干货 | AAAI 2018 论文预讲:当强化学习遇见自然语言处理有哪些奇妙的化学反应?
AI科技评论按:随着强化学习在机器人和游戏 AI 等领域的成功,该方法也引起了越来越多的关注。在近期 GAIR 大讲堂上,来自清华大学计算机系的博士生冯珺,为大家介绍了如何利用强化学习技术,更好地解决自然语言处理中的两个经典任务:关系抽取和文本分类。 本文根据视频直播分享整理而成,内容若有疏漏,以原视频嘉宾所讲为准。
视频回放地址:http://www.mooc.ai/open/course/318(点击阅读原文直达)
在关系抽取任务中,尝试利用强化学习,解决远程监督方法自动生成的训练数据中的噪音问题。在文本分类任务中,利用强化学习得到更好的句子的结构化表示,并利用该表示得到了更好的文本分类效果。本次分享的两个工作均发表于 AAAI2018。
冯珺,清华大学计算机系博士五年级,师从朱小燕和黄民烈教授,主要研究方向为知识图谱,强化学习。目前已在 AAAI,COLING,WSDM 等国际会议上发表多篇文章。
分享内容
大家好,我是来自清华大学的冯珺,分享的主题是当强化学习遇见自然语言处理,分享内容主要是以下三方面:
强化学习基本概念简要介绍
基于强化学习的关系抽取方法,解决远程监督方法自动生成的训练数据中的噪音问题
基于强化学习的句子结构化表示学习方法

强化学习的基本概念
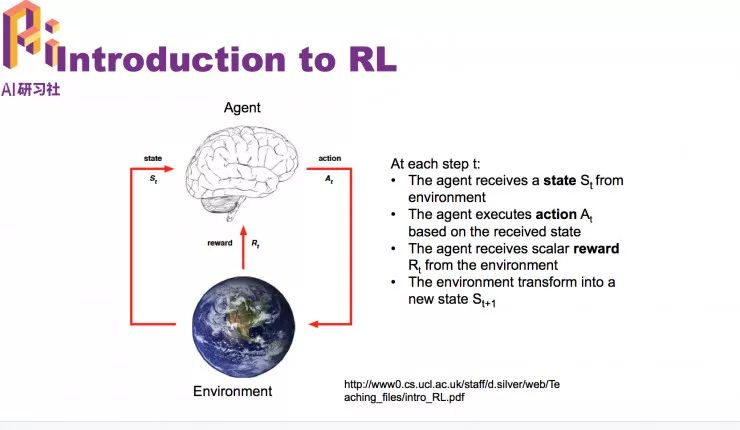
状态,是 agent 从环境中得到的动作;agent,是基于它得到的当前状态后做出相应的动作。reward ,是环境给agent 的一个反馈,收到这个reward就知道做的这个动作是好还是不好。agent 的目标就是选动作,将全部reward最大化。
agent会和环境做很多的交互,环境每次做的动作可能会有一个长期的影响,而不仅仅是影响当前的 reward。reward 也有可能延迟。在这里简单介绍一下 policy 的概念。policy 是决定一个 agent 的动作的一个函数。

如果读者对上述概念还不清楚可以观看视频中的迷宫例子。
我们组做的两个工作是关系抽取和文本分类。
首先是第一个工作:利用增强学习从噪声数据中进行关系抽取 (Reinforcement Learning for Relation Classification from Noisy Data)

任务背景
关系分类任务需要做的是,判断实体之间是什么关系,句子中包含的实体对儿是已知的。关系分类任务是强监督学习,需要人工对每一句话都做标注,因此之前的数据集比较小。
之前也有人提出 Distant Supervision 方法,希望能利用已有资源对句子自动打上标签,使得得到更大的数据集。但这种方法是基于已有知识图谱中的实体关系来对一句话的实体关系进行预测,它的标注未必正确。

