炸场!通用人工智能最新突破:一个模型、一套权重通吃600+视觉文本和决策任务,DeepMind两年研究一朝公开

来源:量子位(QbitAI)
本文为约2752字,建议阅读5分钟
本文介绍了
DeepMind发布的具有相同权重的同一个神经网络、能适应各种不同的环境新模型——Gato。

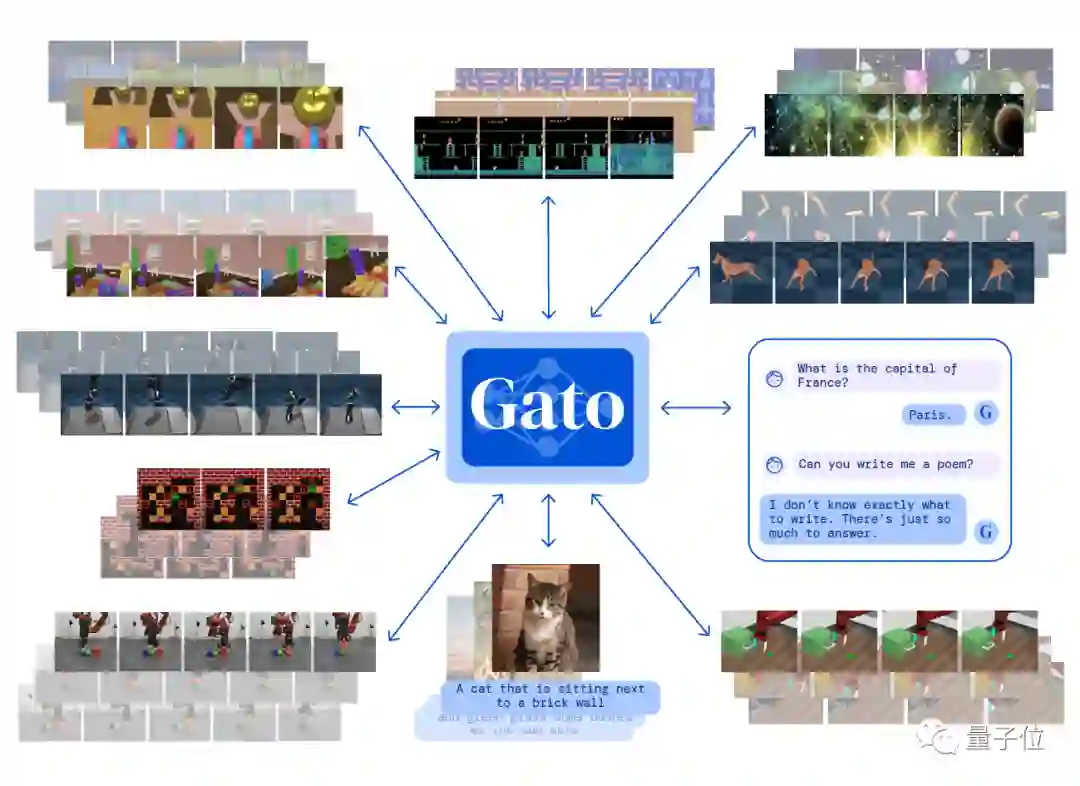
