主动学习减少对标注数据的依赖,却造成标注冗余?NeurIPS 2019 论文解决了这个问题!

实现代码 GitHub 地址: https://github.com/BlackHC/BatchBALD
一、什么是主动学习?
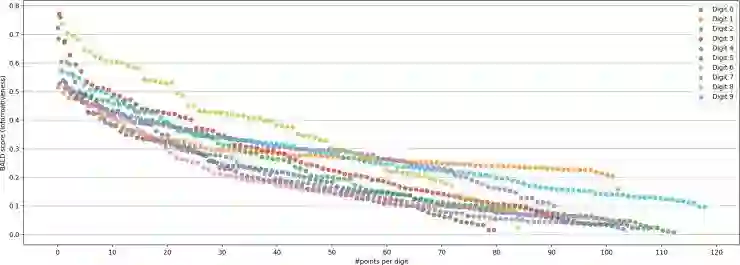
二、存在什么问题?
三、我们的研究成果
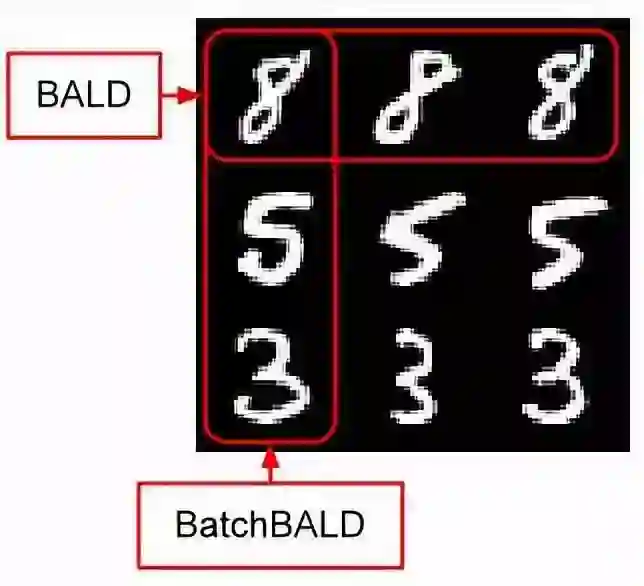 图3:
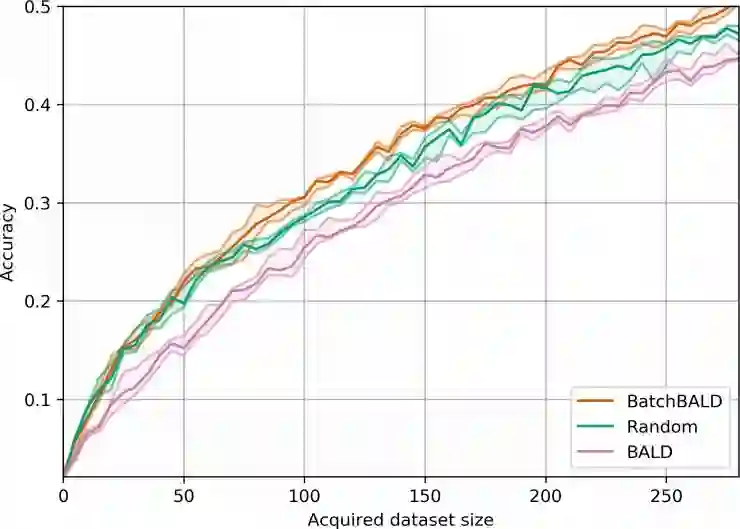
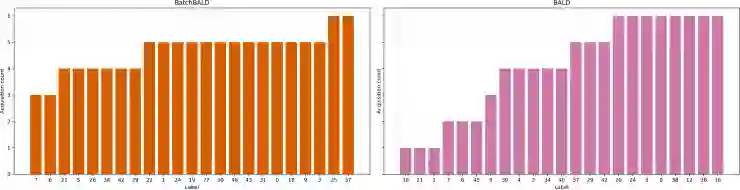
BALD采集函数 和 BatchBALD采集函数 的理想获取。
