中文预训练语言模型回顾
论文名称: Revisiting Pre-trained Models for Chinese Natural Language Processing 论文作者:崔一鸣,车万翔,刘挺,秦兵,王士进,胡国平 原创作者:崔一鸣 论文链接:https://www.aclweb.org/anthology/2020.findings-emnlp.58 转载须标注出处:哈工大SCIR
1. 简介
2. 构建中文预训练系列模型
首先,我们提出了一整套的中文预训练系列模型,以构建较为完整的基线系统并为后续工作提供相对标准的参照数据。我们主要训练了以下几种预训练语言模型:
BERT-wwm:我们在谷歌原版中文BERT-base[1]的基础上,将全词掩码技术(Whole Word Masking,wwm)应用在中文环境,即在掩码语言模型(Masked Language Model,MLM)中使用词粒度进行掩码。我们使用了LTP[2]作为中文分词工具。需要注意的是,虽然掩码粒度为词,但模型的输入仍然以字为粒度(使用WordPiece分词)进行切分,即与原版BERT并无差别。
XLNet:Yang等人提出基于Transfromer-XL构建了XLNet模型[3],解决了BERT的“预训练-精调”不一致的问题,提出了Permutation Language Model。与BERT不同的是,XLNet采用了sentencepiece进行分词,因此分词粒度更大。
RoBERTa-wwm:RoBERTa模型[4]由Liu等人提出,进一步挖掘了BERT的潜力。我们训练的RoBERTa-wwm与BERT-wwm类似,但从中删除了Next Sentence Prediction(NSP)预训练任务,并使用了全词掩码技术。需要注意的是,与英文RoBERTa不同,这里我们同样使用了WordPiece分词。通过后续实验发现WordPiece相比sentencepiece在中文预训练模型中更有效。
ELECTRA:Clark等人提出一套全新的生成器-判别器架构的预训练模型ELECTRA[5],其中生成器是一个小型的MLM,用于替换输入文本。而判别器则是判断输入文本是否经过替换。由于判别器只需进行二分类,相比传统MLM来说效率更高。在下游任务精调中,我们只使用判别器。
3. MacBERT
-
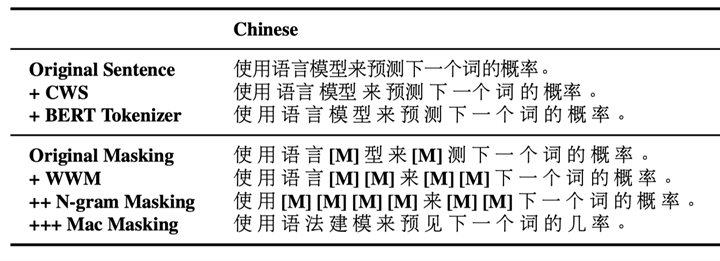
我们使用全词掩码技术以及N-gram掩码技术来选择待掩码的token,其中unigram至4-gram的概率分别为40%、30%、20%、10%。 -
为了解决[MASK]标记在下游任务中不会出现的问题,我们提出使用相似词来替换[MASK]标记。我们使用Synonyms库[6]来获取待掩码单词的相似词。在N-gram掩码时,我们针对N-gram中的每个词均进行相似词替换。在少数情况下,当相似词不存在时,我们将使用词表中的随机词进行替换。 -
与原版BERT类似,我们对输入序列总长度15%的token进行掩码,其中80%的情况下会替换为相似词,10%的情况下会替换为随机词,剩余10%则不进行任何替换(负样本)。
表1 不同掩码方式的对比
4. 实验
4.1. 预训练模型设置
接下来简要介绍预训练模型的训练设置,详细内容请参考论文的4.1节。
预训练数据:我们采用了中文维基百科数据(同时保留简体和繁体中文)以及额外爬取的中文数据(包括百科、问答、新闻等),总词数达到了5.4B。在模型中我们以ext标记采用扩展数据的BERT或RoBERTa模型。
基本参数:我们对所有模型(除XLNet)采用了统一预训练词表,与原版中文BERT-base相同,包含21128个token。序列最大长度设置为512。
训练设备:根据模型规模大小,我们采用了单个TPU v3或者TPU v3-32进行训练。
4.2. 下游精调数据集
我们选用了以下8个中文自然语言处理数据集:
阅读理解:CMRC 2018[8],DRCD[9],CJRC[10]
单句文本分类:ChnSentiCorp[11],THUCNews[12]
句对文本分类:XNLI[13],LCQMC[14],BQ Corpus[15]
为了保证结果的稳定性,对于每一组实验结果,我们均运行10次,并汇报其平均值和最大值。相关实验超参设置请参考论文的表2。
