Alink:基于Flink的机器学习平台


分享嘉宾:杨旭 阿里巴巴 资深算法专家
编辑整理:朱荣
本文主要介绍基于Flink平台的机器算法的功能、性能与使用实践,帮助大家快速上手Alink机器学习平台。其中重点介绍了python语言使用的PyAlink的方法和实例,同时对FM算法进行了详细的介绍,帮助大家更好上手Alink并在实际工作中得到广泛应用。
主要围绕下面俩点展开:
Alink基本介绍
ALink快速入门
首先跟大家介绍一下Alink的基本情况:
1. 什么是Alink?

Alink是由阿里计算平台事业部研发的基于Flink的机器学习算法平台,名称由Alibaba Algorithm AI Flink Blink 单词的公共部分组成。
Alink提供了丰富的算法库并天然可以支持批式和流式的处理,帮助数据分析和应用开发人员完成从数据处理、特征工程、模型训练、预测多节点端到端整体流程。
Alink提供Java API和Python API两种方式进行调用,Java API方便工程人员快速将Alink接入到现有系统中,Python API也叫PyAlink是方便提供机器学习同学完成快速的实验。
2. Alink功能介绍
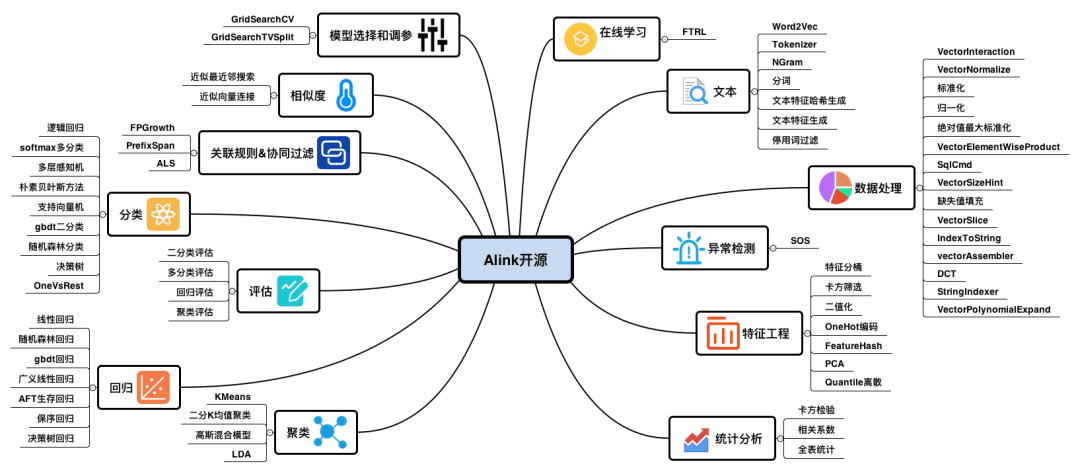
Alink作为一个重要的机器学习的平台,覆盖机器学习各阶段13大类的62项功能点,囊括了机器学习核心的分类算法、聚类算法、回归算法三类算法,并附带了4项模型评估的方法,同时还包括关联规则和协同过滤算法、相似度算法等数据挖掘方面算法。
