深度学习加速不香吗?| 基于混合精度加速你知道多少?
点击蓝字关注我们


扫码关注我们
公众号 : 计算机视觉战队
加入我们,大量论文代码下载链接
上次我们推送了混合精度,有同学提意见多说一些,今天我们重新推送一下,接下来我们几期都来说说加速的 技术,有兴趣的同学我们一起来学习讨论!
背景
单精度、双精度和半精度浮点格式之间的区别
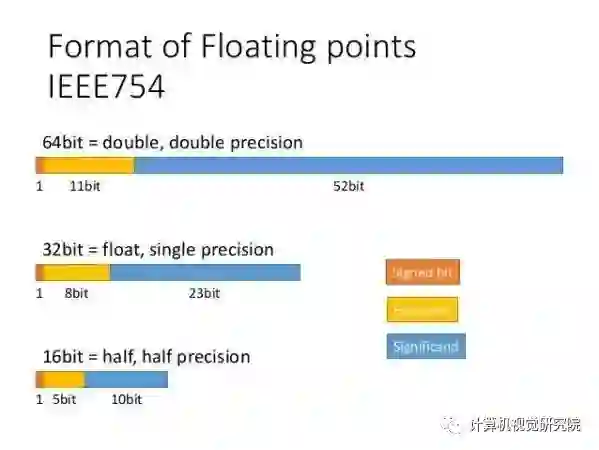
IEEE 浮点算术标准是用来衡量计算机上以二进制所表示数字精度的通用约定。在双精度格式中,每个数字占用64位,单精度格式占用32位,而半精度仅16位。
要了解其中工作原理,我们可以拿圆周率举例。在传统科学记数法中,圆周率表示为3.14 x100。但是计算机将这些信息以二进制形式存储为浮点,即一系列的1和0,它们代表一个数字及其对应的指数,在这种情况下圆周率则表示为1.1001001 x 21。
在单精度32位格式中,1位用于指示数字为正数还是负数。指数保留了8位,这是因为它为二进制,将2进到高位。其余23位用于表示组成该数字的数字,称为有效数字。
而在双精度下,指数保留11位,有效位数为52位,从而极大地扩展了它可以表示的数字范围和大小。半精度则是表示范围更小,其指数只有5位,有效位数只有10位。
圆周率在每个精度级别表现如下:

多精度和混合精度计算的差异
多精度计算意味着使用能够以不同精度进行计算的处理器,在需要使用高精度进行计算的部分使用双精度,并在应用程序的其他部分使用半精度或单精度算法。
混合精度(也称为超精度)计算则是在单个操作中使用不同的精度级别,从而在不牺牲精度的情况下实现计算效率。
在混合精度中,计算从半精度值开始,以进行快速矩阵数学运算。但是随着数字的计算,机器会以更高的精度存储结果。例如,如果将两个16位矩阵相乘,则结果为32位大小。
使用这种方法,在应用程序结束计算时,其累积得到结果,在准确度上可与使用双精度算法运算得到的结果相媲美。
这项技术可以将传统的双精度应用程序加速多达25倍,同时减少了运行所需的内存、时间和功耗。它可用于 AI 和模拟 HPC 工作负载。
随着混合精度算法在现代超级计算应用程序中的普及,HPC 专家 Jack Dongarra 提出了一个新的基准,即 HPL-AI,以评估超级计算机在混合精度计算上的性能。当 NVIDIA 在全球最快的超级计算机 Summit 上运行 HPL-AI 计算时,该系统达到了前所未有的性能水平,接近550 petaflop,比其在 TOP500 榜单上的官方性能快了3倍。
理论
PyTorch实现
from apex import amp
model, optimizer = amp.initialize(model, optimizer, opt_level="O1") # 这里是“欧一”,不是“零一”
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()但是如果你希望对FP16和Apex有更深入的了解,或是在使用中遇到了各种不明所以的“Nan”的同学,可以接着读下去,后面会有一些有趣的理论知识和瓦砾最近一个月使用Apex遇到的各种bug,不过当你深入理解并解决掉这些bug后,你就可以彻底摆脱“慢吞吞”的FP32啦。
理论部分
什么是FP16?
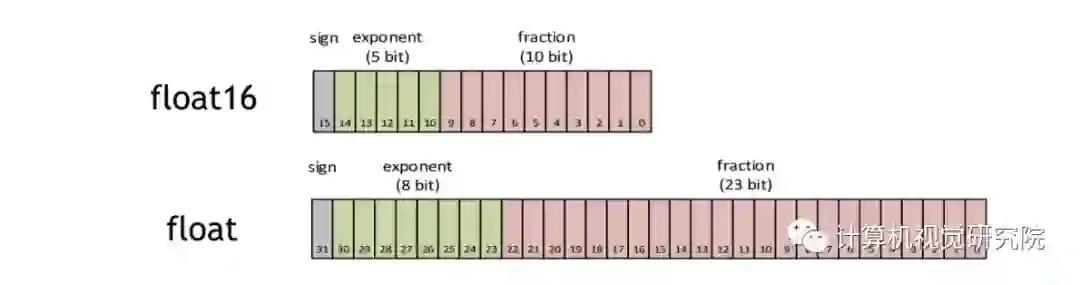
其中,sign位表示正负,exponent位表示指数(2^(n-15+1) (n=0)),fraction位表示的是分数(m/1024)。其中当指数为零的时候,下图加号左边为0,其他情况为1。