4.3. 实验结果
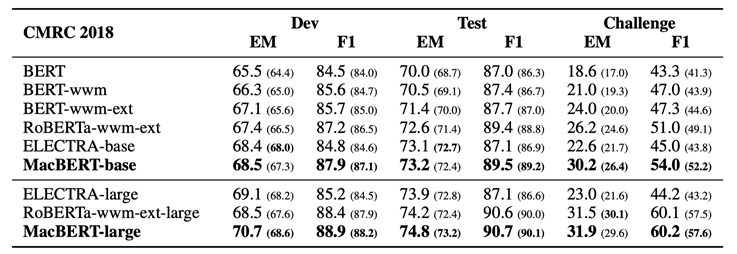
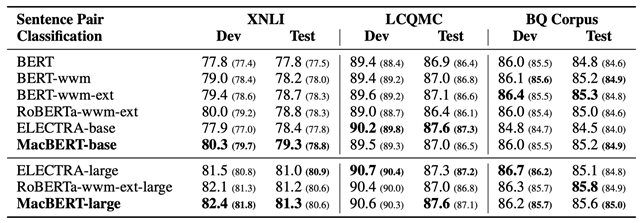
本文涉及的预训练模型的部分实验结果如下表所示(详细结果请参考论文4.3节)。可以看到MacBERT在多数任务上取得了显著性能提升,尤其在机器阅读理解的各项任务中的提升更为明显。
4.4. 消融实验
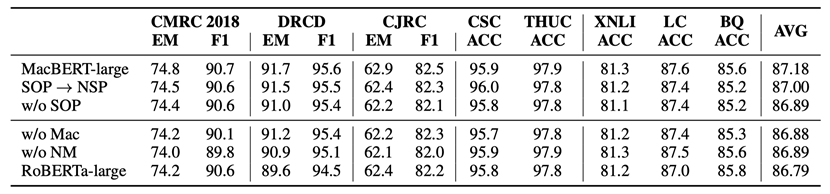
为了进一步了解性能提升的来源,我们对MacBERT-large进行了消融实验。可以看到,整个模型中最重要的部分是纠错型掩码语言模型(Mac)和N-gram掩码语言模型(NM),而相对来说模型使用NSP还是SOP预训练任务并没有对模型性能造成很大影响,因此后续工作应进一步将重点放在掩码语言模型及其变种模型的设计上。
表4 MacBERT模型上的消融实验结果
5. 讨论
前面提到MLM任务是这类预训练语言模型最重要的组成部分。MLM类任务包括两个方面:1)如何选择需要掩码的token;2)待掩码的token替换成什么。
在前面的章节中,我们已经展示了不同的选择掩码token的方法,例如全词掩码、N-gram掩码等。现在我们将探索第二个方面,即探索“待掩码的token替换成什么”。我们在CMRC 2018和DRCD数据集上进行了验证。在15%的整体掩码比例下,其中的10%将保持不变(负样例),而剩余的90%将采取如下4类方案进行对比。
MacBERT:80%的词替换成相似词,10%替换为随机词;
随机替换:90%的词替换为随机词;
部分MASK:(BERT原始MLM)80%替换为[MASK],10%替换为随机词;
全部MASK:90%的词替换为[MASK]。
实验结果如下图所示。可以看到依赖于替换成[MASK]的实验设置(例如部分MASK和全部MASK)下效果相对较差,说明“预训练-精调”不一致的确会为下游任务带来一定的性能下降。而简单地将所有待掩码的词替换为随机词后,其性能显著优于依赖[MASK]的MLM方法。最后,我们使用相似词进行进一步优化后,其性能还会得到显著提升,说明MacBERT设计是有效的。
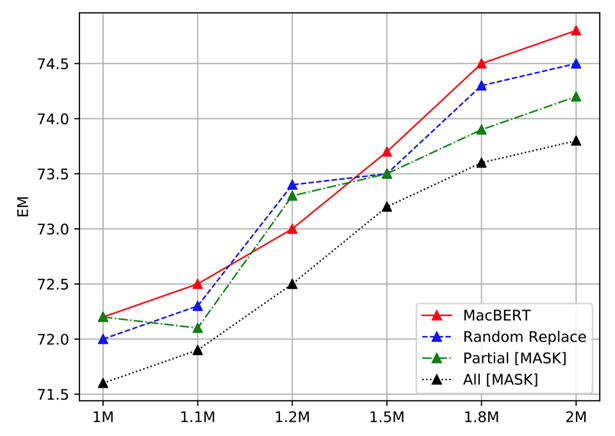
图1 不同掩码设置下的CMRC 2018效果
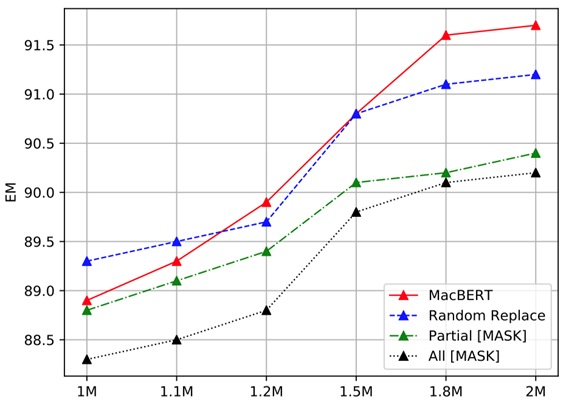
图2 不同掩码设置下的DRCD效果
6. 结论
在本文中,我们回顾了经典预训练语言模型在中文场景下的性能表现,以验证这些模型在非英文语种上的通用性。同时我们提出了一种基于文本纠错的预训练语言模型MacBERT,解决了预训练模型中的“预训练-精调”不一致的问题。大量实验结果表明所提出的MacBERT能够在多数任务上带来显著性能提升。我们已将所有与本文相关的中文预训练语言模型开源,并希望能够进一步促进中文信息处理的研究与发展。基于我们在文章最后的分析讨论,未来我们将探索一种有效调整掩码比例的方法以取代手工设置的方案,从而进一步提升预训练语言模型的性能表现。
7. 参考文献
[1] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In NAACL 2019.
[2] Wanxiang Che, Zhenghua Li, and Ting Liu. LTP: A chinese language technology platform. In COLING 2010.
[3] Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, and Quoc V Le. Xlnet: Generalized autoregressive pretraining for language understanding. arXiv preprint arXiv:1906.08237.
[4] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
[5] Kevin Clark, Minh-Thang Luong, Quoc V. Le, and Christopher D. Manning. ELECTRA: Pretraining text encoders as discriminators rather than generators. In ICLR.