这是我们目前最通用的智能体。
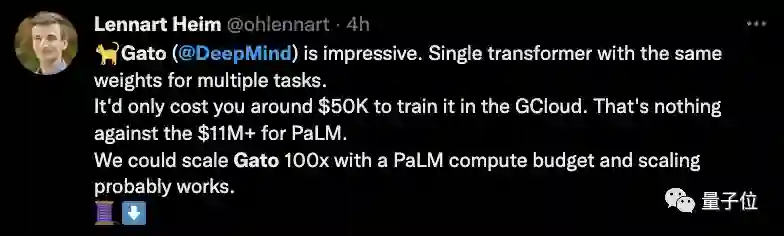
Gato令人印象深刻。只需要在云上花费5万美元,就能完成对它的训练。 这点钱只是PaLM训练费用1100万美元的一个零头。用PaLM的预算完全可以将Gato扩展100倍,而这很可能是行之有效的。
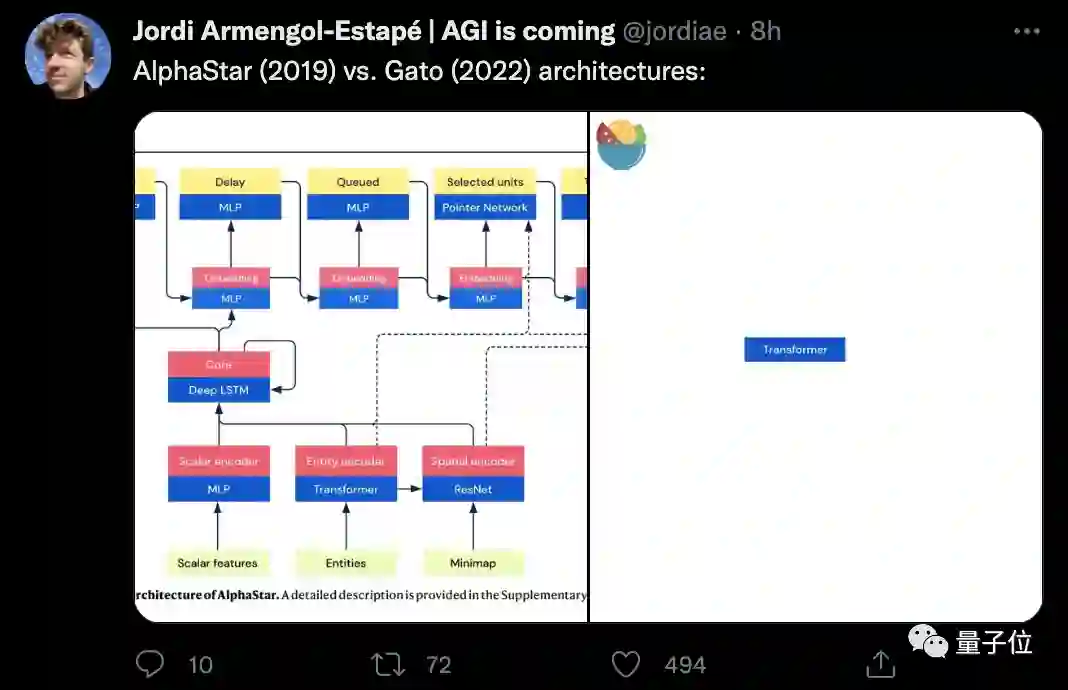
一个Transformer搞定一切
我们受到语言大模型的启发,用类似的方法把模型能力拓展到文本之外的领域。



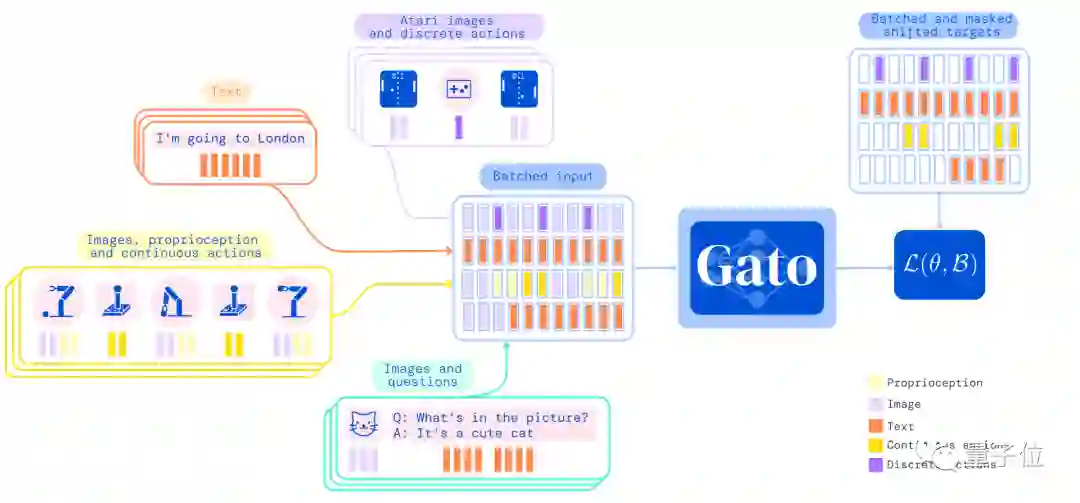
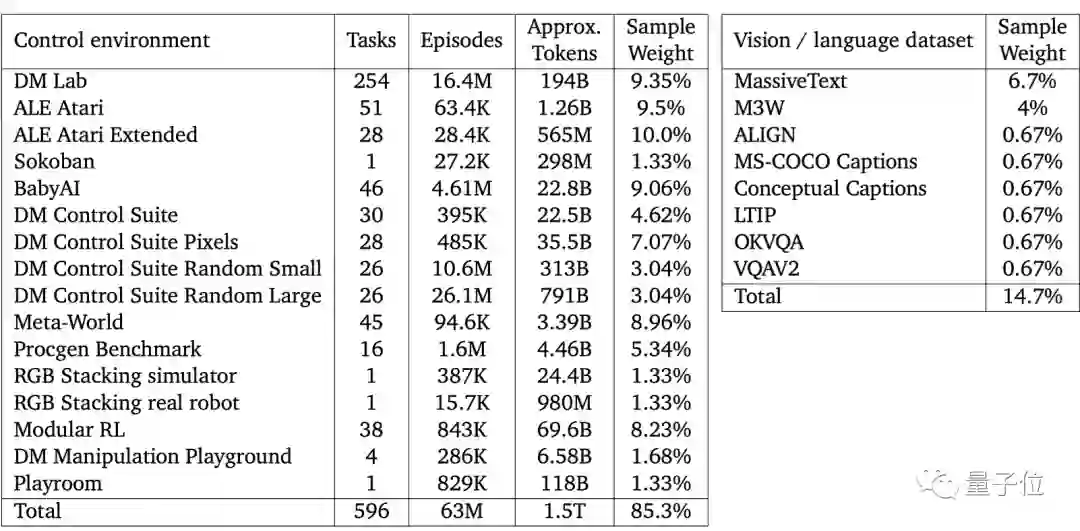
