DeepMind把GAN玩出新花样!基于BigGAN,生成高保真视频

新智元报道
新智元报道
来源:venturebeat
编辑:大明
【新智元导读】DeepMind把GAN又玩出了新花样!这次推出的是双视频判别器GAN,通过对判别器更高效的分解,生成的视频样本在长度和分辨率上都远高于此前最好水平,在多个合成和预测视频数据集上刷新了SOTA。
也许你听说过FaceApp,这是一款利用AI来改变自拍的移动应用程序,你可能也听说过“这些人物都不存在”网站,它可以显示计算机生成的虚构人物照片。但是生成完完全全的新视频的算法你听说过吗?最近,DeepMind的一篇最新论文详细介绍了AI剪辑生成领域的最新进展。

论文地址:
https://arxiv.org/pdf/1907.06571.pdf
研究人员表示,由于“高效计算”组件和技术的使用,再加上新的定制数据集,他们训练出的最佳性能模型:双视频鉴别器GAN(DVD-GAN)可以生成“高保真度”的连贯256 x 256像素视频,帧数高达48帧。
DVD-GAN这个简称由Ian Goodfellow“钦定”
“生成自然视频对于生成建模任务来说是一个明显更困难的挑战,受到数据复杂性和计算要求增加的困扰,”共同作者写道。“出于这个原因,许多关于视频生成的先前研究都围绕着相对简单的数据集或可获得强时间条件信息的任务。我们的研究则关注视频合成和视频预测的任务......并将生成图像模型的成果扩展到视频领域。”
研究人员围绕尖端AI架构构建系统,并专门针对视频进行了特定的调整,使其能够在Kinetics-600上进行训练,这是一个比常用语料库大一个数量级的自然视频数据集。具体来说,研究人员利用扩大的生成对抗网络(GAN),它已应用于多种转换任务,比如将字幕转换为逐个场景的情节板,生成人造星系的图像等。本文中采用的是BigGAN,以大批量和数百万个参数而著称。
一组4秒合成视频剪辑,由Kinetics-600在128×128帧上训练
DVD-GAN包含两个判别器:一个空间判别器,通过随机采样全分辨率帧并单独处理,来评判单帧的内容和结构,还有一个是时间判别器,负责提供学习信号来生成运动。此外还有一个单独的模块:变换器,让学习到的信息在整个AI模型中传播。
至于训练数据集(Kinetics-600),这是根据最初为人类行为识别策划的500,000个10秒高分辨率YouTube剪辑编制的,研究人员称该数据集具有“多样化”和“非受限”的特点,他们声称这些特征消除了过拟合的风险。(在机器学习中,过拟合是指与特定数据集过于紧密对应的模型,因此无法可靠地预测未来的观测结果。)
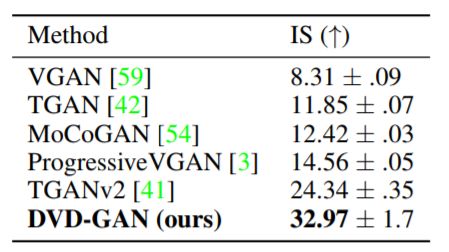
该团队在论文中表示,在经过Google加速的第三代TPU训练12到96小时后,DVD-GAN成功创建了包括目标结构、移动,甚至是复杂纹理的视频。模型还尽力在更高的分辨率下创建连贯的物体,物体的运动组成像素更多。但研究人员指出,在UCF-101(13,320个人类行为视频的较小数据集)上评估时,DVD-GAN生成的样本的最好成绩分数为32.97。

“我们希望进一步强调在大型复杂视频数据集(如Kinetics-600)上训练生成模型的好处,”论文中写道。“我们想通过DVD-GAN在此数据集上建立的强大基线标准,作为生成建模社区的参考标杆。虽然在非约束的环境下,要想始终如一地生成逼真的视频还有很多工作要做,但我们相信,DVD-GAN是朝这个方向迈出的坚实一步。”
参考链接:
https://venturebeat.com/2019/07/19/deepminds-ai-learns-to-generate-realistic-videos-by-watching-youtube-clips/
论文地址:
https://arxiv.org/pdf/1907.06571.pdf