[6] Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. Albert: A lite bert for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942.
[7] Hailiang Wang and Yingxi Hu. 2017. Synonyms. https://github.com/huyingxi/Synonyms [8] Yiming Cui, Ting Liu, Wanxiang Che, Li Xiao, Zhipeng Chen, Wentao Ma, Shijin Wang, and Guoping Hu. A Span-Extraction Dataset for Chinese Machine Reading Comprehension. In EMNLP 2019.
[8] Chih Chieh Shao, Trois Liu, Yuting Lai, Yiying Tseng, and Sam Tsai. Drcd: a chinese machine reading comprehension dataset. arXiv preprint arXiv:1806.00920.
[9] Xingyi Duan, Baoxin Wang, Ziyue Wang, Wentao Ma, Yiming Cui, Dayong Wu, Shijin Wang, Ting Liu, Tianxiang Huo, Zhen Hu. Cjrc: A reliable human-annotated benchmark dataset for chinese judicial reading comprehension. In CCL 2019.
[10] Songbo Tan and Jin Zhang. 2008. An empirical study of sentiment analysis for chinese documents. Expert Systems with applications, 34(4):2622–2629.
[11] Jingyang Li and Maosong Sun. Scalable term selection for text categorization. In EMNLP 2007.
[12] Alexis Conneau, Ruty Rinott, Guillaume Lample, Adina Williams, Samuel R. Bowman, Holger Schwenk, and Veselin Stoyanov. Xnli: Evaluating crosslingual sentence representations. In EMNLP 2018.
[13] Xin Liu, Qingcai Chen, Chong Deng, Huajun Zeng, Jing Chen, Dongfang Li, and Buzhou Tang. Lcqmc: A large-scale chinese question matching corpus. In COLING 2018.
[14] Jing Chen, Qingcai Chen, Xin Liu, Haijun Yang, Daohe Lu, and Buzhou Tang. The BQ corpus: A large-scale domain-specific Chinese corpus for sentence semantic equivalence identification. In EMNLP 2018.
长按下图即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公众号『哈工大SCIR』。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CPTM” 就可以获取《中文预训练语言模型回顾》专知下载链接