在算法完成部分后,也提供了评估模型的评估方法,包括二分类评估、多分类评估、回归评估、聚类评估。
在算法应用之前Alink为使用者准备了数据预处理、异常检查、文本处理等辅助功能处理工具。
在在线学习方面Alink也准备了FTRL,可以在线状态中训练,在实时场景中提供模型实时更新机制,增强学习模型调整等时效性。
在机器学习中的模型选择与调试参数服务,为大家提供有效的参数调优。
3. Alink性能比对
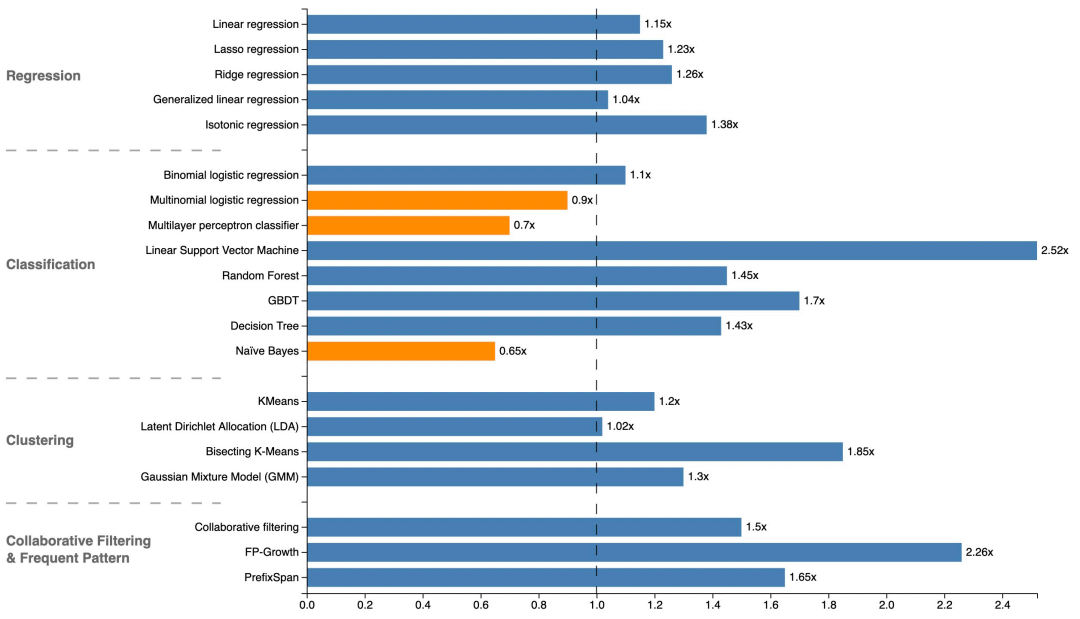
利用加速比对Alink与Sparkml进行性能评测。具体的测试方法是使用相同的测试数据,相同的参数,用Sparkml的计算时间除以Alink的计算时间。从下图实际测试对比数据可知,Alink在大部分算法性能优于Spark,个别算法性能比Spark弱,整体是一个相当的水平。
4. Alink建设进展
2019年7月发布Alink version 1.2.0:
支持Flink多版本 1.11、1.10、1.09;
支持多忘记系统:本地文件系统,Hadoop文件系统,阿里云oss文件系统;
CSV格式读取、导出组件支持各文件系统;
推出AK格式读取、导出组件,简化文件数据操作;
支持模型信息摘要、输出;
FM分类、回归算法;
2019年6月发布Alink version 1.1.2:
新增30个数据格式转化组件;
支持多版本Hive数据源;
