电力大学、苏州大学准研究生
Introduction to Natural Language Processing
nlp有什么特别的?
-
离散的/符号的/分类的 -
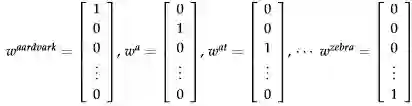
ֺ例如: “rocket”意思很多,我们使用单词和字母来表达信号。最重要的是,语言符号可以被编码成多种形式,通过信号传给大脑,大脑本身也是一种连续方式对这些信号解码
怎样去表示词语?
-
在所有的nlp任务重,首要的也是最重要的是我们如何去表示词语?我们需要首先了解词语之间的相似性和差异性。采用词向量,我们可以和容易的编码词语
Word Vectors
-
首先提出的就是one-hot编码(独热码)
这里我们可以查看到,向量的维度太大
-
我们通过将每个词语独热码话,我们会发现一个问题,就是没有相似性概念了。
所有向量都是正交的,这就代表着一个问题,如上图所示: hotel和motel是相似的,但是在独热码中和cat也相似,这是不可取的。
-
结论: 简单one-hot向量无法给出单词间的相似性,我们需要将维度减少到一个低维度的子空间,来获得稠密的词向量,获得词之间关系
SVD Based Methods
-
svd的原理类似于主成分分析,但是主成分分析只能针对方阵,而svd可以针对所有矩阵进行
-
过滤了一些噪声,加快运算
-
我这里不详细 怎么计算的,我讲一下大概u是 的特征向量,v是 的特征向量, 是特征值的排序后开根号
-
举例子:
import numpy as np
w = np.array([[1,1],[0,1],[1,0]])
w
array([[1, 1],
[0, 1],
[1, 0]])
求u
B = np.dot(w,w.T)
a,b = np.linalg.eig(B)
u = b[:,[0,2,1]]# 参考特征值大小排序给出
u
array([[ 8.16496581e-01, -1.57009246e-16, 5.77350269e-01],
[ 4.08248290e-01, -7.07106781e-01, -5.77350269e-01],
[ 4.08248290e-01, 7.07106781e-01, -5.77350269e-01]])
a = np.sort(a)[::-1]
a
array([ 3.00000000e+00, 1.00000000e+00, -2.22044605e-16]
求v
C = np.dot(w.T,w)
C
array([[2, 1],
[1, 2]])
c,d = np.linalg.eig(C)
d
array([[ 0.70710678, -0.70710678],
[ 0.70710678, 0.70710678]])
c = np.sqrt(c)
c
array([1.73205081, 1. ])
v = d
根据条件, 表示的元素是3*2的,且对角线上元素等于c
sigma = np.array([[1.73,0],[0,1],[0,0]])
进行验证,
u.dot(sigma).dot(v.T)
array([[ 9.98815966e-01, 9.98815966e-01], [ 9.99407983e-01, -5.92017151e-04], [-5.92017151e-04, 9.99407983e-01]])
u,sigma,v = np.linalg.svd(w)
Window based Co-occurrence Matrix (共现矩阵的提出)
-
依赖我们的语境我们可以知道,单词与单词之间有一点的共现性(出现在一起的概率很高),我们采用svd的 矩阵当成我们词向量矩阵,对此我们计算每个单词在我们特定窗口(length window)中出现的次数,按照这种方法进行统计
-
采用结果:
-
Generate |V|×|V|co-occurrence matrix, X. -
Apply SVD on X to get X = . • -
Select the first k columns of U to get a k-dimensional word vectors. -
indicates the amount of variance captured by the first k dimensions 使用svd
-
虽然思路很好,但是还有一些问题需要解决
However, count-based method make an efficient use of the statisticsSome solutions to exist to resolve some of the issues discussed above:---------上述问题的解决方法
-
Ignore function words such as "the", "he", "has", etc.---忽略功能词语 -
Apply a ramp window – i.e. weight the co-occurrence count based on distance between the words in the document.---采用加权方法 -
Use Pearson correlation and set negative counts to 0 instead of using just raw count.---采用皮尔逊相关系数(数据分析方法中有) -
The dimensions of the matrix change very often (new words are added very frequently and corpus changes in size).---矩阵维度经常变化
-
The matrix is extremely sparse since most words do not co-occur.---矩阵太过稀疏
-
The matrix is very high dimensional in general (≈ )----维度太高
-
Quadratic cost to train (i.e. to perform SVD)-----训练成本高
-
Requires the incorporation of some hacks on X to account for the drastic imbalance in word frequency
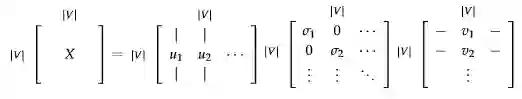

Iteration Based Methods - Word2vec
-
我们希望尝试一个新的模型,这个模型能够一次学习一个迭代,并且能给给上下文单词出现的概率编码,而不是去计算和存储一个大型数据集 -
这个想法的思路就是训练一个模型,模型的参数就是词向量。在一个确定的目标函数下进行训练,评价我们损失函数,并且遵循一些更新的规则,这个模型具有惩罚造成失误的参数的作用。我们把这种更新方法叫做反向传播。模型和任务越简单,我们训练越快 -
word2vec介绍
两个算法
-
cbow和skip-gram,cbow预测中心词,skip-gram预测上下文
两种训练方法
-
两个训练方法:negative sampling和 hierarchical softmax。Negative sampling通过抽取负样本来定义目标,hierarchical softmax通过使用一个有效的树结构来计算所有词的概率来定义目标
Language Models (Unigrams, Bigrams, etc.)