FP16的表示范例
为什么需要FP16?
在使用FP16之前,我想再赘述一下为什么我们使用FP16。
减少显存占用
加快训练和推断的计算
张量核心的普及
FP16带来的问题:量化误差
-
溢出错误(Grad Overflow / Underflow)
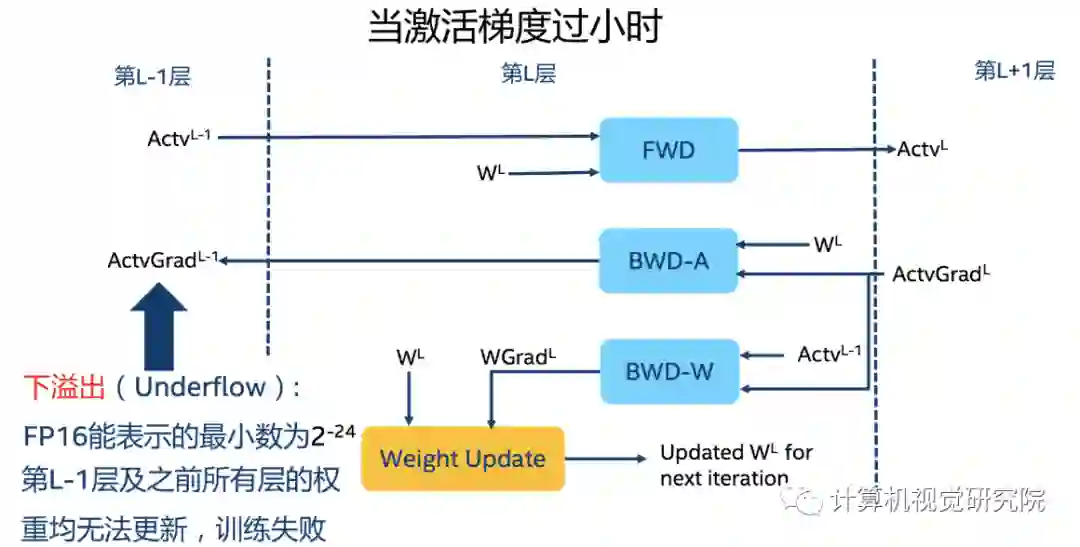
-
舍入误差(Rounding Error)

解决问题的办法:混合精度训练+动态损失放大
混合精度训练(Mixed Precision)
-
损失放大(Loss Scaling)
-
反向传播前,将损失变化(dLoss)手动增大2^k倍,因此反向传播时得到的中间变量(激活函数梯度)则不会溢出; -
反向传播后,将权重梯度缩2^k倍,恢复正常值。
Apex的新API:Automatic Mixed Precision (AMP)
1 |
from apex import amp |
-
opt_level 其中只有一个 opt_level需要用户自行配置: -
O0:纯FP32训练,可以作为accuracy的baseline; -
O1:混合精度训练(推荐使用),根据黑白名单自动决定使用FP16(GEMM, 卷积)还是FP32(Softmax)进行计算。 -
O2:“几乎FP16”混合精度训练,不存在黑白名单,除了Batch norm,几乎都是用FP16计算。 -
O3:纯FP16训练,很不稳定,但是可以作为speed的baseline; -
动态损失放大(Dynamic Loss Scaling) AMP默认使用动态损失放大,为了充分利用FP16的范围,缓解舍入误差,尽量使用最高的放大倍数(2^24),如果产生了上溢出(Overflow),则跳过参数更新,缩小放大倍数使其不溢出,在一定步数后(比如2000步)会再尝试使用大的scale来充分利用FP16的范围:

踩过的坑
这一部分是整篇最干货的部分,在最近在apex使用中的踩过的所有的坑,由于apex报错并不明显,常常debug得让人很沮丧,但只要注意到以下的点,95%的情况都可以畅通无阻了:
-
判断你的GPU是否支持FP16:构拥有Tensor Core的GPU(2080Ti、Titan、Tesla等),不支持的(Pascal系列)就不建议折腾了。 -
常数的范围:为了保证计算不溢出,首先要保证人为设定的常数(包括调用的源码中的)不溢出,如各种epsilon,INF等。 -
Dimension最好是8的倍数:Nvidia官方的文档的2.2条表示,维度都是8的倍数的时候,性能最好。 -
涉及到sum的操作要小心,很容易溢出,类似Softmax的操作建议用官方API,并定义成layer写在模型初始化里。 -
模型书写要规范:自定义的Layer写在模型初始化函数里,graph计算写在forward里。 -
某些不常用的函数,在使用前需要注册:amp.register_float_function(torch, 'sigmoid') -
某些函数(如einsum)暂不支持FP16加速,建议不要用的太heavy,xlnet的实现改FP16困扰了我很久。 -
需要操作模型参数的模块(类似EMA),要使用AMP封装后的model。 -
需要操作梯度的模块必须在optimizer的step里,不然AMP不能判断grad是否为Nan。
总结

扫码关注我们
公众号 : 计算机视觉战队