在Pipline和LocalPredictor中指出SQL Select操作;
2019年4月发布Alink version 1.1.1:
提升使用体验,参数检查方面更加智能;
2019年2月发布Alink version 1.1.0:
支持Flink1.1.0和Flink1.9的平台部署问题,PyAlink增加兼容PyFlink的功能;
改进UDF/UDTF功能;
支持JAVA Maven安装和 Python PyPl安装;
支持多版本的Kafka数据源;
2018年12月发布Alink version 1.0.1:
重点解决windows系统上的安装问题。
2018年11月首次发布Alink version 1.0,在Flink Forword Aisa大会上开源。
接下来为大家详细的介绍Alink的使用方式:
1. 使用Maven构建Alink项目简介

Java使用者借助Maven中央仓库,大家只需要4步就可以很容易的构建出Alink项目。第一步:创建项目;第二步:修改pom文件,导入Alink项目jar包;第三步:拷贝修改Alink Java Demo Code;第四步:构建运行;
详细过程可以参考:
http://zhuanlan.zhilu.com/p/110059114
2. PyAlink安装实践

Python使用者借助PyPl,也可以两部构建Alink的使用环境。第一步,针对不同操作系统调整部署环境,包括MacOS、Windows、阿里云服务器。第二步,从PyPl选择最新版本的PyAlink安装,如果之前有PyAlink需要先卸载旧版本,再通过PyPl进行安装。
