机器学习平台痛点与模型提升方法:基于Spark的机器学习平台在点融网风控应用介绍
编者按:大数据和机器学习是近年来快速增长的热门领域,各个领域的数据量和数据规模都以惊人的速度增长。本文是近期举行的架构实践日点融网刘利就“机器学习平台在点融网业务的应用介绍”这一话题的精彩分享。
作者简介:
刘利,点融网 Data Scientist Team 负责人,从事互联网数据分析和数据挖掘近十年。现任点融网 Data Scientist Team 负责人。曾负责携程网信息安全部数据团队。长期专注于互联网风控领域,尤其是电商行业和 Fin Tech 行业反欺诈分析建模和消费者信用评级。一直致力于用大数据的技术手段解决互联网行业中的信息安全和风险管理中的难题。

分享模块
点融机器学习平台
风控业务案例分析
如何提升模型性能
本次演讲主要分三大块,第一块是我们在点融做的一个机器学习平台或者说框架,第二块是在我们在做风控业务的一些案例分析,第三块是在建模时的一些经验分享。
点融机器学习平台
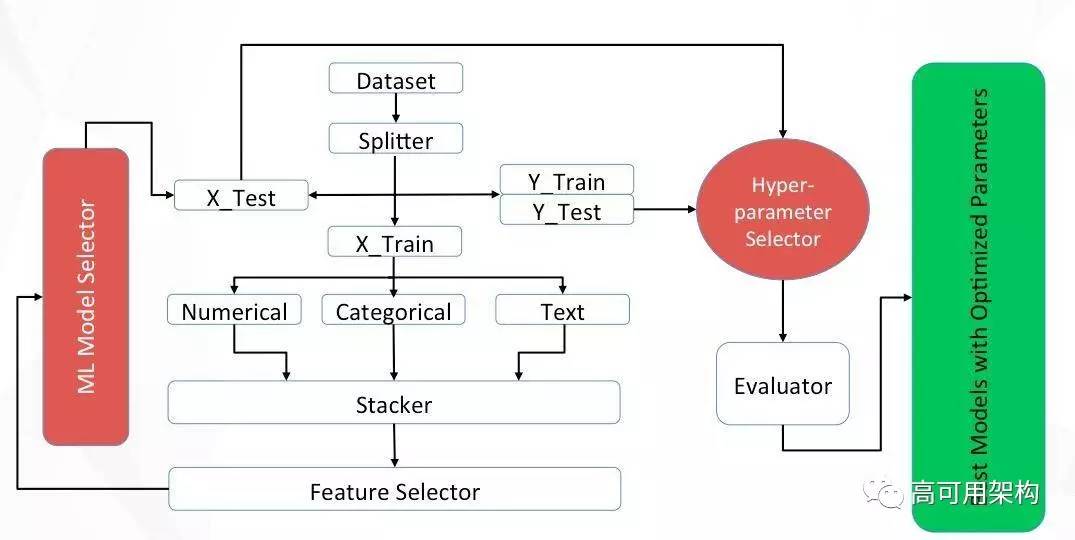
机器学习的一般流程是,我们先有一个数据集,拿到这个数据集之后会作一个拆分,拆成一个 (X train, Y train)、(X test, Y test)。然后会根据训练集的特征作一个预处理。处理过程可能会包括比如缺失值的处理、相关性分析、分布情况的考察等。接下来是对这些特征作重要性和区分度的分析,看到底哪些特征是最关键而且对目标变量最有区分效果。再之后会做 Model Selector,去尝试用一些算法,看看哪些算法能达到我们期望的效果。
