MIT华人团队实现“穿墙透视”!超强动作检测
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
来自MIT CSAIL的一个华人研究团队最近发表了一篇论文,介绍了一种神经网络模型,该模型可以在光线不足的环境下检测到被墙壁遮挡的人体动作。

论文地址:
https://arxiv.org/pdf/1909.09300.pdf
先来一组动图大家感受下:

墙后动作可识别

黑暗环境可识别
他们的模型将射频(RF)信号作为输入,生成3D人体骨架作为中间表示,并随着时间的推移识别多个人的动作和互动。

多人模式可识别
通过将输入转换为基于中间骨架的表示形式,MIT的模型可以从基于视觉的数据集和基于RF的数据集中学习,并允许这两个任务互相帮助。而且证明了该模型在可见场景中达到了与基于视觉的动作识别系统相当的精度,但在人不可见的环境下仍然能够准确地工作,因此解决了超出当今基于视觉的动作识别极限的场景。
本文实现了以下几大突破:
提出了第一个使用无线电信号进行基于骨架的动作识别的模型;它进一步证明了这种模型可以仅使用RF信号(如图1所示)就可以准确识别墙壁另一面的动作和相互作用,并且在极其昏暗的环境下仍可准确识别。
本文提出了“骨架”作为跨模式传递与动作识别相关的知识的中间表示,并通过经验证明这种知识的传递可以提升表现。
本文介绍了一个新的spatio-temporal attention模块,该模块改进了基于骨架的动作识别,而不管骨架是从RF还是基于视觉的数据生成的。
它还提出了一种新颖的多提案模块,该模块扩展了基于骨架的动作识别,以检测多人同时进行的动作和互动。

图1:该图显示了他们系统的两个测试案例
左上角的图中,两个人握手,而其中一个在墙后。右上角的图中,一个人躲在黑暗中,向另一个正在打电话的人扔东西。下面两张图是由他们的模型生成的骨架表示和动作预测。
该图进一步显示,RF-Action还可以获取从视觉数据生成的3D骨架。这允许RF-Action与现有的基于骨架的动作识别数据集一起训练。
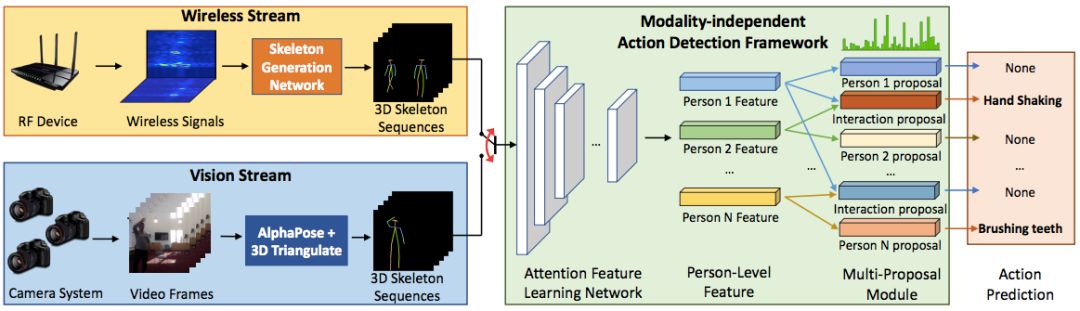
图3:RF-Action架构
RF-Action从无线信号中检测人为行为。它首先从原始无线信号输入(黄色框)中提取每个人的3D骨架。然后,它对提取的骨架序列(绿色框)执行动作检测和识别。动作检测框架还可以将从视觉数据生成的3D骨架作为输入(蓝色框),从而可以使用RF生成的骨架和现有的基于骨架的动作识别数据集进行训练。
我们使用在不同的联合交叉(IoU)阈值θ处的平均精度(mAP)来评估模型性能,取mAP在θ=0.1和θ= 0.5时的结果。
我们使用RF多模态数据集(RF-MMD)。利用无线电设备收集RF信号,并使用10个不同视角的摄像头系统收集逐帧视频。无线电设备和摄像头系统的同步差异小于10毫秒。
我们在10个不同环境中(办公室,休息室,走廊,走廊,演讲室等)对30名志愿者收集了25小时的数据,从PKU-MMD的动作集中选择35个行动(29个单一动作和6个交互动作)。每隔10分钟要求最多3名志愿者从上述集合中随机执行不同的动作。平均而言,每个样本包含1.54名志愿者,每个志愿者在10分钟内执行43项动作,每个动作耗时5.4秒。
我们使用20个小时的数据集进行训练,并使用5个小时进行测试。数据集还包含2种穿墙方案,其中一种用于训练,一种用于测试。在穿墙环境下,将摄像头放在墙的每一侧,以便可以使用无线电设备对摄像头系统进行校准,并利用可以看到人员的摄像头来标记动作。RF-MMD上的所有测试结果仅使用无线电信号,无需基于视觉的输入。
使用多视点摄像头系统提取3D骨架序列。首先利用AlphaPose处理摄像头系统收集的视频,提取多视图2D骨架。由于场景中可能有多个人,我们将每个视图的2D骨架关联起来,获得每个人的多视图2D骨架。由于摄像头系统已经过校准,因此可以对每个人的3D骨骼进行三角剖分。这些3D骨架作为我们的模型生成的中间3D骨架的监督。
最后,利用PKU-MMD数据集提供其他训练示例,可以进行动作检测和识别。该数据集中包含由51类、66个主体作出的近20000个动作,可以看出RF-Action是如何从基于视觉的示例中学习的。
定性结果

图5 RF-Action在各种条件下的输出。前两行为在可见场景中的表现。最下面的两行为在部分/完全遮挡和恶劣照明条件下的表现
与其他模型的性能比较
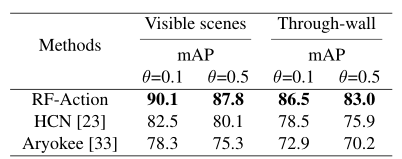
我们将RF-Action的性能与基于骨架的动作识别和基于RF的动作识别的最新模型进行了比较。我们将HCN模型作为计算机视觉中性能最高的基于骨架的动作检测系统的代表。目前该模型达到了此类任务下的最高性能。用Aryokee 作为基于RF的动作识别技术的最新代表模型。
据我们所知,这是过去唯一基于RF的动作识别系统,除了分类之外还执行动作检测。所有模型都在我们的RF动作识别数据集中进行了训练和测试。
由于HCN将骨架作为输入(与RF信号相反),我们为其提供了RF-Action生成的中间骨骼。这使我们可以在基于相同骨架的动作识别方面将RF-Action与HCN进行比较。

本文提出了首个利用无线电信号进行基于骨架的动作识别的模型,并证明了该模型能够在极端低光环境下识别墙壁后面的动作和相互作用。新模型可以在摄像机因隐私问题或能见度低而难以使用的情况下进行动作识别。因此,它可以将动作识别带入人们的家中,并允许其集成到智能家居系统中。
论文链接:
https://arxiv.org/pdf/1909.09300.pdf

高效对接AI领域项目合作、咨询服务、实习、求职、招聘等需求,背靠25W公众号粉丝,期待和你建立连接,找人找技术不再难!
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、算法竞赛、检测分割识别、三维视觉、医学影像、自动驾驶、计算摄影等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

推荐阅读
最新AI干货,我在看