① PyAlink任务在notebook上运行

PyAlink的运行方式分为两种,一种是本地运行,一种是集群运行;在Alink1.1.1以后优化了运行集群运行地址指定的方式,用户可以更简洁的运行PyAlink的任务。
② 基于PyFlink的Alink

Alink Operator与PyFlink Table可以相互转化,方便串联Flink和Alink的工作流。在1.1.1新版本中还提供了getMLEnv接口,能直接使用flink的提交运行方式直接进行提交 run -py *.py 往集群提交作业。例如:直接使用 python keans.py 。
③ PyAlink使用体验的改进

为方便的使用PyAlink,最新版本也对于两个方面进行了优化。一个是Python UDF运行中将自动检测python3命令,确定运行版本。另一个优化是对DataFrame和BatchOperator互转性能做了提升,优化后性能提升了80%左右;对collectToDataFrame进行了同样的优化。
3. Alink支持的数据源
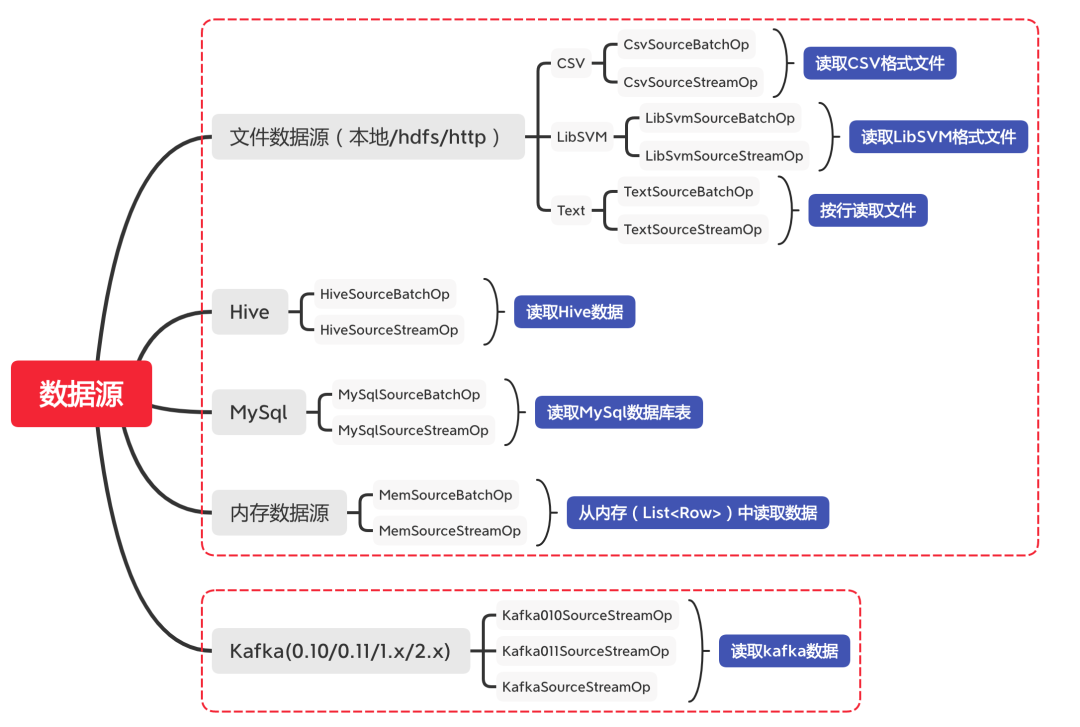
Alink支持批式和流式5种类型的数据源,其中批式数据源包括文件数据源、Hive、Mysql、内存数据;流式数据源主要是针对Kafka。
① 读写Kafka示例