我们知道每一个算法都有外在输入的参数,这些参数跟它本身的算法的设计有关,可以根据我们积累的经验调优参数,尝试到底哪种组合能达到最好的效果,通过对 Hyper-parameter 做调优的选择后,终于得到了你想要的 Best Model。机器学习大致的流程就是这样。
二、已有的解决方案
收费
数据安全
数据可视化
分布式
模型结果部署
第一个是收费的问题。收费可能是按照 license 收费,也可能是按它的配套方案收费,比如它是部署到云端的,或者是在公司本身做本地化的部署,但这些收费一般来说都不便宜。
第二个是数据安全的问题。如果是云端的部署,也就是说意味着需要你把数据上传到云端。云端对很多互联网公司,尤其是非常看重数据安全和质量的互联网公司是非常不情愿的事情。这意味着数据要上传出去,即使经过了层层加密,也依然不能彻底解决数据安全的问题。
第三个是数据可视化的问题。很多开源的机器学习的工具在数据可视化这块没有提供足够强大的功能。你可能借助其他开源的可视化工具自己去操作,但这意味着你需要在不同的工具之间来回切换。还有一些工具本身并不支持分布式,只能在单机上跑。很大程度上取决于你的服务器内存的大小能够 handle 多大的数据集。
最后是模型部署。经历完一个繁琐的流程之后,终于得到了我们想要的模型。不过怎么把它部署到生产线上,很多工具在设计上并没有很好的考虑这个场景。
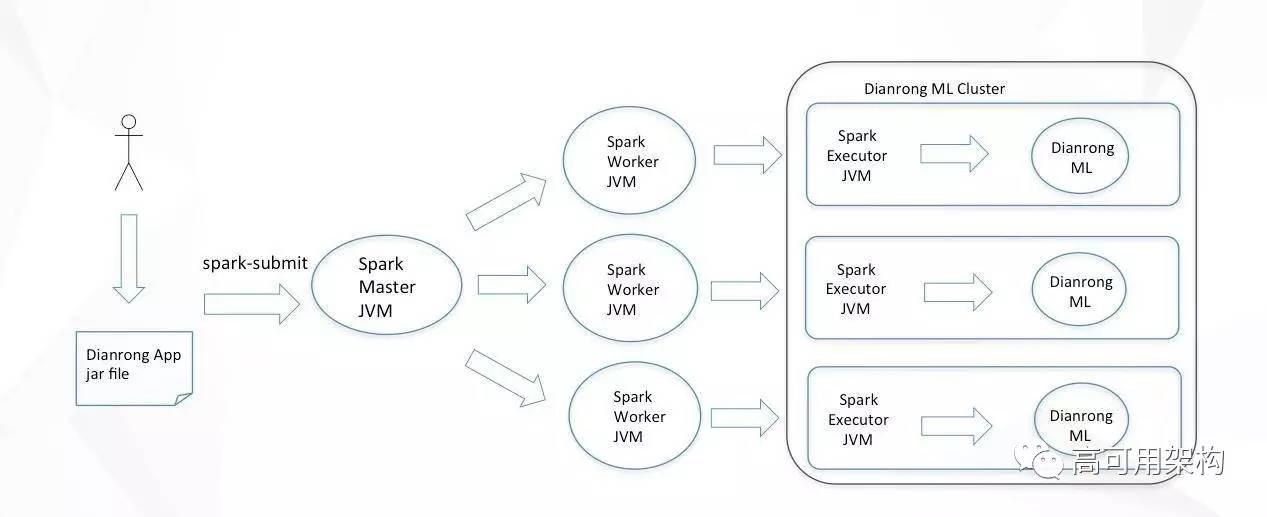
基于这样的原因,我们觉得在点融需要有自己的一套机器学习方案。这样才能解决刚才说到的这些痛点。点融的机器学习平台是基于 Spark 集群及开源方案上,做了二次开发,把一些我们觉得重要的特性加进来。
