从α到μ:DeepMind棋盘游戏AI进化史
选自towardsdatascience
alpha(α)是希腊字母表的第 1 个字母,代表起点;mu(μ)是第 12 个,代表中途。从书写了传奇的 AlphaGo 开始,DeepMind 一直在不断更新迭代这一系列的新算法,创造了 AlphaGo Zero、AlphaZero 和 MuZero。通用性更强的 MuZero 算法不仅能出色地掌握棋盘游戏,而且还在 57 款不同的 Atari 游戏上达到了超越人类的水平。
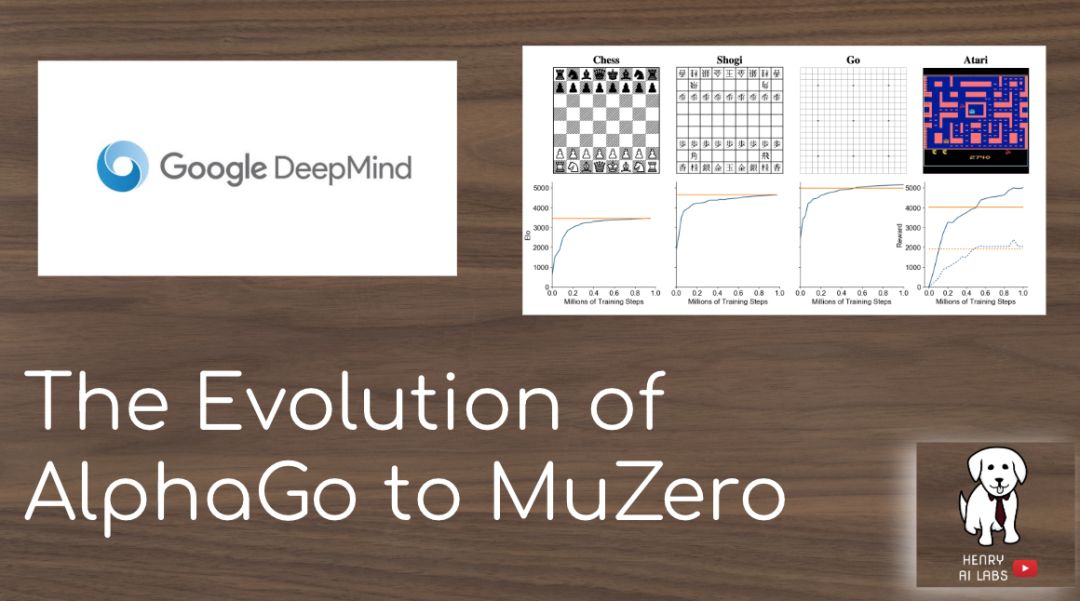
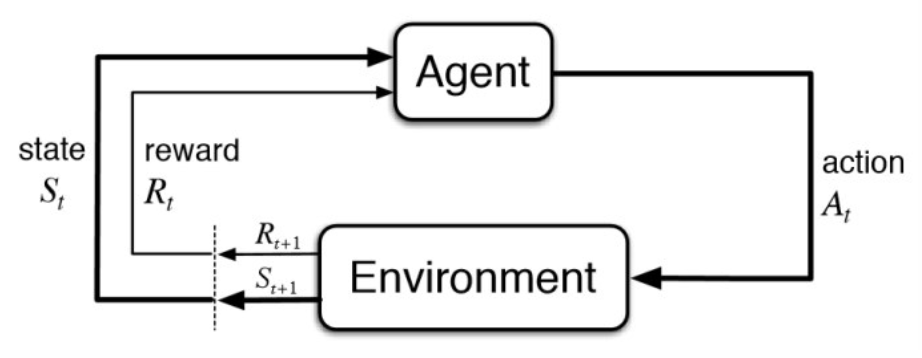
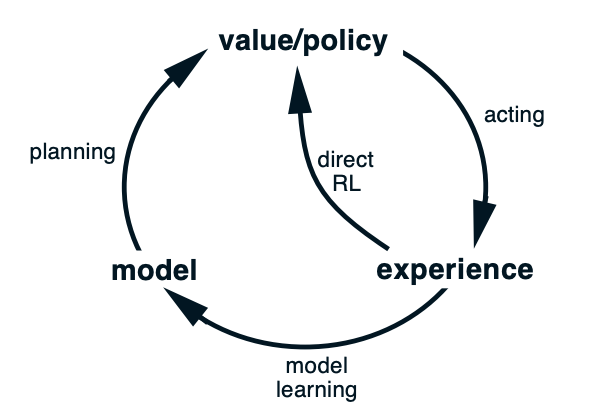
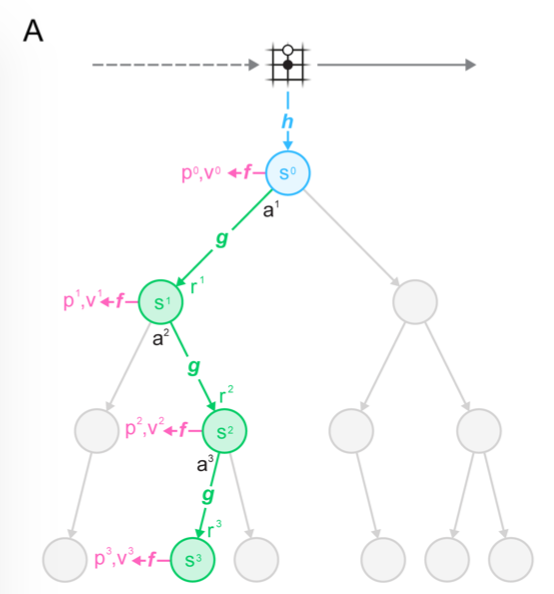
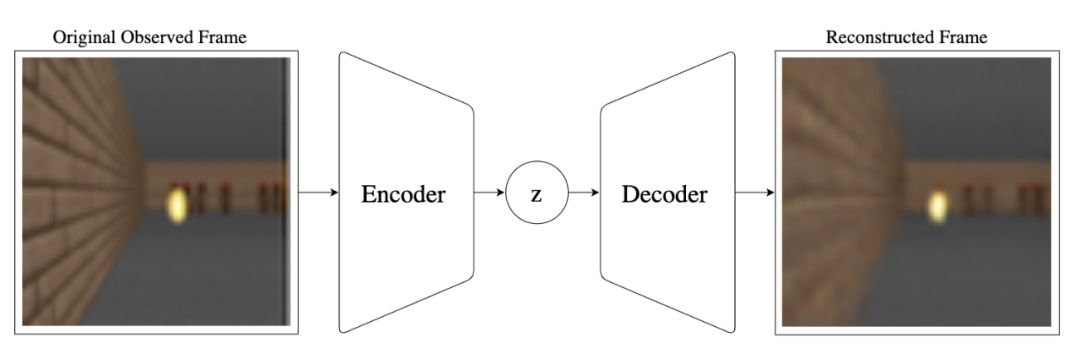
