NLP专家推荐28篇2019年度最牛论文:XLNet超越BERT,谷歌FB双雄争霸

新智元推荐
【新智元导读】自然语言处理专家Elvis在medium博客上发表了关于NLP在2019年的亮点总结。对于自然语言处理(NLP)领域而言,2019年是令人印象深刻的一年。在这篇博客文章中,作者重点介绍在2019年遇到的与机器学习和NLP相关的最重要的故事。戳右边链接上 新智元小程序 了解更多!
自然语言处理专家Elvis在medium博客上发表了关于NLP在2019年的亮点总结。对于自然语言处理(NLP)领域而言,2019年是令人印象深刻的一年。在这篇博客文章中,我想重点介绍一些我在2019年遇到的与机器学习和NLP相关的最重要的故事。我将主要关注NLP,但我还将重点介绍一些与AI相关的有趣故事。标题没有特别的顺序。故事可能包括论文,工程工作,年度报告,教育资源的发布等。
-
论文刊物 -
ML / NLP创造力与社会 -
ML / NLP工具和数据集 -
文章和博客文章 -
人工智能伦理 -
ML / NLP教育
-
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut: ALBERT : A Lite BERT for Self -supervised Learning of Language Representations .ICLR 2020. -
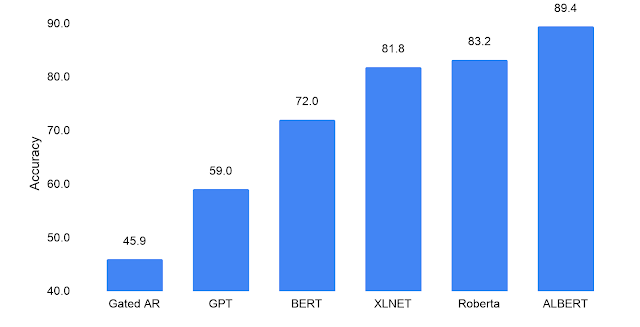
Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL-HLT (1) 2019: 4171-4186 https://arxiv.org/abs/1810.04805
-
Tero Karras, Samuli Laine, Timo Aila: A Style-Based Generator Architecture for Generative Adversarial Networks. CVPR 2019: 4401-4410 -
Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, Timo Aila: Analyzing and Improving the Image Quality of StyleGAN. CoRR abs/1912.04958 (2019)

-
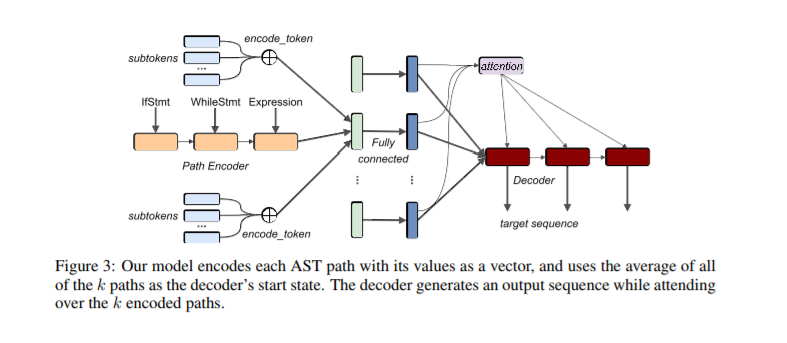
Uri Alon, Shaked Brody, Omer Levy, Eran Yahav: code2seq: Generating Sequences from Structured Representations of Code. ICLR (Poster) 2019
-
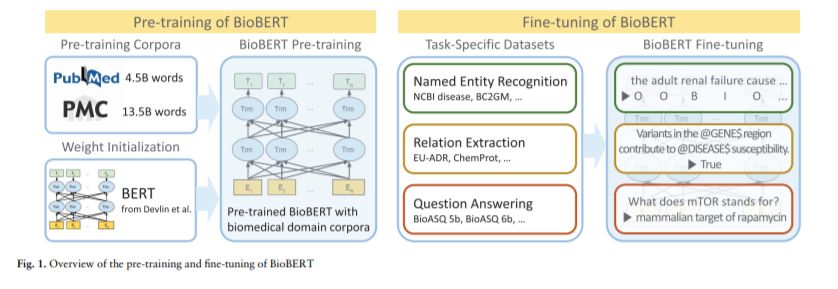
Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, Jaewoo Kang: BioBERT: a pre-trained biomedical language representation model for biomedical text mining. CoRR abs/1901.08746 (2019)
https://ai.facebook.com/blog/-teaching-ai-to-plan-using-language-in-a-new-open-source-strategy-game/
-
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov: RoBERTa: A Robustly Optimized BERT Pretraining Approach. CoRR abs/1907.11692 (2019)
-
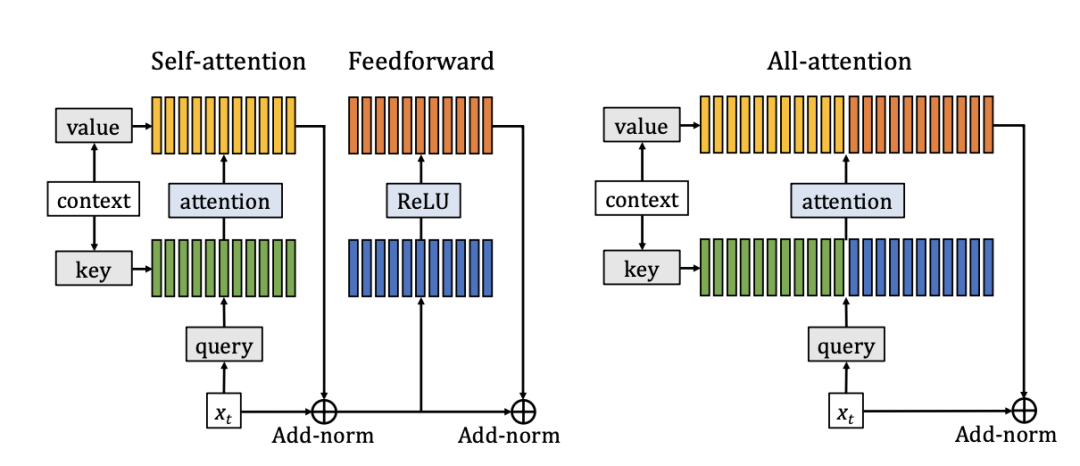
Sainbayar Sukhbaatar, Edouard Grave, Piotr Bojanowski, Armand Joulin: Adaptive Attention Span in Transformers. ACL (1) 2019: 331-335
-