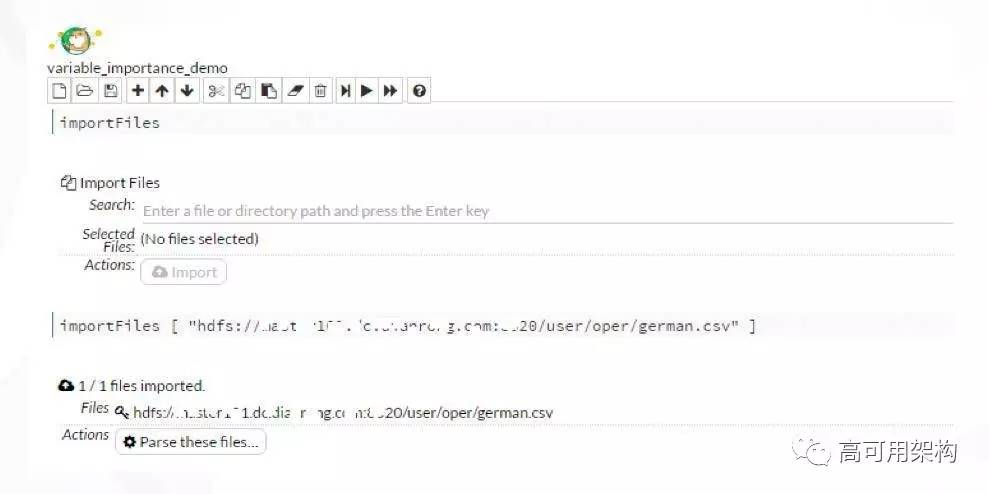
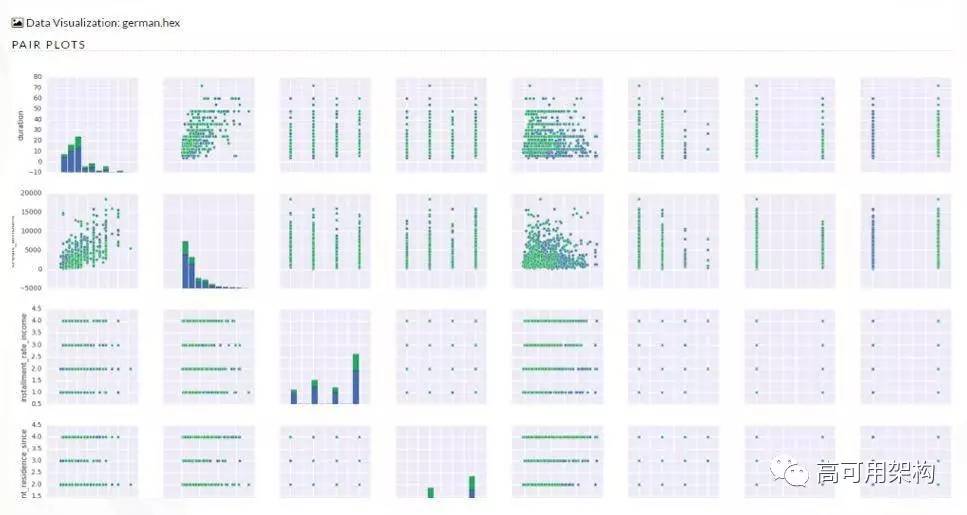
具体来看一下做的一些事情:
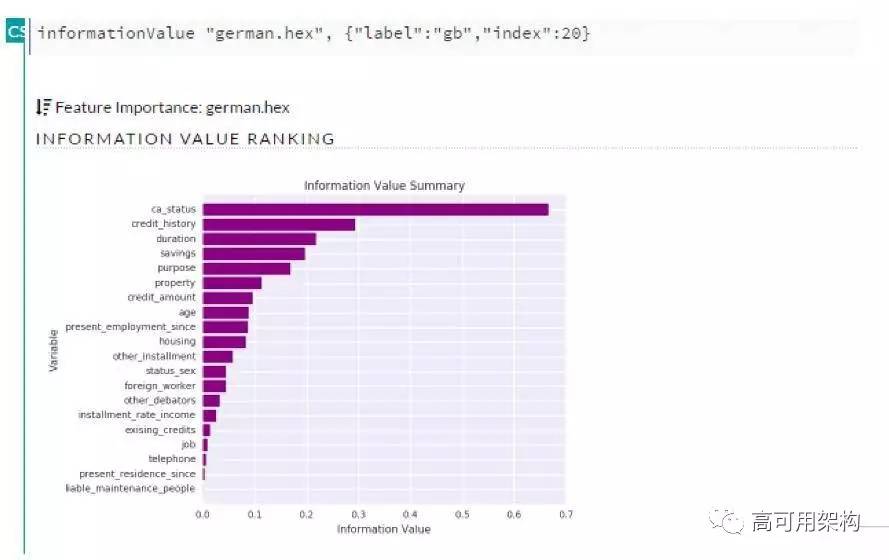
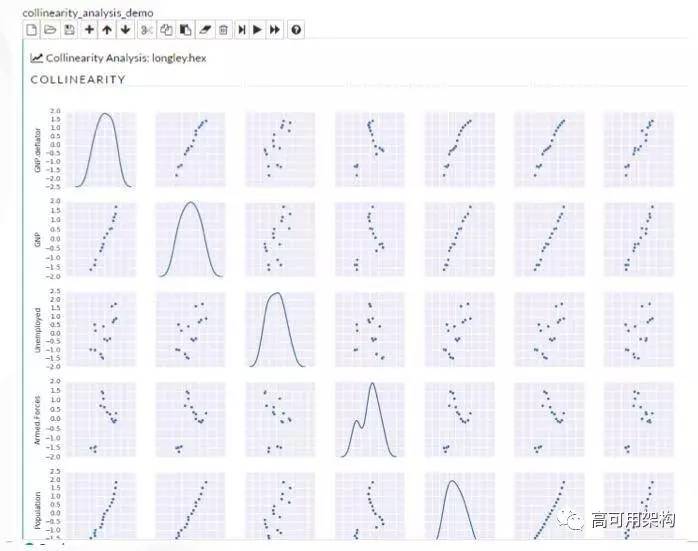
因为我们是基于 Spark 做的机器学习平台,所以首先必然要求可以读取 HDFS 数据(图 3)。然后可以做到数据可视化(图 4),数据读进来后,通过一个可视化的按纽,可以把整个数据集特征分布展现出来。能够通过图形化的方法展现特征的重要性排序(图 5)和共线性分析(图 6)。在很多算法中,如果在用到的变量之间中出现强相关性,这样算法的效果要大打折扣的。我们增加了一个可视化效果,可以看变量之间的相关性。
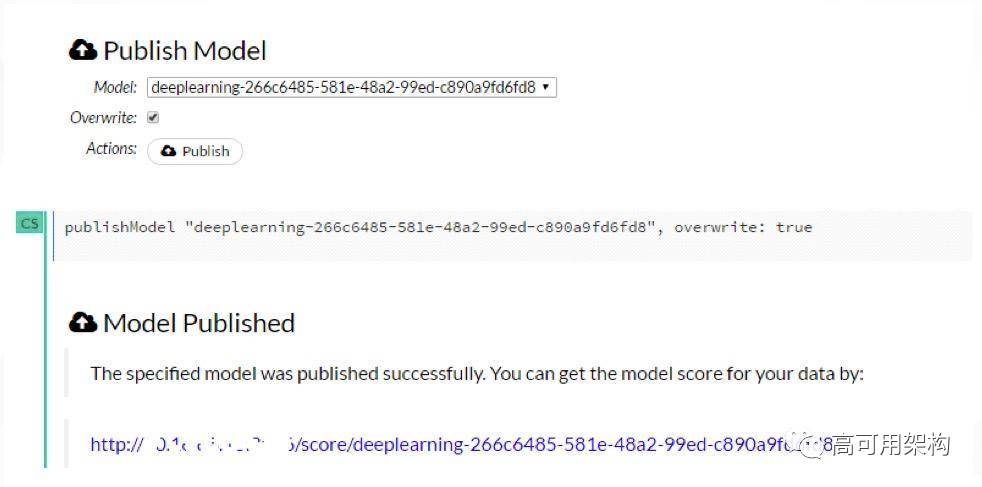
最后是怎么去发布我们得到的 Model(图 8),这边有一个一键发布的按纽,当你生成好 Model 之后可以点 Publish 直接生成一个 Restful 接口。这个接口可以对外部系统提供 Model 的预测服务。
我们希望通过点融机器学习平台,使得我们平台的使用者能够很傻瓜地执行机器学习的一般流程。只要有相关机器学习经验的同事,就可以很快上手,让使用方可以节省下敲代码的时间,基本做到只要用鼠标点点,就可以看到算法效果是什么情况。
风控业务案例分析