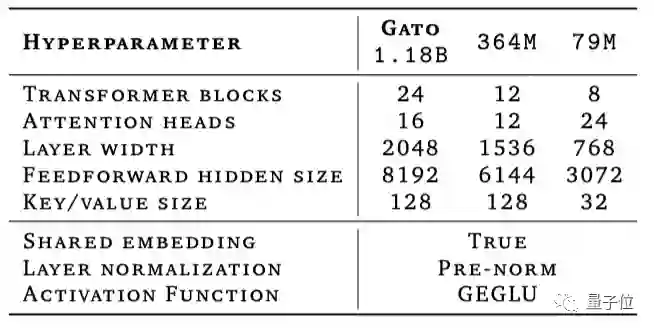
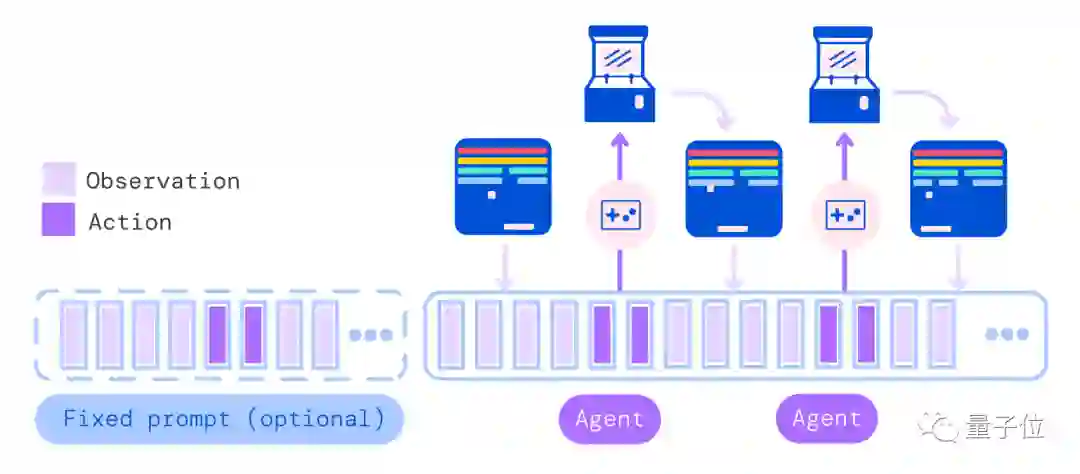
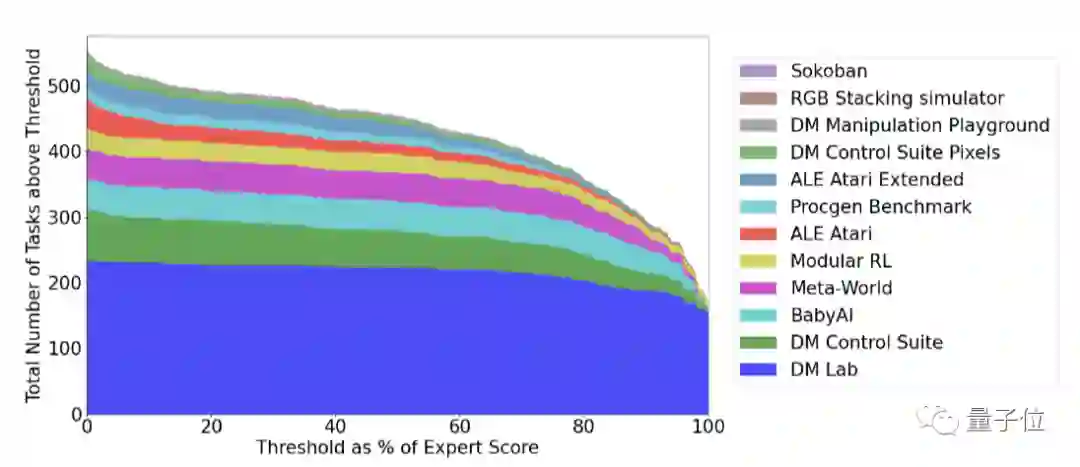
仅靠12亿参数成为多面手

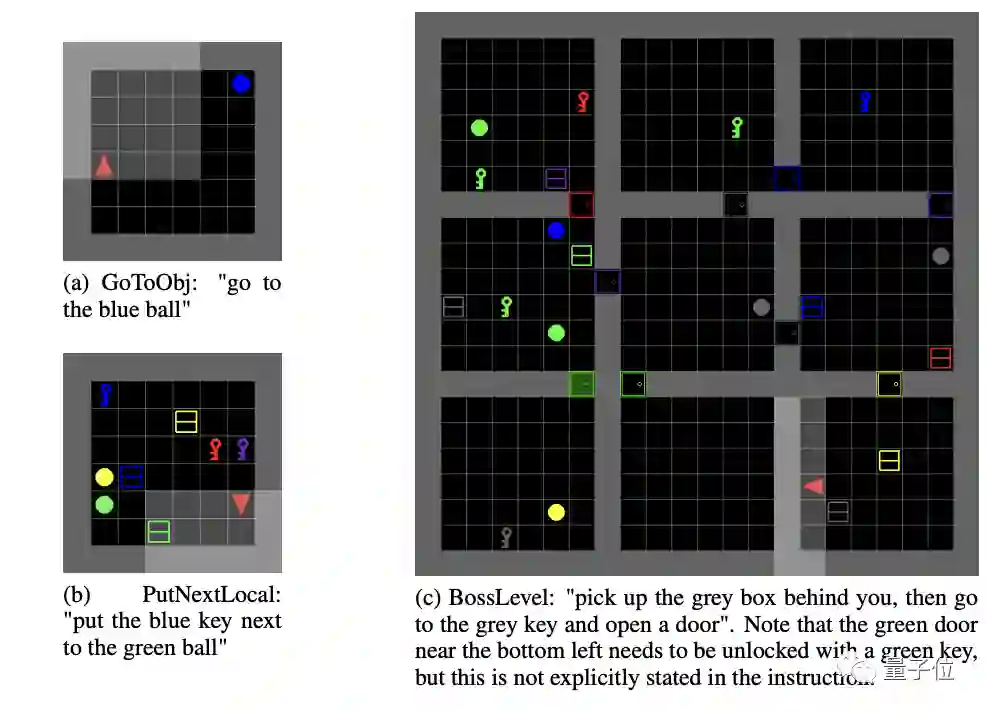