以逻辑回归模型为例使用Kafka分为四步:第一步定义Kafka数据源;第二步使用json提取组件解析Kafka中的数据,完成数据类型转换;第三步加载逻辑回归模型,对流数据进行预测;第四步将预测结果再次写出到Kafka。
② 将JSON格式的字符串解析为多列
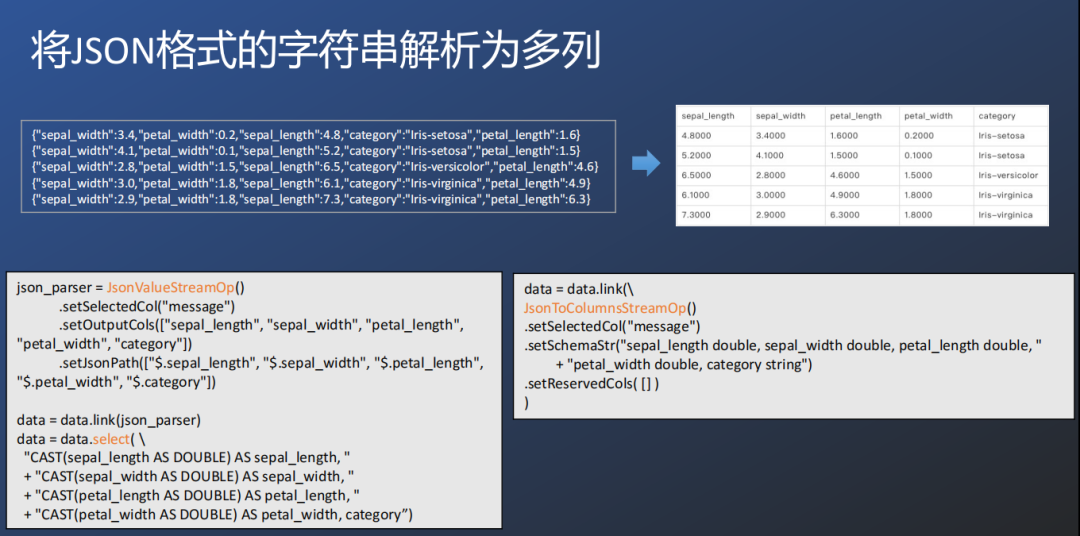
Alink也针对json格式的数据进行解析组件JsonToColumnsStreamOp,比json_parser更方便的处理json格式到表格字段列格式的数据转化。
③ 日志的字符串解析为多列
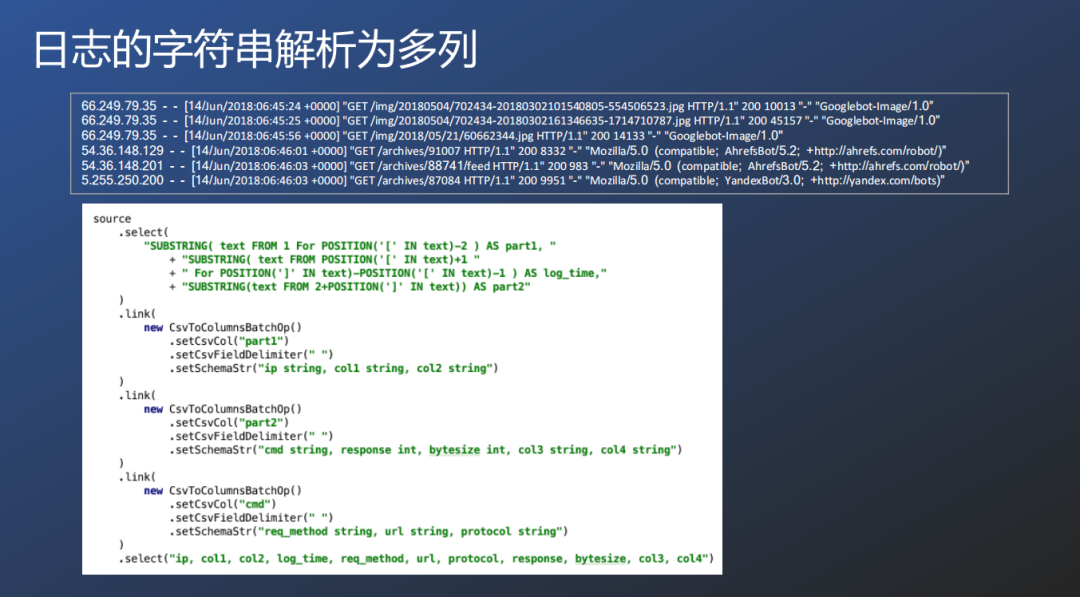
在PyPlink中可以通过分布方式进行处理,先处理【】括号内的数据,再处理CSV格式的数据,PyPlink提供了select选择组件和link管道组件。
④ Alink类型转换组件
Alink框架中常用Columns、Vector、Triple等类型的数据作为算法的输入输出,但用户可能会有多种输入输出数据类型的需求。因此Alink提供了全面的类型转换组件,作为衔接使用户数据与Alink算法数据的桥梁。
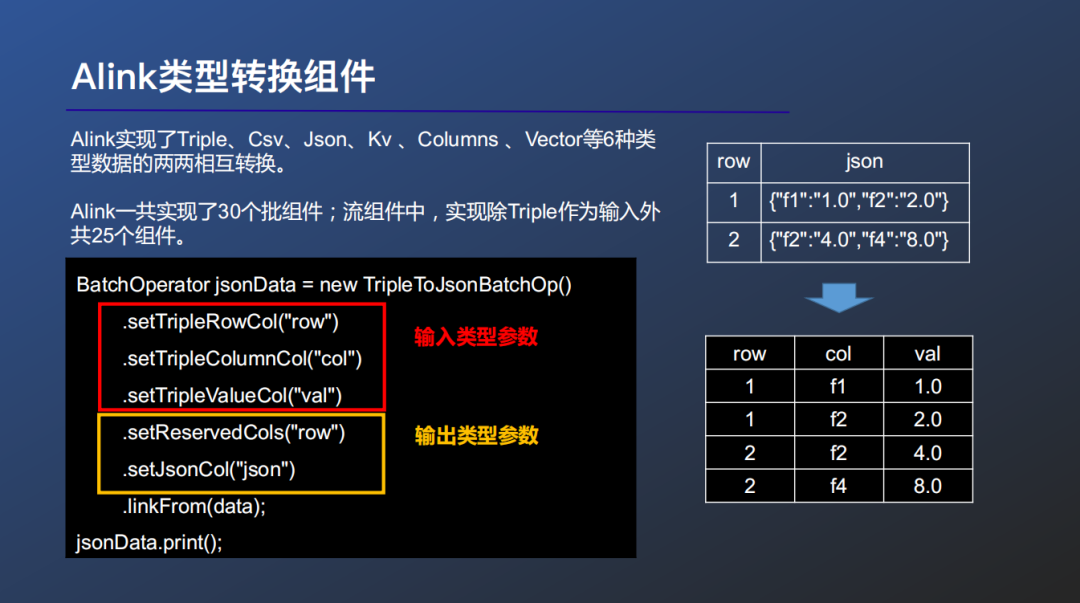
Alink共支持Tripile、CSV、JSON、KV、Columns、Vector等6种类型的数据两两相互转换。
批组件中,Alink实现了6种类型的数据两两相互转换的全部30个组件;流组件中,实现了除Triple作为输入外的共25个组件。