-
1-gram模型,一元语言模型(unigram model),假设单词的出现是完全独立的,分解概率
但是这种方法不太合理,我们知道下面词语的概率和上一个词语概率是有很大影响的,所以我们让序列的概率取决于单词和旁边单词的成对概率---bigram模型
-
2-gram模型(bigram模型)
但是还是有点简单,因为我们只关心一对临近单词,而不是整个句子
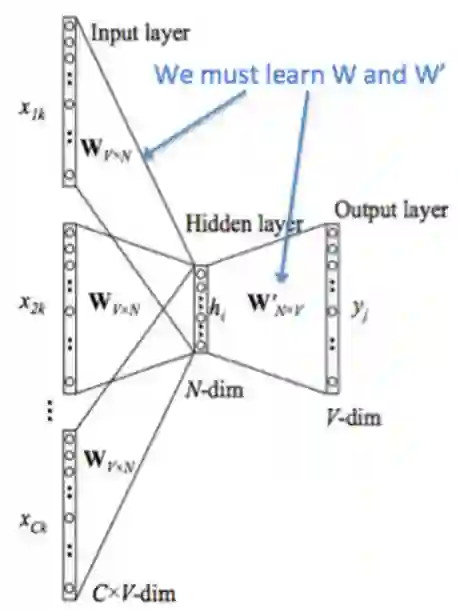
Continuous Bag of Words Model (CBOW)
-
{"The", "cat", ’over", "the’, "puddle"} as a context and from these words, be able to predict or generate the center word "jumped". This type of model we call a Continuous Bag of Words (CBOW) Model. -----预测中心词语
-
对于模型中的每个单词有两个向量,一个是单词作为中心词时候,一个单词作为上下文时候
-
首先我们采用onthot形式的词向量表示我们的输入 ,输出表示为 .因为我们只有一个输出,所以我们称为已知中心词语的ont-hot向量
-
:词汇表V中的单词i -
:输入词矩阵 -
:V的第i列,表示单词 的输入向量 -
:输出词矩阵 -
:U的第i行,单词 的输出向量表示 -
how to do it?