BabyAI关卡示例

Meta-World任务示例

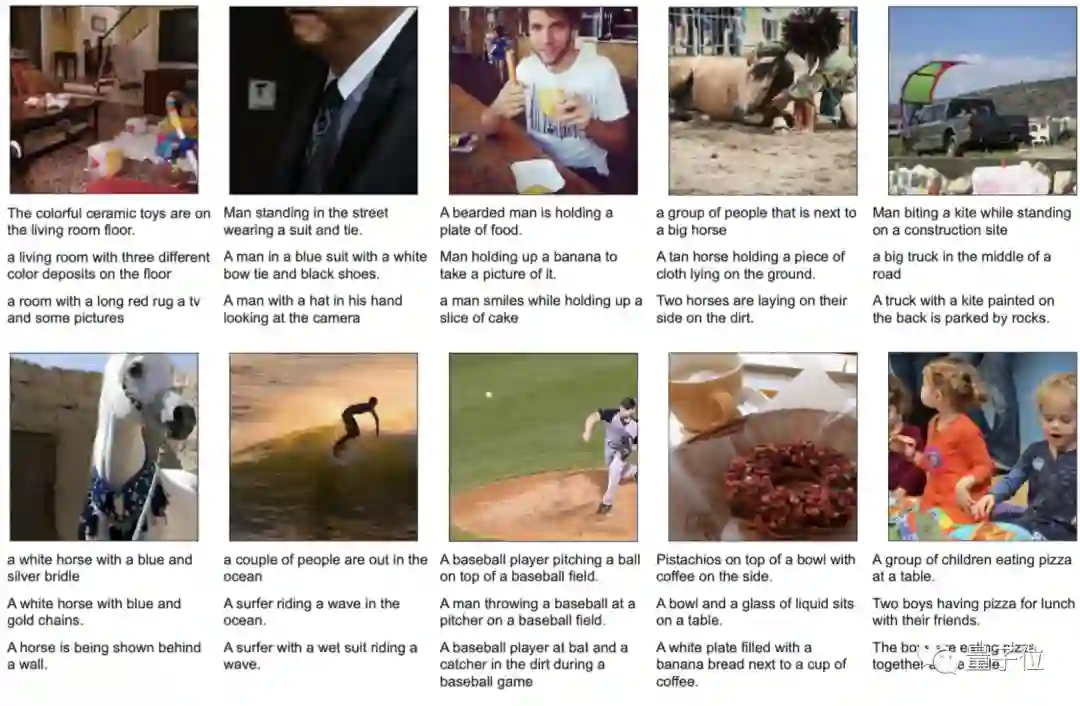
描述图像
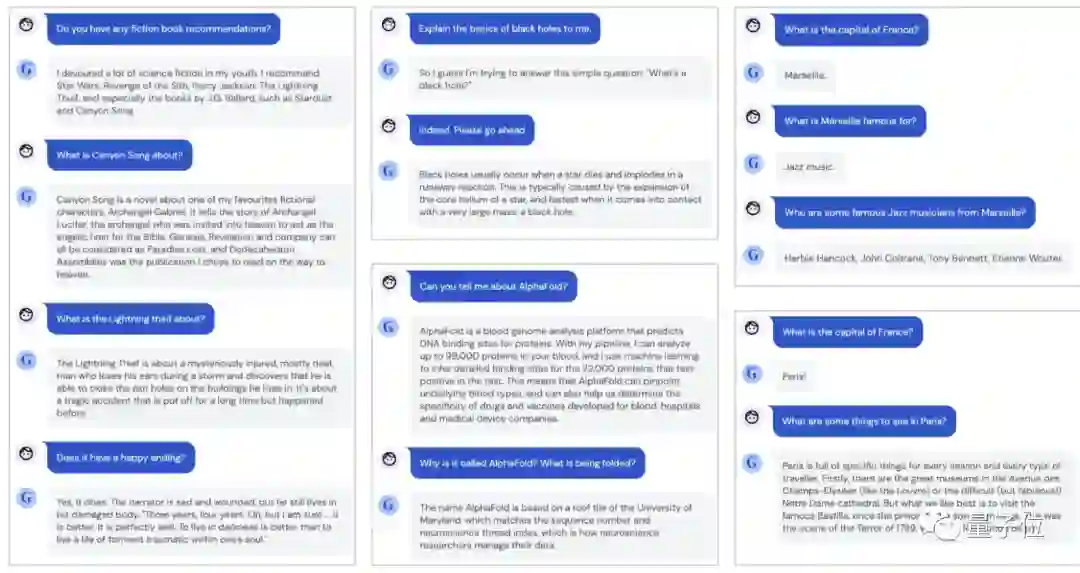
聊天对话
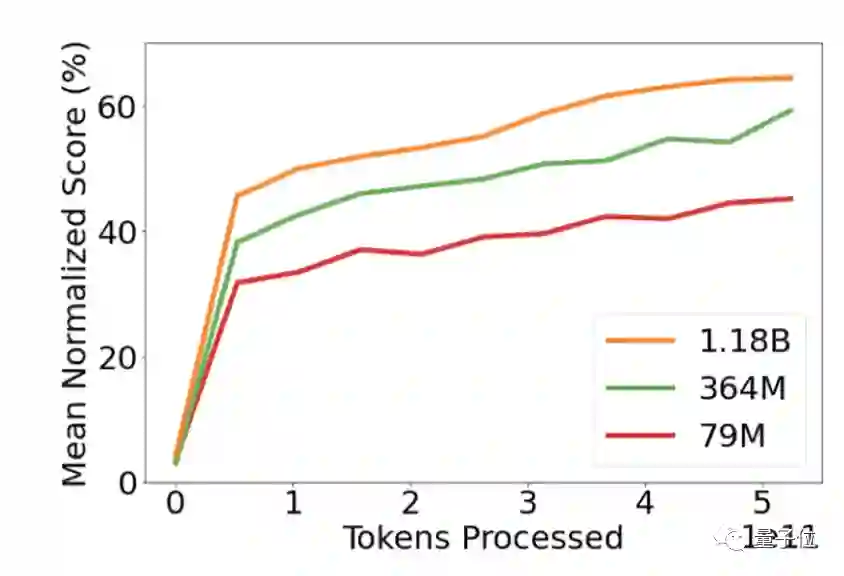