Alink对于众多的组件使用有一些组件命名规律,组件命名格式参考:原始格式A To 目标格式【流式|批式】Op(),例如:TripleToJsonBatchOp()可以通过批式处理将Trip类型的数据转化为Json格式的数据。
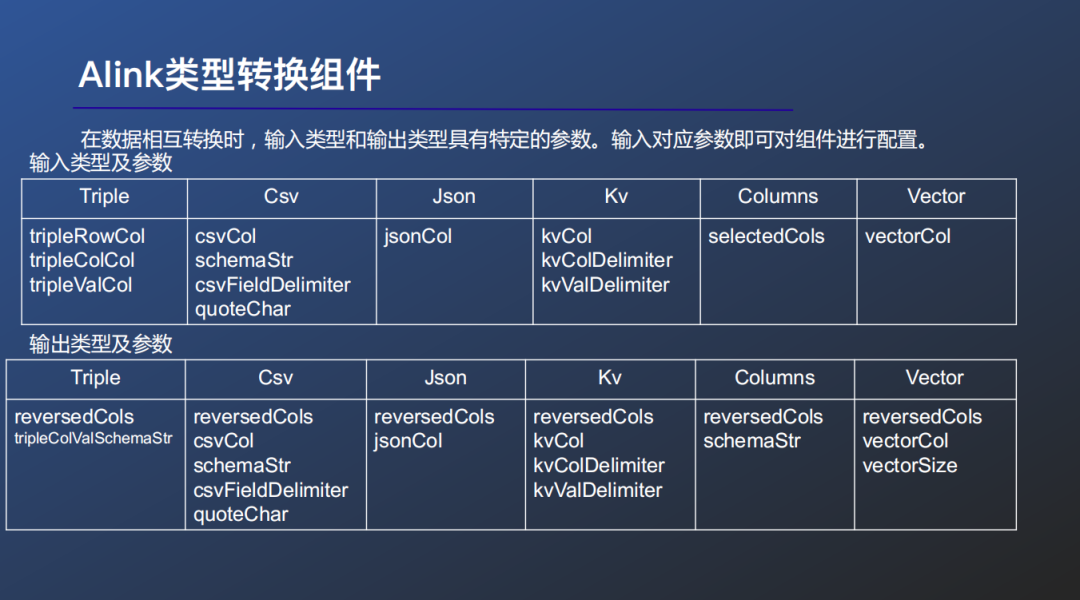
在数据相互转化时,输入类型和输出类型具有特定的参数。输入对应参数即可对组件进行配置。大家可以看到这样的转化规律性是非常强的,使得大家对于格式转化的工作变的更加轻松。
⑤ 优化枚举类型参数
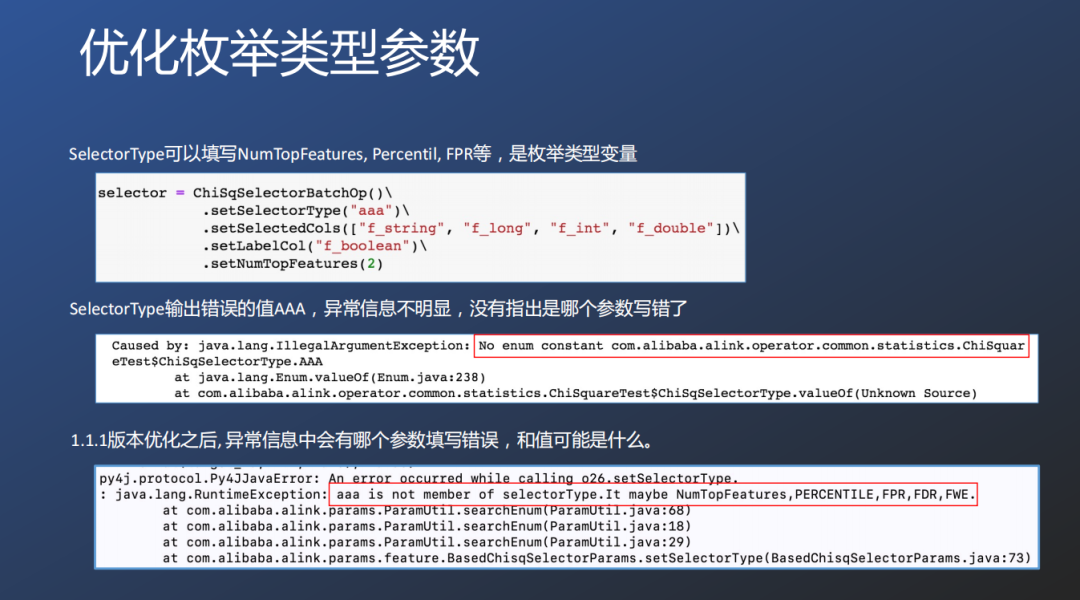
在实际开发过中,Alink结合Java开发IDE编辑器的自动提示功能,为选择器提供了参数联想选择的提示功能。
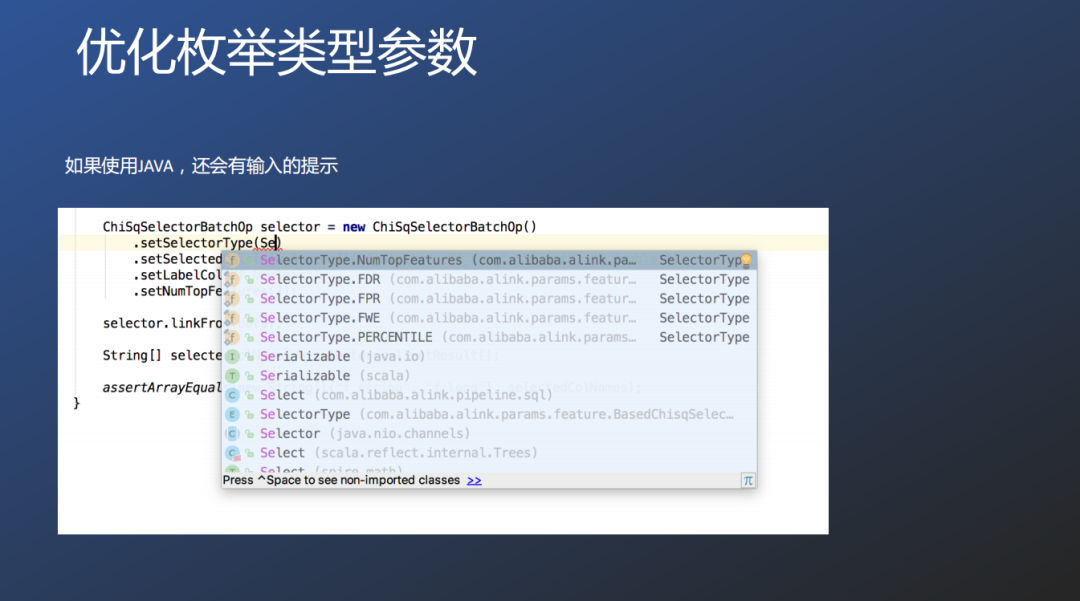
方便开发者对于模型参数的调整,避免参数过多,反复查手册的情况。
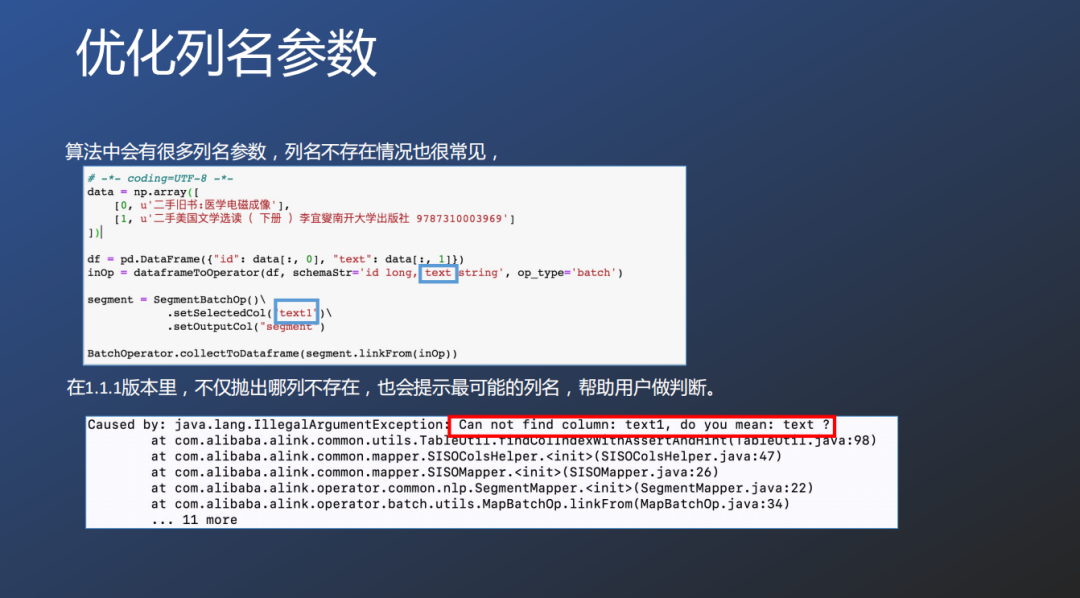
对于数量列名称的优化,也有针对原始数据的优化,针对错位列名也提供错误提示功能。
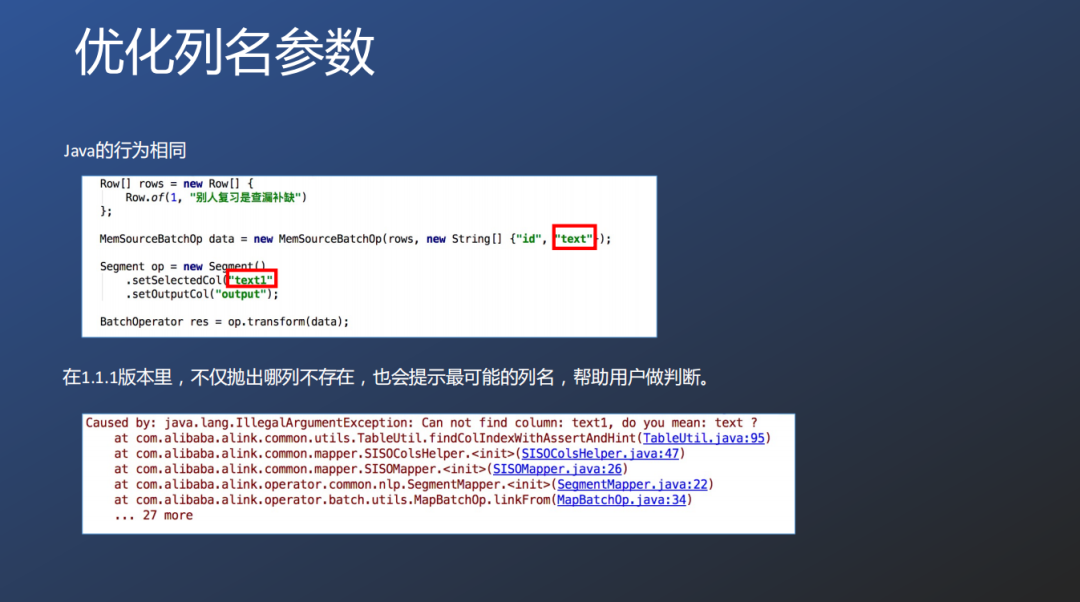
对于开发的开发速度和开发质量的帮助。
4. 统一的文件系统操作介绍
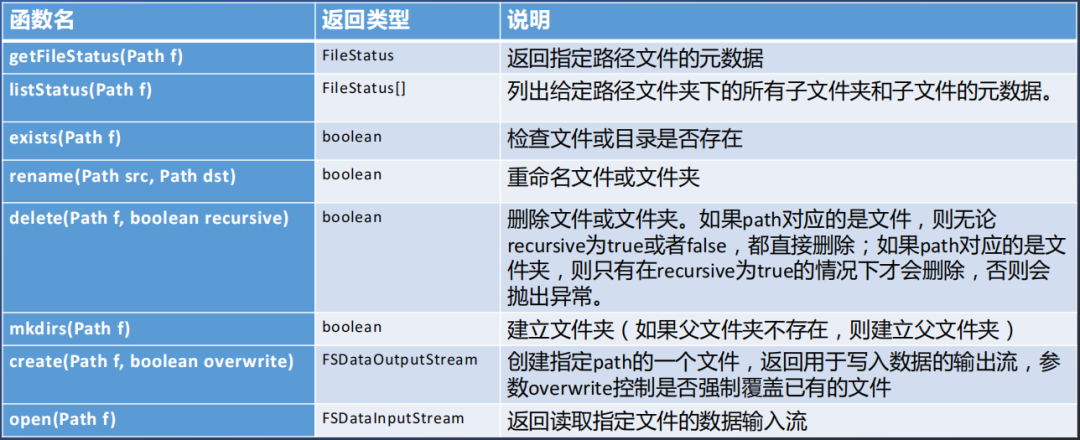