这篇文章就是用强化学习来解决这个问题。之前也有一些方法是基于 multi-instance learning 的方法来做的。

这样做的局现性是不能很好处理句级预测。
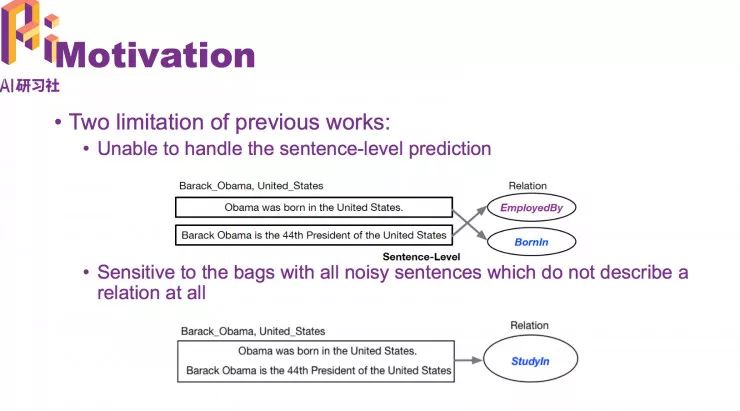
基于以上不足,我们设定了新模型。包括两个部分: Instance Selector 和 Relation Calssifier。
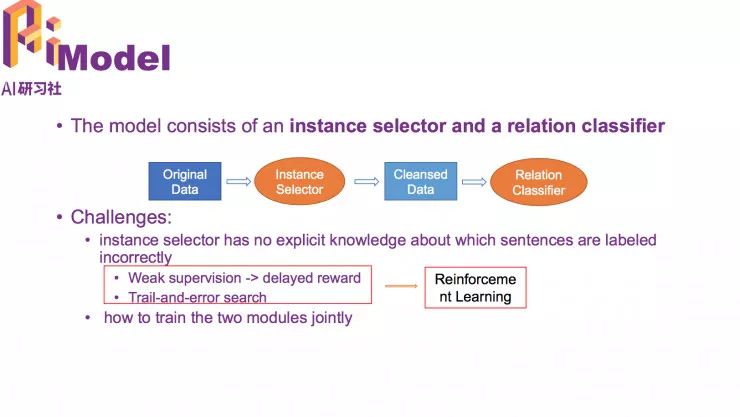
这个模型有两个挑战,第一是不知道每句话的标注是否正确‘;第二个挑战是怎么将两个部分合到一块 ,让它们互相影响。
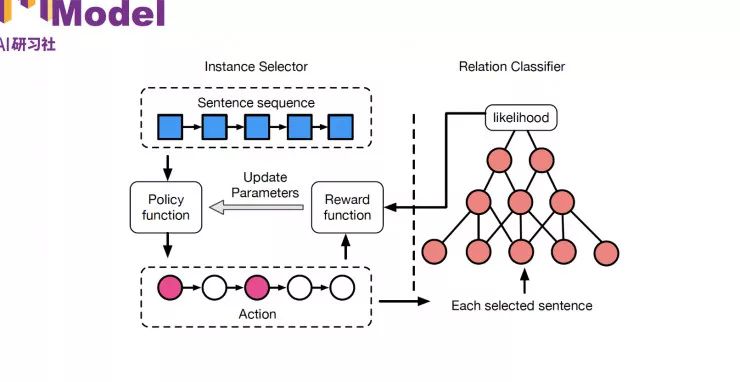
Instance Selector 和 Relation Calssifier 的结构图
在 Instance Selector 中的“状态”就表示为,当前的句子是哪一句,之前选了哪些句子,以及当前句子包含的实体对儿。