点融的主营业务是借贷和理财。跟钱打交道的业务必须要有强大的风控才能持久。大家可以回想一下当你去向银行申请住房贷款或者信用卡的时候,银行的工作人员在审核你的身份证和工资流水的认真程度就知道他们对你的资产和信用信息是多么地关注,因为他们希望能够把客户的违约风险降低到最小。
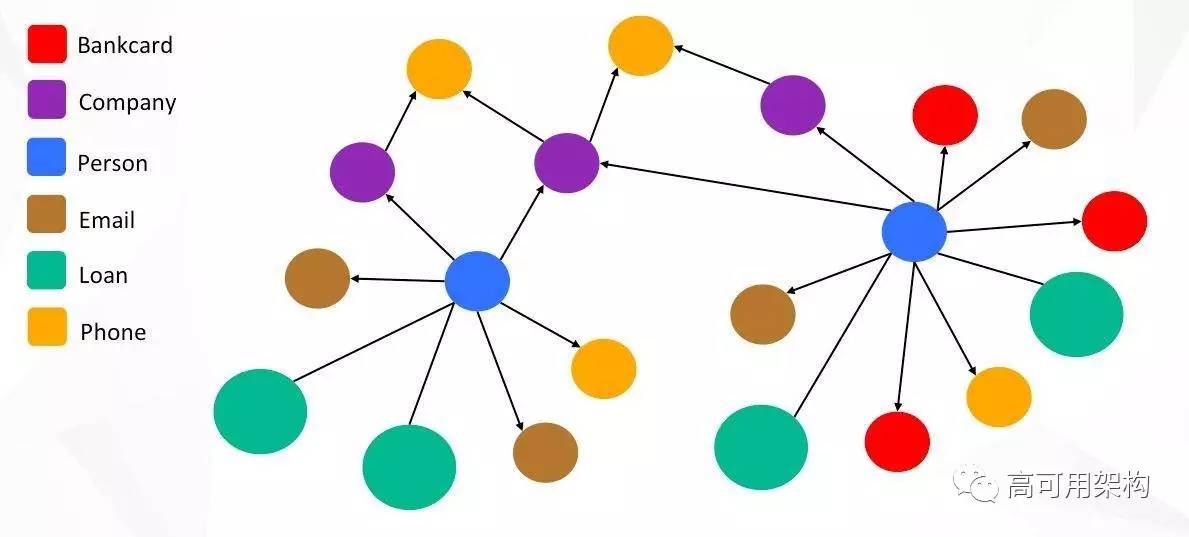
图 9 是有一些常用的个人信息(图 9),比如这个人的 Bankcard,他所工作过的公司,email, 申请的 loan 等。我们可以在图数据库里面把这些实体关联起来。大家如果有做过数据挖掘或机器学习的都知道,我们最常处理的数据格式是二维表。如果你在处理图片类数据,我们会把图片类数据通过 rgb 三个颜色通道扩展到更高维的表,但是它本质上还是一个表。但是图的关系和我们常用的二维表的数据格式其实不太一样,它会更复杂。我们也不大可能用一个二维表去完整地把这个图的信息表达完整。风控的数据分析和建模是需要我们基于图的数据做分类和预测相关的工作。
Graph Mining 在风控领域的应用
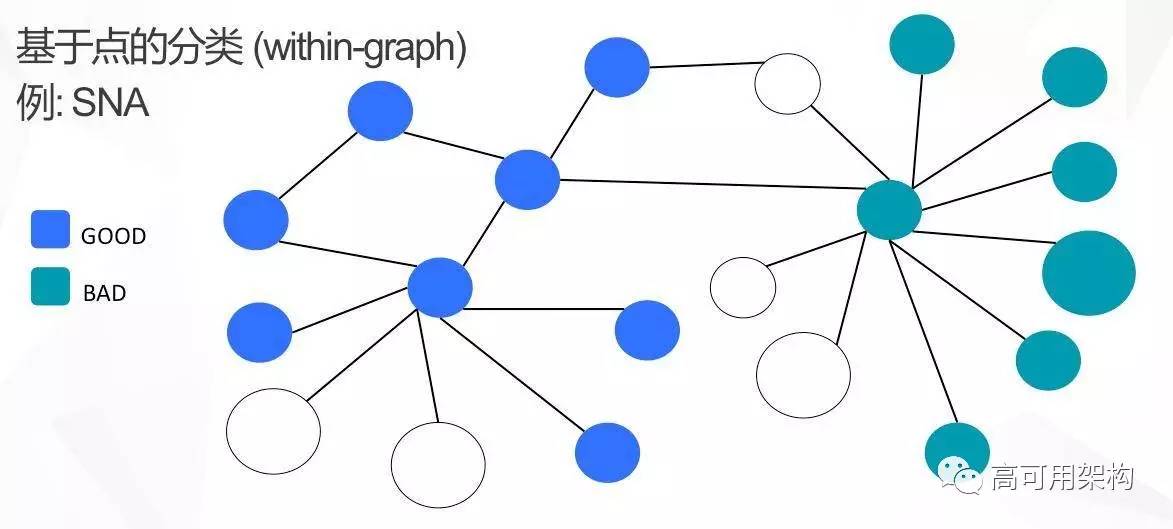
基于图的数据怎么样去做机器学习相关的算法?大致的思路大概是这么几条。
比如基于点的分类。你所关心的数据已经通过你定义好的实体整合延伸到一个很大的图。对其中的一些节点,通过对历史数据的反馈,我们是可以知道哪些节点对应的申请人是坏的,哪些节点对应的申请人是好的。这样我们可以给这些节点做标注。比如在上图中,用浅蓝颜色标注的是好,深蓝颜色标注的是坏。在图的这个结构上可以用图的分类算法去做训练,得到一个针对节点的分类模型。对于新的节点,比如图中的空白颜色的节点,我们可以通过这个图的模型预测是好或坏的概率。