Alink提供了统一的文件系统操作接口,为开发者屏蔽掉对接各类文件系统的繁琐差异。无论是本地文件系统、hadoop、云存储的oss相同功能都可以使用相同名称的接口获得相同的调用意图和返回结果。
在确定文件的位置后,获取到文件的输入流输出流,提供文件拷贝、保存、读取功能的完备性。
在针对不同环境的文件系统构造实例是需要进行特定配置后,就可以利用统一的文件操作,使用标准化接口完成。
5. 数据文件
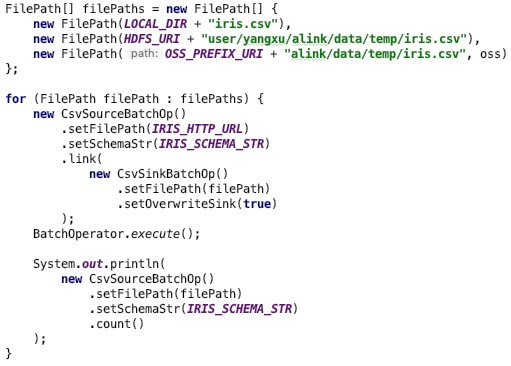
了解统一文件对象创建和操作接口后,我们看一下一个实际CSV文件的操作转化实例。构建一个基于httpl网址数据文件,针对实际的处理过程是创建文件操作实例,使用数据格式转化组件CSVSrouceBatchOp完成数据schema的构建,完成批次文件的处理操作执行。输出执行后的文件内容并通过内容计数来验证文件在转化过程中内容。
统一文件系统代带来的好处,通过一样的代码完成各环境中的数据处理逻辑。
6. FM算法

Alink在处理大规模稀疏数据场景,提供具有线性计算复杂度的FM算法。针对线性模型的特点,最大的特征是每个函数有一个特征,并且这个特征跟整体函数关系有一个权重。为解决线性模型的表达力,也可以组织一个二阶多项模型来增强线性模型对于复杂度的描述能力。
在二阶模型中参数更丰富,效果更好的代价是权重矩阵wij将是一个1/2 N方的计算复杂度,当特征增加时,维度也将随之增大,造成实际计算中计算力的不足。
因子分解机将是一个较好的折中,在分解机中,每个特征对应着一个向量,向量的权重就是两个向量的内积。一个向量取几十维或者上百维,一般就是取一百维,权重系数就是100xn,计算更可控。模型所带来的计算量就可以带来更好的计算效果和更合理的计算代价。
附录,Alink开源地址:
https://github.com/alibaba/Alink
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~

杨旭,阿里花名"品数",阿里巴巴资深算法专家,阿里云机器学习平台 PAI 中基础机器学习算法的负责人。2004 年获南开大学数学博士学位;随后在南开大学信息学院从事博士后研究工作;2006 年加入微软亚洲研究院,进行符号计算、大规模矩阵计算及机器学习算法研究;2010 年加入阿里巴巴,从事大数据相关的统计和机器学习算法研发,2017 年带领团队研发基于Flink的流批一体的机器学习平台 Alink,现已开源。出版《重构大数据统计》,《机器学习在线:解析阿里云机器学习平台》等著作。
文章推荐:
社群推荐:

关于我们:
DataFunTalk 专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请近600位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章300+,百万+阅读,8万+精准粉丝。

🧐分享、点赞、在看,给个3连击呗!👇