Alejandro Barredo Arrieta, Natalia Díaz Rodríguez, Javier Del Ser, Adrien Bennetot, Siham Tabik, Alberto Barbado, Salvador García, Sergio Gil-Lopez, Daniel Molina, Richard Benjamins, Raja Chatila, Francisco Herrera: Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI. CoRR abs/1910.10045 (2019)
-
Ruder2019Neural, Neural Transfer Learning for Natural Language Processing, Ruder, Sebastian,2019,National University of Ireland, Galway
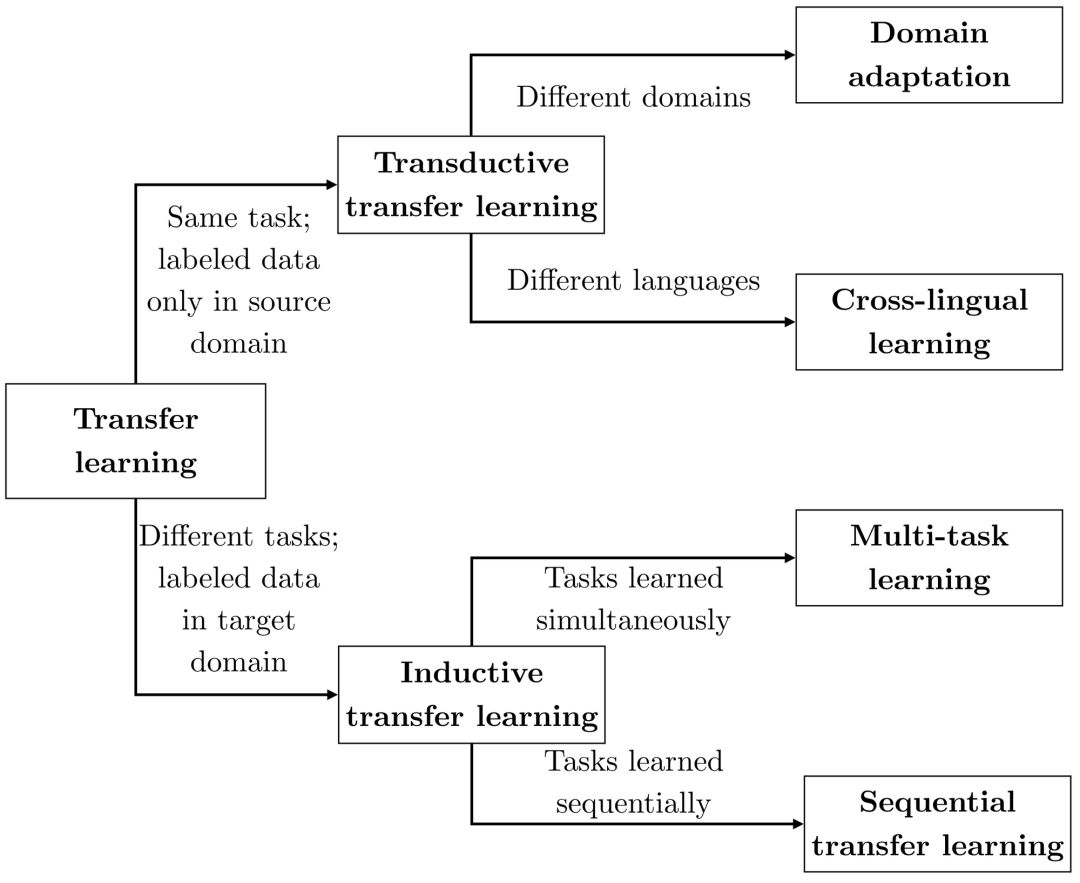
-
Devamanyu Hazarika, Soujanya Poria, Roger Zimmermann, Rada Mihalcea: Emotion Recognition in Conversations with Transfer Learning from Generative Conversation Modeling. CoRR abs/1910.04980 (2019) -
Deepanway Ghosal, Navonil Majumder, Soujanya Poria, Niyati Chhaya, Alexander F. Gelbukh: DialogueGCN: A Graph Convolutional Neural Network for Emotion Recognition in Conversation. EMNLP/IJCNLP (1) 2019: 154-164
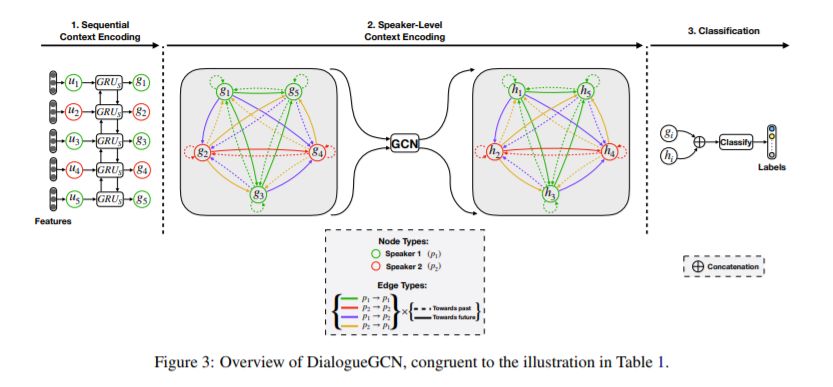
-