Relation Classifier 是直接用了一个CNN的结构得到句子的表示。


模型训练步骤

实验部分关于数据集和baseline来源
总结
我们提到一个新的模型,在有噪声的情况下也能句子级别的关系分类,而不仅仅是 bags 级别的关系预测。

第二个任务

任务背景
如果做一个句子分类,首先要给句子做一个表示 ,经过 sentence representation 得到句子表示,把“表示”输入分类器中,最终就会得到这个句子属于哪一类。
传统的 sentence representation 有以下几个经典模型:
bag-of-words
CNN
RNN
加入注意力机制的方法
以上几种方法有一个共同的不足之处,完全没有考虑句子的结构信息。所有就有第五种 tree-structured LSTM。
不过这种方法也有一定的不足,虽然用到了结构信息,但是用到的是需要预处理才能得到的语法树结构。并且在不同的任务中可能都是同样的结构,因为语法都是一样的。
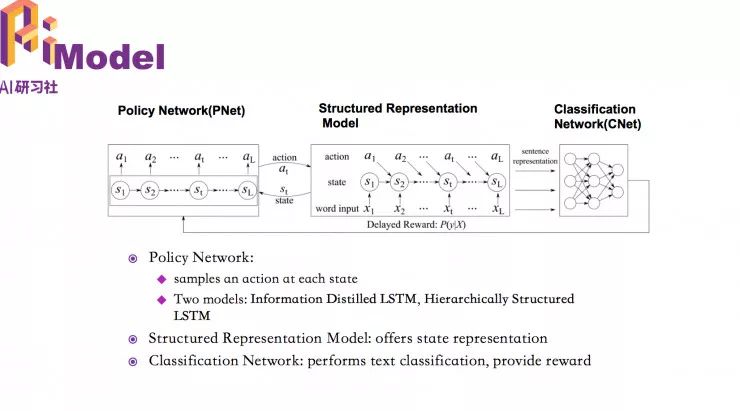
所以我们希望能够学到和任务相关的结构,并且基于学到的结构给句子做表示,从而希望能得到更好的分类结构。但面临的挑战是我们并不知道什么样的结构对于这个任务是好的,我们并没有一个结构标注能够指导我们去学这个结构。但我们可以根据新的结构做出的分类结果好不好从而判断这个结构好不好。

这个任务同样可以建模为强化学习问题,用强化学习的思想来解。同样的,在这个任务中的 reward 也是有延迟的,因为需要把整个结构都学到后,才能得到句子的表示,才能用句子的表示做分类,中间的过程是不知道这个结构是好的还是不好的。

实验部分的数据集来源
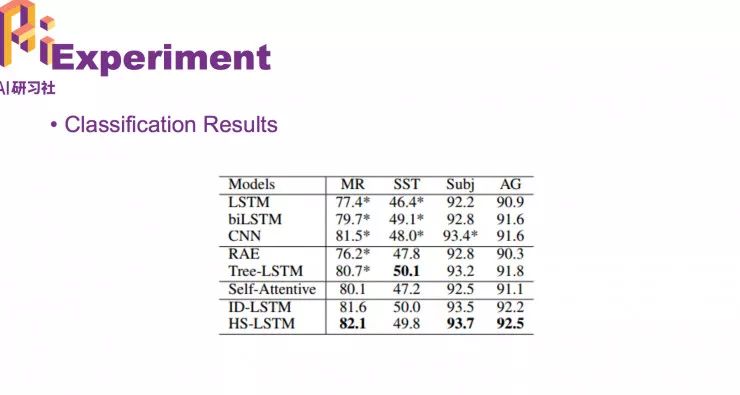
实验的分类结果;最后两行是我们的方法。


总结
在这个工作中,我们学习了跟任务相关的句子结构,基于句子机构得到了不同的句子表示,并且得到个更好的文本分类方法。我们提出两种不同的表示方法,ID-LSTM 和 HS-LSTM。这两个表示也得到了很好的分类结果,得到了非常有意思的和任务相关的表示 。
完整回放视频可点击阅读原文或复制链接查看 :
http://www.mooc.ai/open/course/318
————— 新人福利 —————
关注AI 科技评论,回复 1 获取
【数百 G 神经网络 / AI / 大数据资源,教程,论文】
————— AI 科技评论招人了 —————
AI 科技评论期待你的加入,和我们一起见证未来!
现诚招学术编辑、学术兼职、学术外翻
详情请点击招聘启事
————— 给爱学习的你的福利 —————
上海交通大学博士讲师团队
从算法到实战应用,涵盖CV领域主要知识点;
手把手项目演示
全程提供代码
深度剖析CV研究体系
轻松实战深度学习应用领域!
立即扫码详细了解
▼▼▼

————————————————————