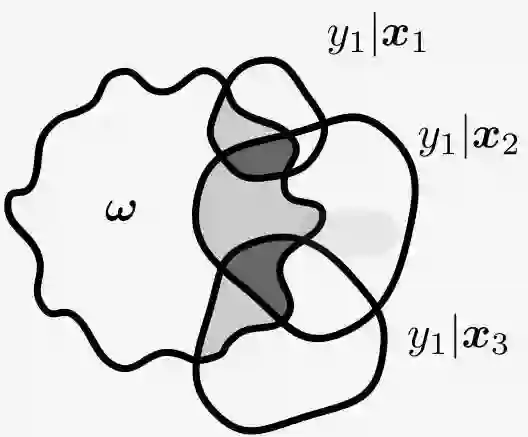
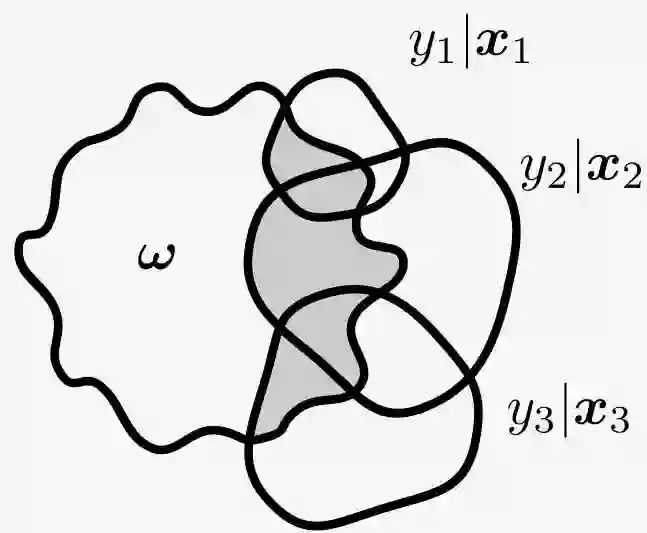
如果数据集的每个数据点包含多个相似点,则 BALD 采集函数将以牺牲其他信息数据点为代价选择单个信息数据点的所有副本,从而浪费了数据效率。
图3:
BALD采集函数 和 BatchBALD采集函数 的理想获取。
如果数据集的每个数据点包含多个相似点,则 BALD 采集函数将以牺牲其他信息数据点为代价选择单个信息数据点的所有副本,从而浪费了数据效率。
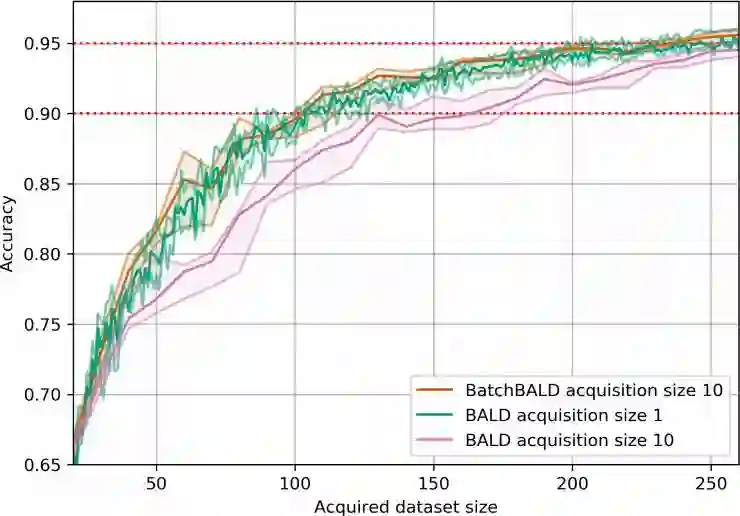
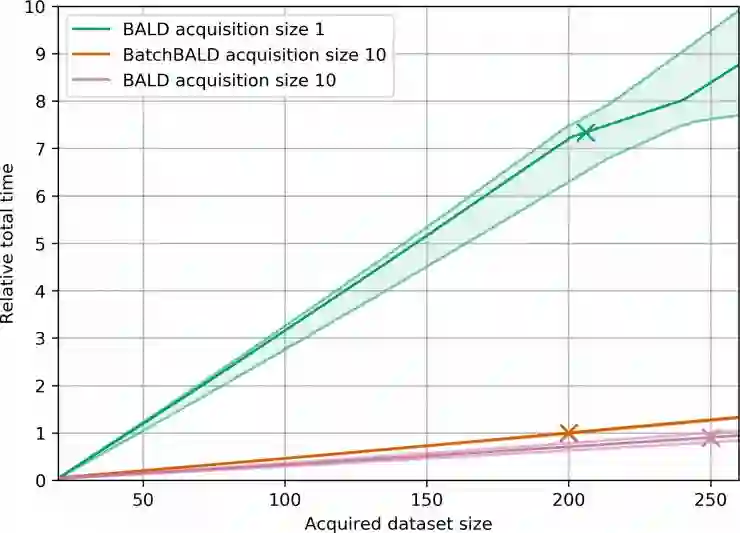
四、什么是BALD采集函数?