Arute, F., Arya, K., Babbush, R. et al. Quantum supremacy using a programmable superconducting processor. Nature 574, 505–510 (2019) doi:10.1038/s41586-019-1666-5

-
Sarah Wiegreffe, Yuval Pinter: Attention is not not Explanation. EMNLP/IJCNLP (1) 2019: 11-20
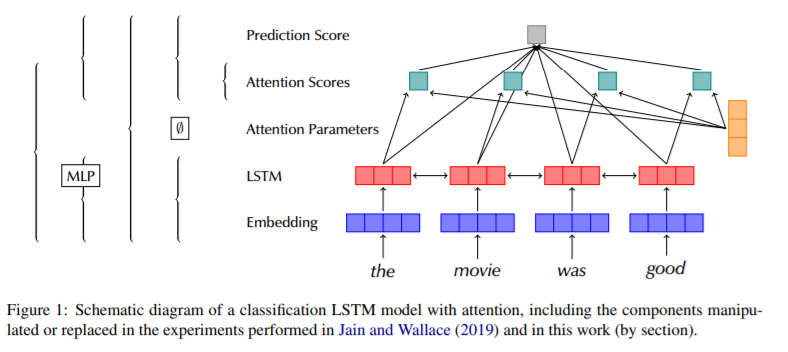
-
Honghua Dong, Jiayuan Mao, Tian Lin, Chong Wang, Lihong Li, Denny Zhou: Neural Logic Machines. ICLR (Poster) 2019
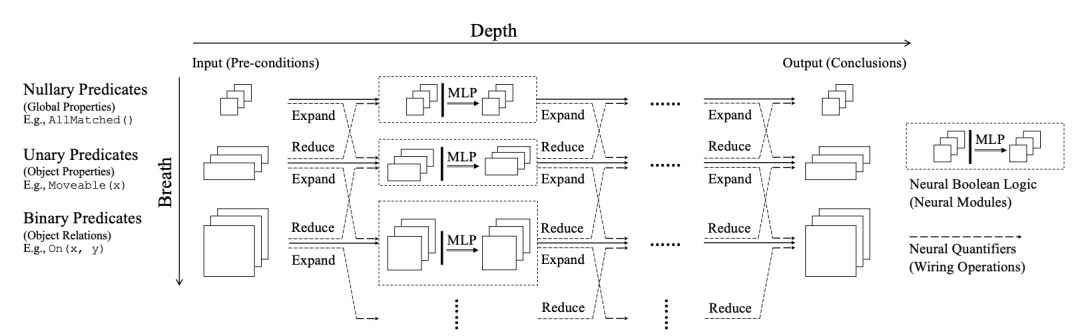
-
Sandeep Subramanian, Raymond Li, Jonathan Pilault, Christopher J. Pal: On Extractive and Abstractive Neural Document Summarization with Transformer Language Models . CoRRabs/1909.03186 (2019)
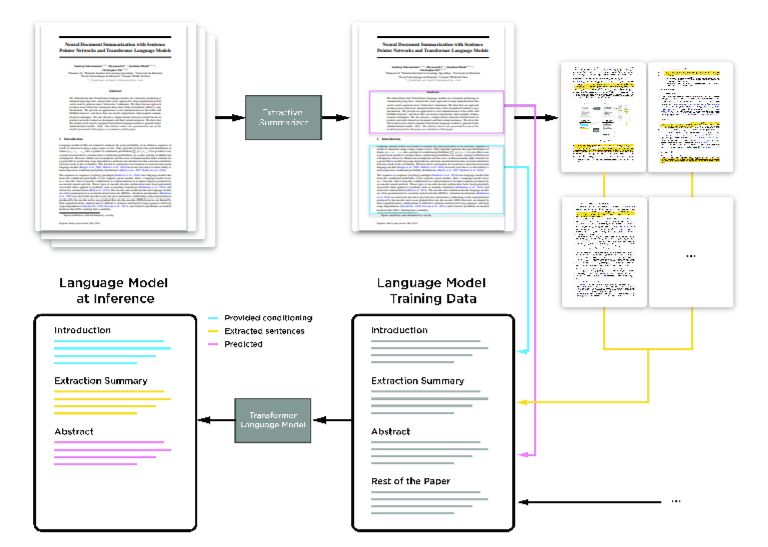
-
Nelson F. Liu, Matt Gardner, Yonatan Belinkov, Matthew E. Peters, Noah A. Smith: Linguistic Knowledge and Transferability of Contextual Representations. NAACL-HLT (1) 2019: 1073-1094
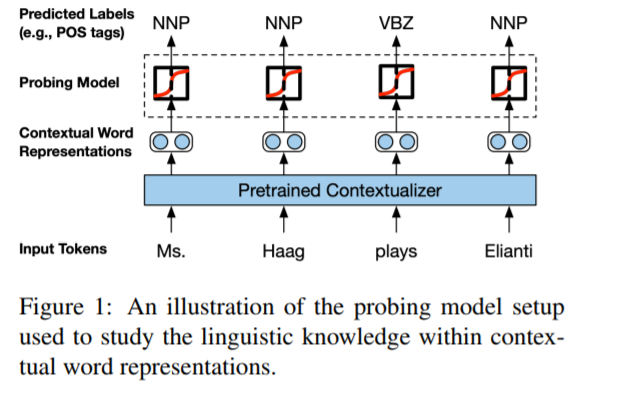
-
Zhilin Yang, Zihang Dai, Yiming Yang, Jaime G. Carbonell, Ruslan Salakhutdinov, Quoc V. Le: XLNet: Generalized Autoregressive Pretraining for Language Understanding. CoRR abs/1906.08237 (2019)