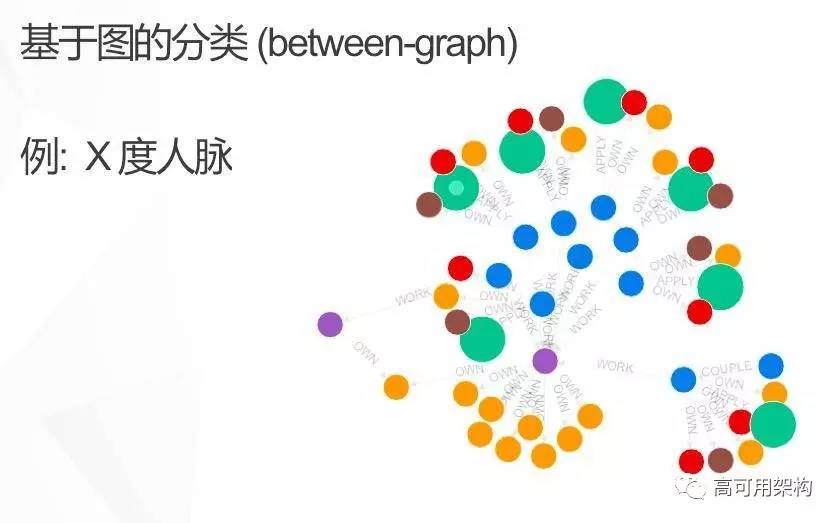
图 11 是基于图的分类。比如说我们对每一个申请人,把其给定 X 度人脉所关联到的点全部抠出来。这样每一个人的给定 X 度人脉都是一个完整的子图。我们根据之前的历史数据标注出来哪些子图是属于好的,哪些子图属于坏的。我们可以基于子图的结构去实施机器学习的算法,得到对给定 X 度人脉的子图的分类模型。

基于非监督的学习,有三个假设。
第一个是平滑性假设,意思是如果两个样本点的坐标是很近的,那这两个样本点属于同一类别可能性是很大的。这个假设是所有回归模型的前提。如果实际的数据集不满足这个假设,我们是不能应用线性回归和逻辑回归在其上的。
第二个是聚类假设,如果通过某一种聚类学习得到不同的子簇,那么同一个子簇里的样本点有很大概率属于同一个类别。举一个例子,我们看到上图中这个数据集是有清晰的底层结构的。我们能通过某一种聚类算法得到两个子簇。比如看图中的这两个点,我们去估计这两个点的距离,会发现它们是很近的。如果你单用平滑假设,就会觉得这两个点应该有较大的概率属于同一个类。但是你考虑到本身数据的结构,再加上聚类算法的结果,你会发现因为这两个点属于两个不同的子簇,所以它们应该会有较大的概率属于不同类别。
第三个流形假设。简单的说,流形假设或者流形学习是在做降维的事情。我们的球面可以看作是一个在三维空间的二维流形。这样南极北极的距离就不是地球这个球体的直径长度,而是半弧的长度。这个概念在流形里面叫测地线。