五、BatchBALD 采集函数
六、子模性
七、一致的蒙特卡罗 Dropout
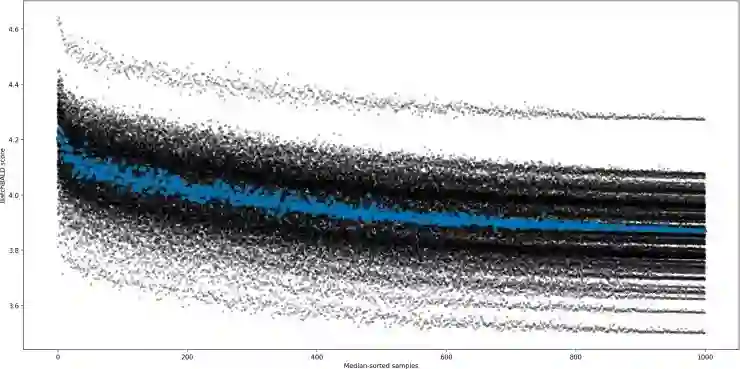
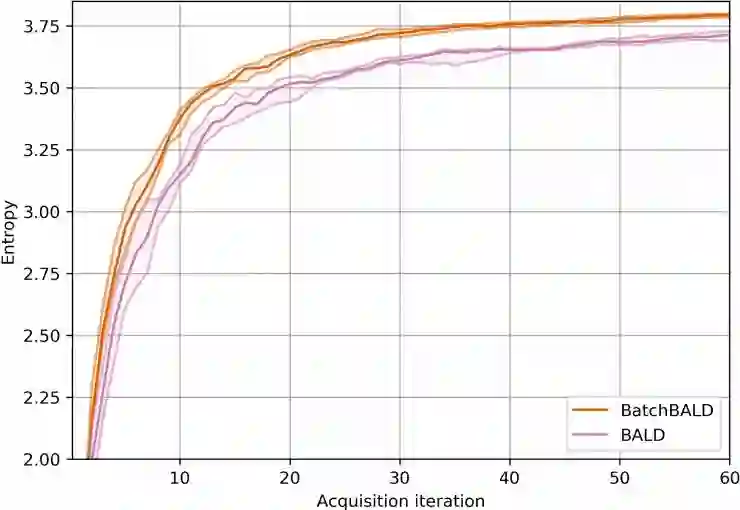
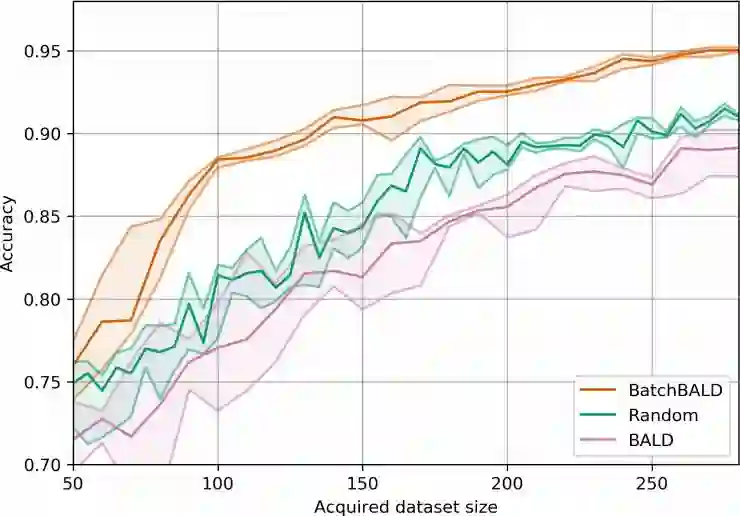
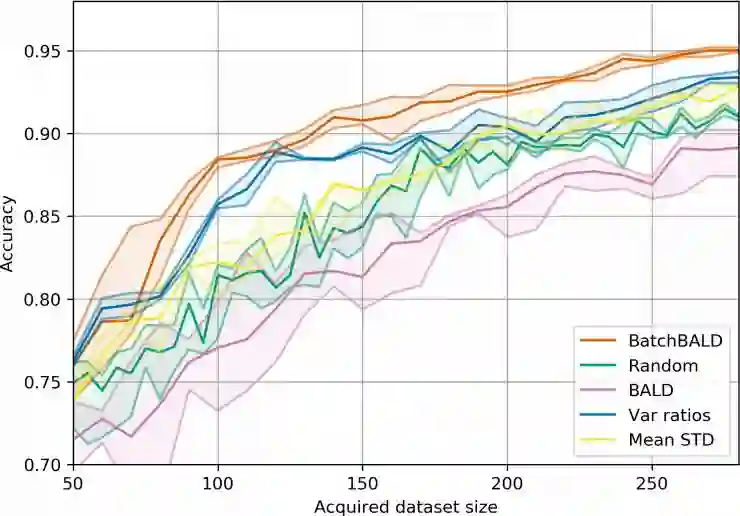
八、在 MNIST、重复的 MNIST以及 EMNIST 上进行实验

