塞尔原创 | IJCAI 2018 在消费意图识别任务上的基于树核最大平均差异的领域自适应
本文介绍哈尔滨工业大学社会计算与信息检索研究中心(HIT-SCIR)录用于IJCAI 2018的论文《Domain Adaptation via Tree Kernel Based Maximum Mean Discrepancy for User Consumption Intention Identification》[1]中的工作。在消费意图识别的领域自适应的任务上,我们引入了基于树核的最大平均差异来度量领域距离以学习到更好的领域不变的特征。我们在5个领域的消费意图识别的数据集上进行了实验,取得了SOTA的效果。
论文作者:丁效,蔡碧波,刘挺,石乾坤
关键词:消费意图识别 领域自适应 最大平均差异
联系邮箱:xding@ir.hit.edu.cn
个人主页:http://ir.hit.edu.cn/~xding/
1.引言
1.1 消费意图识别
人们通常会在社交平台上更新自己的动态,我们将这些统称为社会媒体信息。部分社会媒体信息中可能显式或者隐式的表达了人们对于某种商品的购买倾向,我们称之为消费意图。例如,“跟我一起去去看复联3吧!”这句话表明了该博主可能想要购买电影票。表1中举出了一些表达不同领域的消费意图的例子。消费意图识别的任务具有领域相关的特性[2],一个针对A领域(如购买电影票)训练出的模型,如果用来判别其他领域的数据(如购买手机)中是否包含了消费意图,模型的表现往往较差。所以在消费意图识别的任务上,如何进行领域自适应成了一个值得研究的问题。
表1 不同领域消意图示例

1.2 领域自适应
领域自适应问题(Domain Adaptation)是迁移学习(Transfer learning)的研究内容之一。其遵循了迁移学习问题的基本设定,即源领域和和目标域为不同的领域,且仅源领域有着丰富的监督信息。具体的,其有如下特征[3]:
特征空间一致
类别空间一致
特征分布不一致
该问题的目标是希望能够最大限度地利用有源领域的有监督信息,辅助目标领域的训练,使得即使是在弱监督或者无监督的情况下,在目标领域上仍能取得良好的分类效果。其中主要需要解决两个问题,一是如何进行领域之间分布差异的度量,二是如何学习到更有效的领域之间可迁移的特征,即领域不变量。在领域分布差异度量的问题上,最大平均差异(MMD)[4]被证明是一个有效的办法。其公式为:
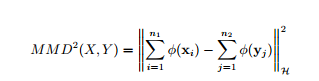
MMD实际上是一种双样本检验的方法,当MMD的结果为零时,说明两个整体服从同样的分布。其中是映射,代表将原向量投影到高维希尔伯特空间中。作为一种核方法,使用MMD进行双样本检验的效果与核的选取息息相关。
对于如何更有效的学习到领域不变量的问题,最近的研究表明深度神经网络具有良好的可迁移性。但是,在神经网络的一层一层前向传播的过程中,学习到的特征的可迁移性将会逐渐变差。故对于神经网络末端的领域私有层,需要使用小部分的目标领域的有标注数据进行finetune以达到较好的效果。
在本文中,我们提出了基于树核最大平均差异的领域自适应的消费意图识别的模型来解决上述的两个问题。由于基于MMD的双样本检验的效果取决与核的选取,且树核函数在NLP任务中被广泛使用,故我们采用了一个基于树核的方法来进行领域差异的度量。另外,我们使用了Tree-Lstm捕捉自然语言的结构化信息。
2. 模型介绍
在本文中,我们提出了领域迁移的消费意图识别模型(DACI),其结构如图1所示,我们将介绍模型的整体的训练过程,并具体介绍模型使用的损失函数及相关意义。
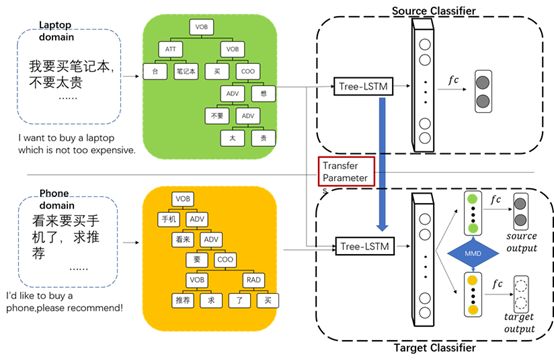
图1 DACI结构示意图
如图1所示,我们先使用源领域的有标注的数据训练得到有标注的模型1,其损失函数如下:
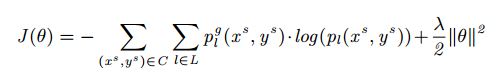