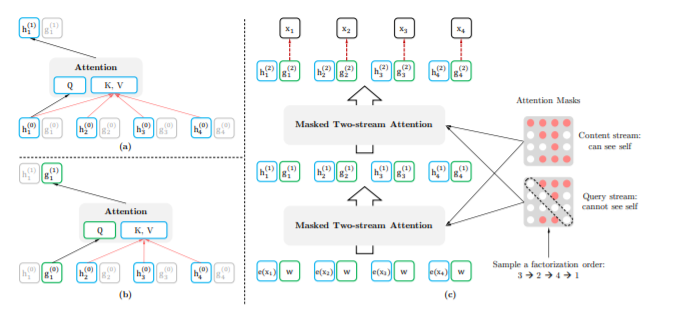
-
Dani Yogatama, Cyprien de Masson d Autume, Jerome Connor, Tomás Kociský, Mike Chrzanowski, Lingpeng Kong, Angeliki Lazaridou, Wang Ling, Lei Yu, Chris Dyer, Phil Blunsom: Learning and Evaluating General Linguistic Intelligence. CoRR abs/1901.11373 (2019)
-
Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang: VisualBERT: A Simple and Performant Baseline for Vision and Language. CoRR abs/1908.03557 (2019)
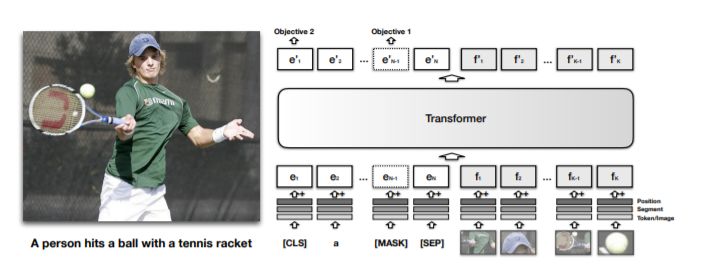
-
Matthew E. Peters, Sebastian Ruder, Noah A. Smith: To Tune or Not to Tune? Adapting Pretrained Representations to Diverse Tasks. RepL4NLP@ACL 2019: 7-14

登录查看更多
相关内容

专知会员服务
36+阅读 · 2020年4月14日
专知会员服务
69+阅读 · 2020年1月2日
Arxiv
4+阅读 · 2019年9月11日
Arxiv
15+阅读 · 2018年10月11日





相关VIP内容
专知会员服务
36+阅读 · 2020年4月14日
专知会员服务
69+阅读 · 2020年1月2日
相关资讯
相关论文
Arxiv
4+阅读 · 2019年9月11日
Arxiv
15+阅读 · 2018年10月11日