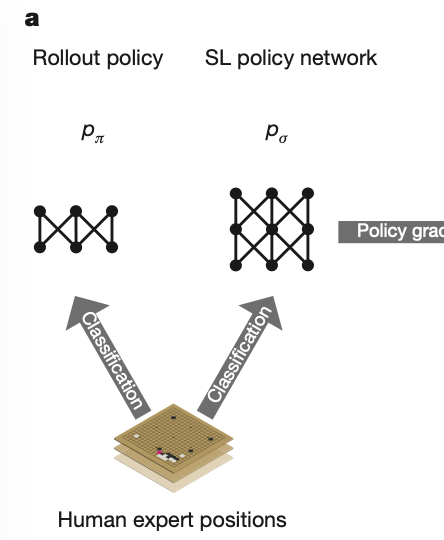
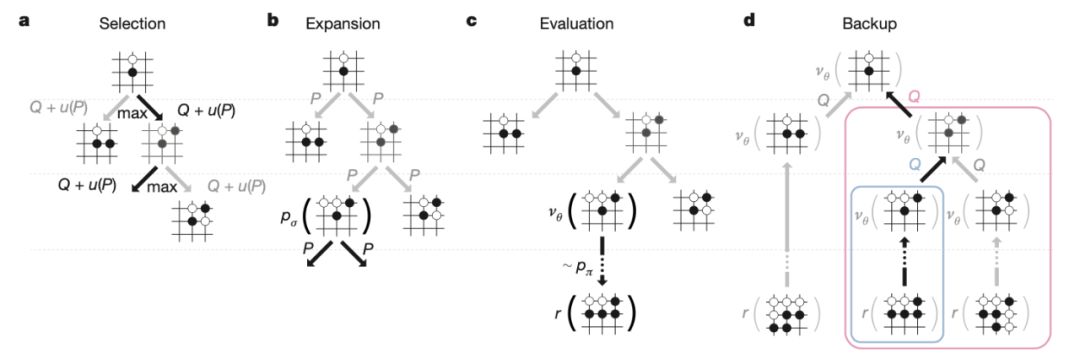
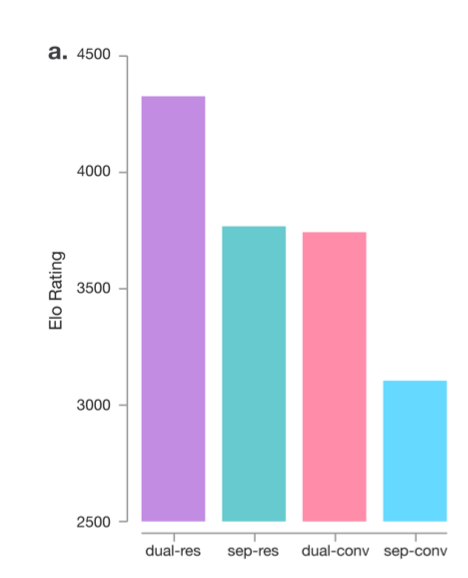
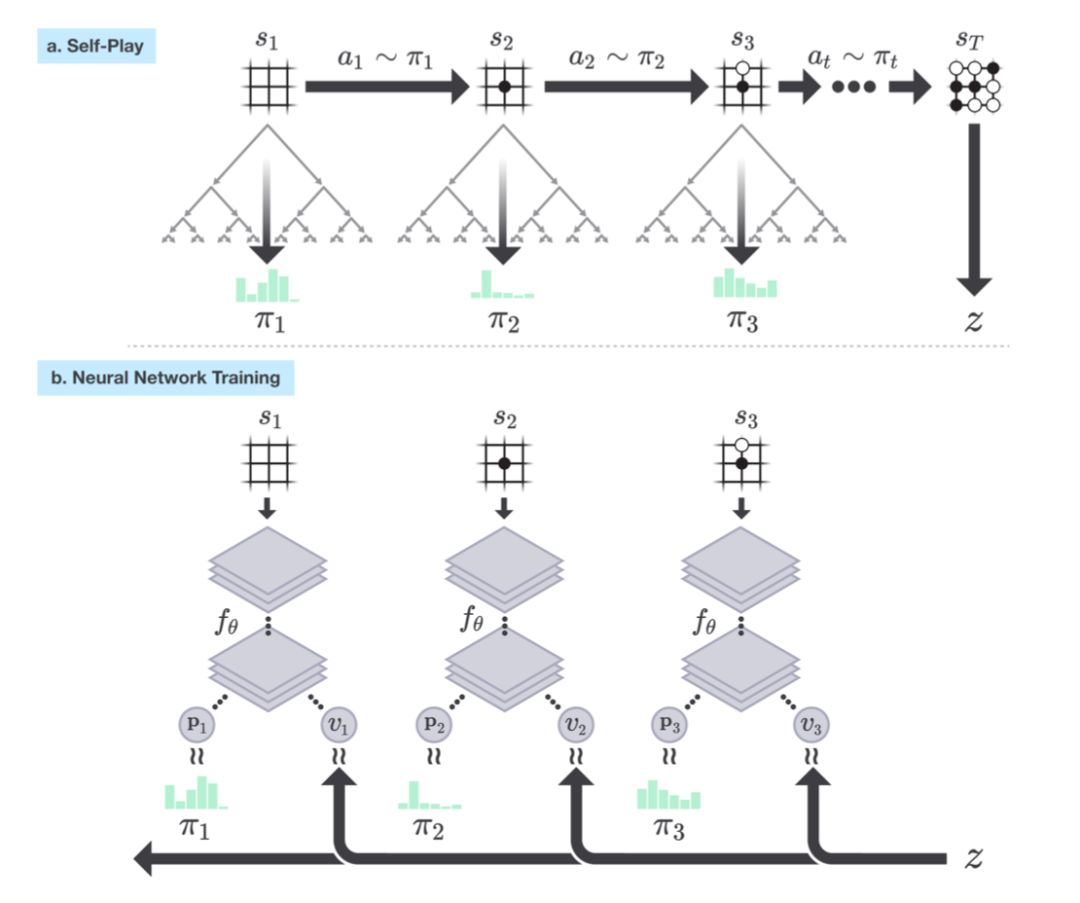
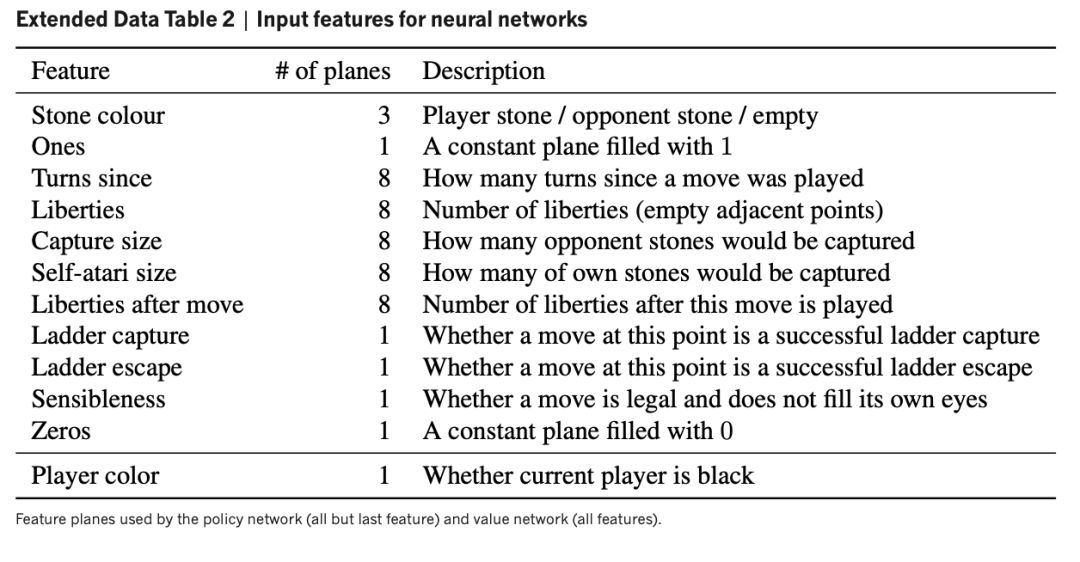