即我们希望训练得到的模型能在源领域上取得尽可能高的准确率。
但是,由于模型学习到的特征具有领域独立性,故模型1不能直接用于目标领域数据的预测。在本文中,我们将模型1的Tree-lstm层的参数作为模型2的预训练的参数。模型2即为最终对目标领域数据进行分类的模型。我们期望随着训练轮数的增加,源域和目标域的数据经Tree-lstm变化得到的特征的分布能够越来越相近。这可以通过对上式添加TK-MMD函数来实现。
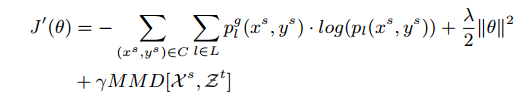
3. 实验结果
3.1 数据集
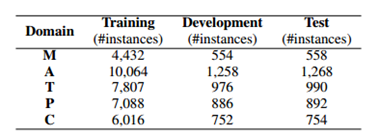
因为目前并没有公开的用于评估消费意图识别任务的数据集,所以我们自行手动标注了实验数据集。我们的数据集中包含了5个领域,分别是订火车票,订飞机票,买手机,买电脑,买电影票,其训练集,验证集,和测试集。这些数据随后将会公开。数据集的相关细节如表2所示。
表2 数据集样本数
3.2 实验结果
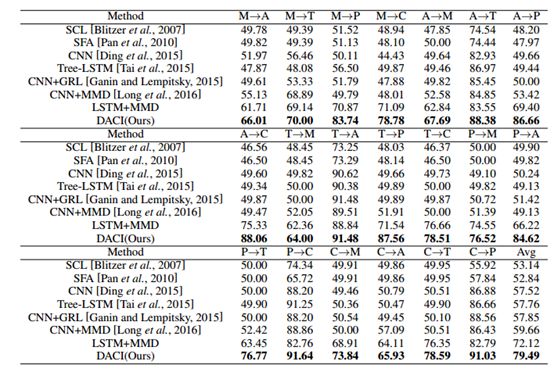
我们使用我们的模型在五个数据集上进行两两之间的相互迁移实验。表3中展示了本文的实验结果。
在所有的领域的迁移上,我们的模型都取得了最好的结果,有较强的稳定性。
通过与传统的非深度学习方法SCL, SFA比较,说明深度学习的模型有更强的表示能力,可以学习到更通用的特征适用于领域迁移。
通过比较单独的CNN和Tree-lstm的结果,说明了由于消费意图识别的领域相关的特性,在源域上训练得到的模型不可直接用于目标领域的分类。
通过比较LSTM+MMD和CNN+MMD的结果,说明基于树核的TK-MMD比传统的MMD能更有效的提升模型的迁移能力。
表3 实验结果对比
4. 结语
本文中我们构建了一个跨领域的无监督学习的消费意图识别的深度学习模型。在模型中,我们充分利用了深度神经网络和双样本检验的优势,使用TK-MMD来提升模型学习到的特征的可迁移性。我们在5个领域的数据上进行了两两迁移的实验,结果证明了我们的模型的优越性。最后,我们的模型也有充分的通用性,也可适用于其他的需要进行领域自适应的自然语言处理任务中。
5. 参考文献
[1] Xiao Ding, Bibo Cai,Ting Liu, Qiankun Shi. Domain Adaptation via Tree Kernel Based Maximum Mean Discrepancy for User Consumption Intention Identification, To appear in IJCAI 2018.
[2] Xiao Ding, Ting Liu, Junwen Duan, and Jian-Yun Nie. Mining user consumption intention from social media using domain adaptive convolutional neural network.In AAAI, 2015.
[3] SJ Pan, Q Yang. A survey on transfer learning. In TKDE, 2010.
[4] Sinno Jialin Pan, James T Kwok, and Qiang Yang. Transfer learning via dimensionality reduction. In AAAI, 2008.
本期责任编辑: 赵森栋
本期编辑: 赵怀鹏
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,赵森栋,刘一佳
编辑: 李家琦,赵得志,赵怀鹏,吴洋,刘元兴,蔡碧波,孙卓
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。