1. 我们为大小为m的输入上下文,生成one-hot词向量
-
我们从上下文 得到输入向量 -
Average these vectors to get -----对上述向量求平均值 -
生成一个分数向量 当相似向量的点积越高,就会令到相似的词更为靠近,从而 获得更高的分数。将分教转换为概率 $ \hat y}=\operatorname{softmax}(z) \in \mathbb{R}^{$ -
We desire our probabilities generated, $ \hat y} \in \mathbb{R}^{ y \in \mathbf{R}^{|V|}$, which also happens to be the one hot vector of the actual word.---就是希望均值能够和我们向量相匹配 -
损失和优化方法
-
上述式子中损失函数
-
但是y是one-hot向量,所以上面损失函数优化为:
-
对于概率分布,交叉熵很好的为我们提供了一个度量,所以优化函数为:
-
我们采用sgd来更新优化
-
其实我们主要更新的就是w和w‘,并且w代表的是词嵌入矩阵
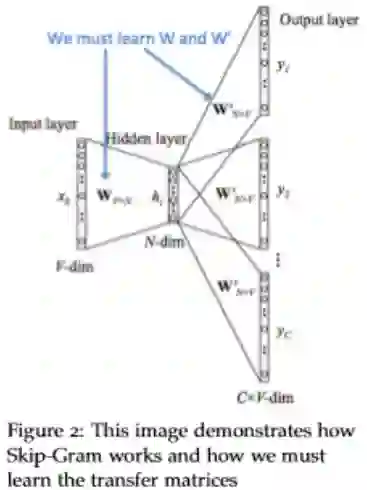
Skip-Gram Model
-
同 一样,我们定义的参数和cbow一样
-
定义:
-
We generate our one hot input vector of the center word. ---中心词识别 -
我们从上下文 得到输入入向量 -
生成分数向量 -
将分数向量转化为概率 注意 是每个上下词观寨到的概率 -
我们把我们生成的概率匹配真实概率 -
图示:
-
优化函数: 我们引用一个强力的朴素贝叶斯假设:In other words, given the center word, all output words are completely independent,输入向量时候,输出向量是完全独立的
Negative Sampling(负采样)
-
For every training step, instead of looping over the entire vocabulary, we can just sample several negative examples! We "sample" from a noise distribution (Pn(w)) whose probabilities match the ordering of the frequency of the vocabulary. -----对于每一个训练的时间步长,我们仅仅抽取一些负样本,并且跟新它们的目标函数,梯度,更新规则
-
目标函数优化:考虑一对中心词和上下文词 (w, c) 。这词对是来自训练集吗? 我们通过 表示 (w, c) 是来自语料库。相应地, 表示 (w, c) 不是来自语料库。对此我们采用sigmod建模
-
现在,我们建立一个新的目标函数,如果中心词和上下文词确实在语料库中,就最大化概率 , 如果中心词和上下文词确实不在语料库中, 就最大化概率 。我们 对这两个概率采用一个简单的极大似然估计的方法(这里我们把 作为模型的参数,在我们的例子是 和
-
极大似然估计的优化;
上述函数还是太复杂,我们需要再次进行优化: 最大化似然函数等同于最小化负对数似然
-
对于 Skip-Gram 模型,我们对给定中心词 c 来观祭的上下文单词 c-m+j 的新目标函数为
-
对 CBOW 模型,我们对给定上下文向量 来观察中心词 的新的目标函数
-
但是负采样在0.75的时候效果最好
Hierarchical Softmax
-
, hierarchical softmax tends to be better for infrequent words, while negative sampling works better for frequent words and lower dimensional vectors.Hierarchical Softmax 对低频词往往表现得更好,而负采样对高频词和低维度向量表现的更好
Hierarchical softmax 使用一个二叉树来表示词表中的所有词。树中的每个叶结点都是一个单词,而且 只有一条路径从根结点到叶结点。在这个模型中,没有词的输出表示。相反, 图的每个节点(根节点和 叶结点除外) 与模型要学习的向量相关联。单词作为输出单词的概率定义为从根随机游走到单词所对应 的叶的索率。计算成本变为
-
实际上,我们不用便利全部,我们只需要对应路径上的概率求即可
-
Finally, we compare the similarity of our input vector to each inner node vector using a dot product. Let's run through an example. Taking in Figure 4, we must take two left edges and then a right edge to reach
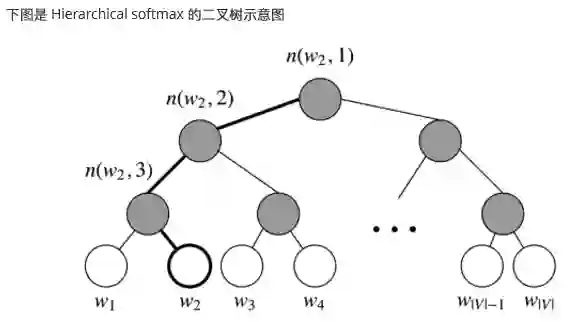
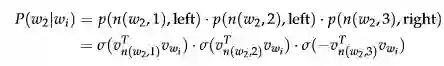
-
我们更新的不是每个词的输出向量,而是更新二叉树中从根节点到叶节点的路径上的节点向量
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心![]() 。
。
欢迎加入AINLP技术交流群
进群请添加AINLP小助手微信 AINLPer(id: ainlper),备注NLP技术交流
![]()
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。
![]()
阅读至此了,分享、点赞、在看三选一吧🙏