机器学习中分类问题的本质,可以说是通过生成的特征空间,是把所有的样本点映射到这个特征空间里,然后在这个特征空间里能够找到一个超平面把好的和坏的样本点完全分离。流形学习是说如果在这个高维空间里我们发现样本点可以用一些低维的特征组合得到,那我们就得到了它的流形结构。如果属于同一种的流形结构的样本点,应该有很大的概率属于同一个类别。
基于图结构的非监督学习基本上也是按照这种思路去做的。
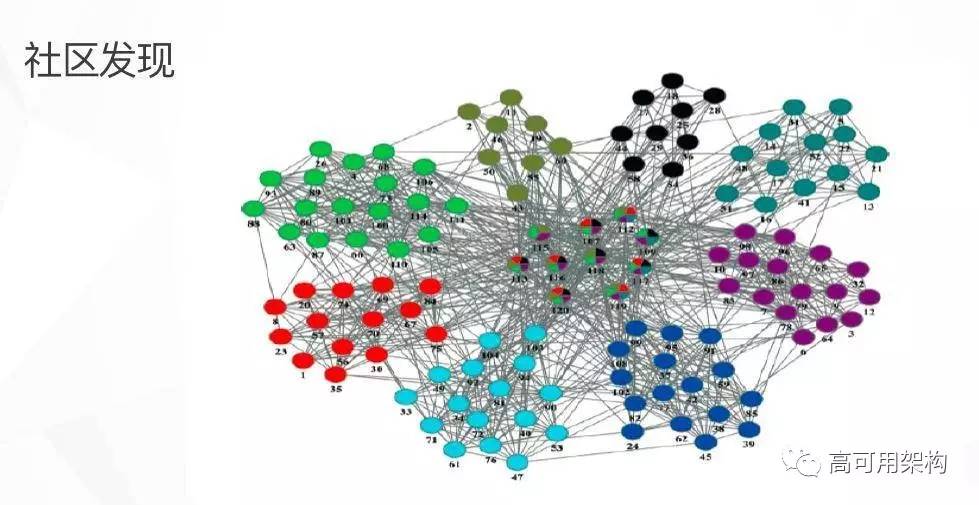
社区发现是在说我们从图的关系结构里,借助社区发现相关的算法,得出图里某些样本点之间的关系是比它们和周围其他点的关系要密切得多的。这样这些点就构成了一个社区。如果我们用到风控领域的话,是说如果在这个社区里出现了较多坏样本,那说明这个社区已经被“污染”了,那属于这个社区的点应该有很大概率是属于坏的。
如何提升模型性能
基于数据
借助算法
用算法调参
借助模型融合
最后讲一讲在建模过程中一些调优的经验。如果发现 Model 的效果不是很满意,应该采用怎样的方法提升。可以尝试这四个方面。
第一个是基于数据的方法。如果这个模型效果不太好,我们首先要思考的是特征是否还不够好或者还不够多。我们能否想方法找出更多的特征来。同时也要考虑到我们对数据的分析是不是到位,是不是对数据的处理上还不够细致,是否在数据的整理上犯了一些低级错误,而导致模型效果不太好。
第二个可以借助算法的方法。如果你用到的算法是线性的,它的效果可以作为你的一个 benchmark。你可以尝试使用复杂一点的算法去拟合你的数据集,比如用非线性的,boosting 的一些算法。用复杂的算法一般会比一些线性的算法得到更好的效果,但也同时意味着你要花更多时间调优模型的参数。