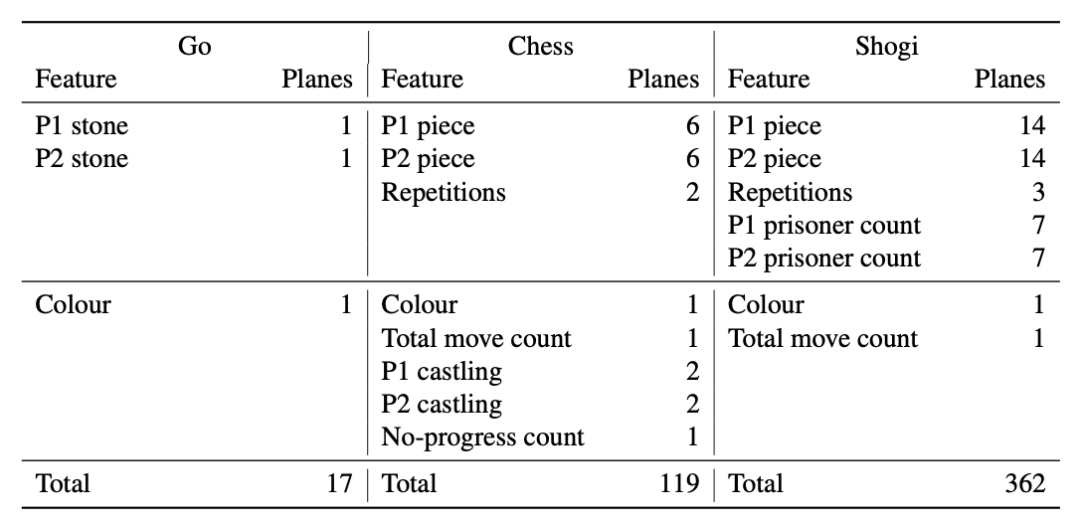
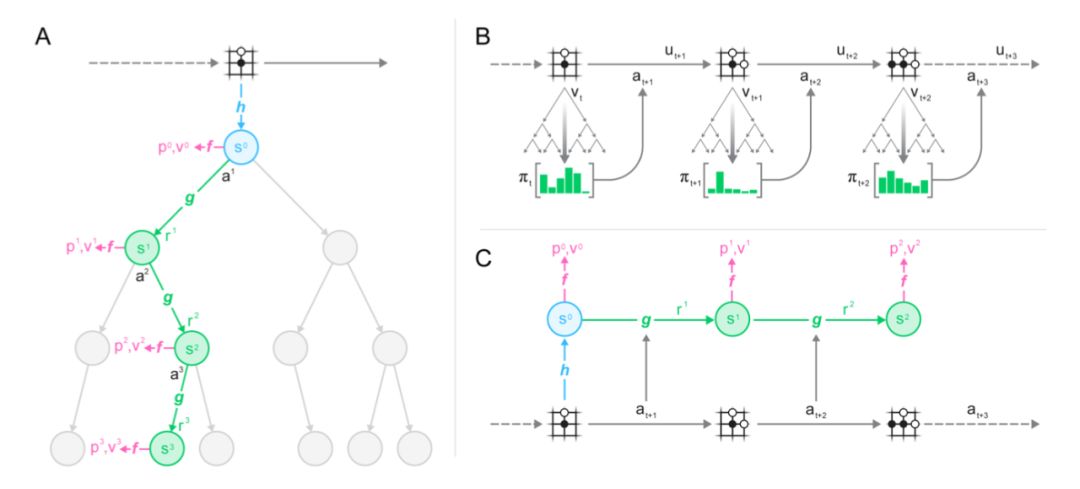

AlphaGo: https://www.nature.com/articles/nature16961
AlphaGo Zero: https://www.nature.com/articles/nature24270
AlphaZero: https://arxiv.org/abs/1712.01815
MuZero: https://arxiv.org/abs/1911.08265
登录查看更多
相关内容

专知会员服务
48+阅读 · 2019年12月24日
Arxiv
6+阅读 · 2018年4月7日


相关VIP内容
专知会员服务
48+阅读 · 2019年12月24日
相关资讯
相关论文
Arxiv
6+阅读 · 2018年4月7日