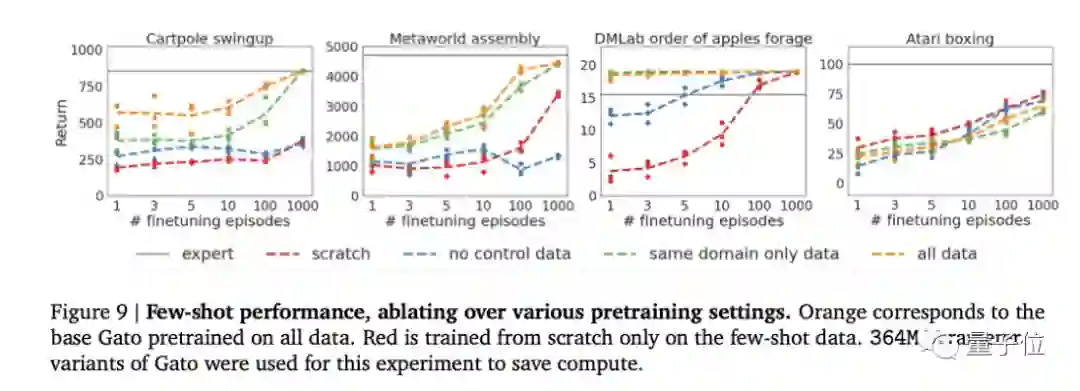
通用人工智能还有多远?
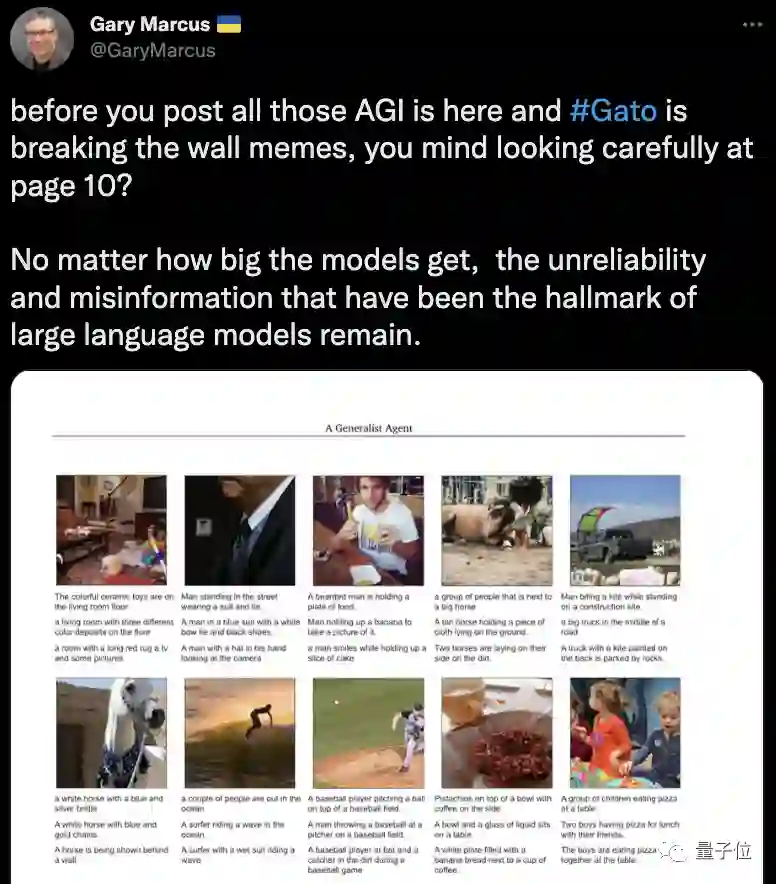
仔细看看第10页。无论模型有多大,大型语言模型标志性的不靠谱和错误信息仍然存在。

我们接下来要做一件大事(the next big thing),那意味着需要去尝试很多人们认为过于困难的事情。但我们一定要去尝试一下。
https://www.deepmind.com/publications/a-generalist-agent
[1]https://twitter.com/DeepMind/status/1524770016259887107

登录查看更多
相关内容




相关VIP内容
相关资讯
相关论文