第三个用算法调参的方法。一般说来,非线性算法是有一些超参数的。越复杂的算法超参数越多。比如像深度学习的超参数就非常多。你要通过一个复杂的算法得到一个很好的模型,是需要花很多时间去调参的,而且在调参过程中意味着你需要对算法本身有一定了解,而且了解的越深入对调参过程越有把握。
最后通过融合(ensemble)我们的模型。我们使用 random forest 或者 GBDT 的算法,本身就是一种融合的方式。我们在用好几种算法得到不同 Model 后,可以把这些 Model 再次融合起来。最直接的方法是把不同 Model 的结果当成新的 Model 的 input 重新去训练。在你遇到 Model 效果不太好的时候,可以尝试使用模型融合。
今天的分享就到这里,希望我们的经验能够帮助到你们。
Q&A
提问:刚才您说把数据变成一个图而不是二维表,这样怎么把图数据输入到机器学习算法内的?因为机器学习算法都是二维表形式的?
刘利:我刚才说的基于图结构的机器学习算法不是我们常用的那些机器学习算法。这是基于图的结构本身设计出来的新算法,都有 Demo Coding。如果你想尝试用机器学习里常用的分类算法,你可以把图的结构变成二维表,但是你会丢掉一些信息。比如你统计这个样本点的多少度人脉的统计量,把这些信息放到二维表里。
提问:还有您刚才说的聚类,咱们用的是欧式距离还是其他什么距离?
刘利:很大程度上需要根据你实际的数据集的情况设计你的聚类算法。
提问:您刚才说咱们做社区发现,背后的算法是聚类还是其他的?