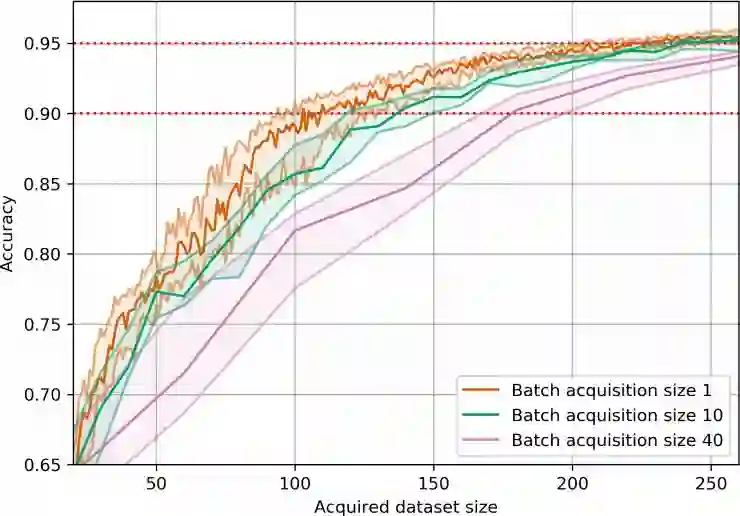
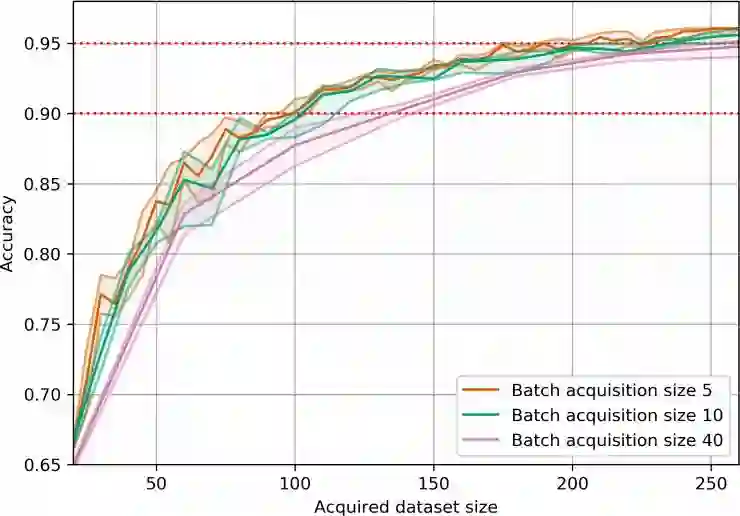
九、最后的一点想法
脚注:
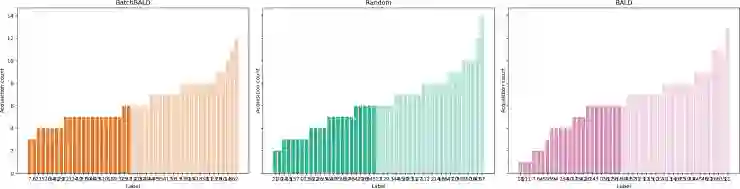
参考文献


 点击“
阅读原文
” 加入
AAAI 交流小组
点击“
阅读原文
” 加入
AAAI 交流小组
登录查看更多
相关内容



相关VIP内容
相关资讯
相关论文