刘利:社区发现本质上是一个聚类算法。对社区的定义其实不是严格的,这个概念是说某些样本点之间的联系要比它们跟周围其他的一些点的联系要多。但是这联系多少算多不是严格的,是根据你自己对业务的理解定义出来的。
提问:我不是做机器学习的,但是我想问一下机器学习对中小企业有什么实践意义?我们目前是做物流相关的行业,数据量暂时还不是很大。
刘利:也许你可以借鉴机器学习的思路和方法。我觉得不管是大企业还是小企业包括你个人,每天都面临做新的决策。做决策有很多方法。也许是凭借你个人的直觉、积累的经验和知识等,当然也可以是数据的方法。如果你能尝试用数据的方式表达你所依据的经验和知识,你就能借鉴机器学习的方法,得到你所关心的问题的结论。所用到的数据也并不一定要非常大,也可以是小的数据,比如用 Excel 能处理的也可以。也许你会看到机器学习给你的结果能带来一些新的提示或者帮助。也有可能机器学习在某种程度上是在表达你的经验。也许你会觉得这个机器学习的思路并不是一件坏事,它会让你看到一些新的结果或者产生一些新的想法。
关于架构师实践日
七牛云竭力在全国范围,为所有追求卓越的程序员和架构师,打造一片分享与交流的纯净空间。这里有大牛、有干货、有方法、有实践,亦有怀揣着技术梦想的同道中人。无论你想学习知识、激发灵感、探讨决策,或是扩大视野、结识伙伴、分享心得。架构师实践日都会令你不虚此行。
点击阅读原文,获取更多架构师实践日精彩分享视频和 PPT
推荐阅读
本文作者刘利,转载请注明出处,技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。
高可用架构
改变互联网的构建方式
长按二维码 关注「高可用架构」公众号