【斯坦福CS229】一文横扫机器学习要点:监督学习、无监督学习、深度学习

新智元·开发者专栏
来源:stanford.edu
编译:三石
【新智元导读】提及机器学习,很多人会推荐斯坦福CSS 229。本文便对该课程做了系统的整理。包括监督学习、非监督学习以及深度学习。可谓是是学习ML的“掌上备忘录”。
斯坦福CS229—机器学习:
监督学习
非监督学习
深度学习
监督学习简介
给定一组与输出{y(1),...,y(m)}相关联的数据点{x(1),...,x(m)},我们希望构建一个能够根据x值预测y值的分类器。
预测类型—下表归纳了不同类型的预测模型

模型类型—下表归纳了不同的模型

符号和概念
假设—记一个假设为 hθ,且是我们选择的一个模型。给定一组输入数据x(i),则模型预测输出为hθ(x(i))。
损失函数—一个损失函数可表示为L:(z,y)∈R×Y⟼L(z,y)∈R,它将与实际数据值y对应的预测值z作为输入,并输出它们之间的差异。常见的损失函数归纳如下:

成本函数—成本函数J通常用于评估模型的性能。用损失函数L定义如下:
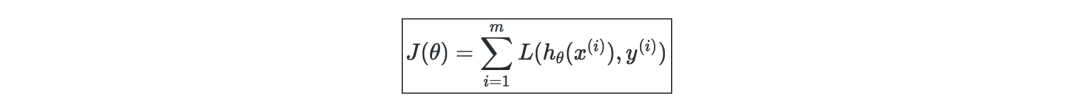
梯度下降—若学习率表示为 α∈R,则用学习率和成本函数J来定义梯度下降的更新规则,可表示为如下公式:
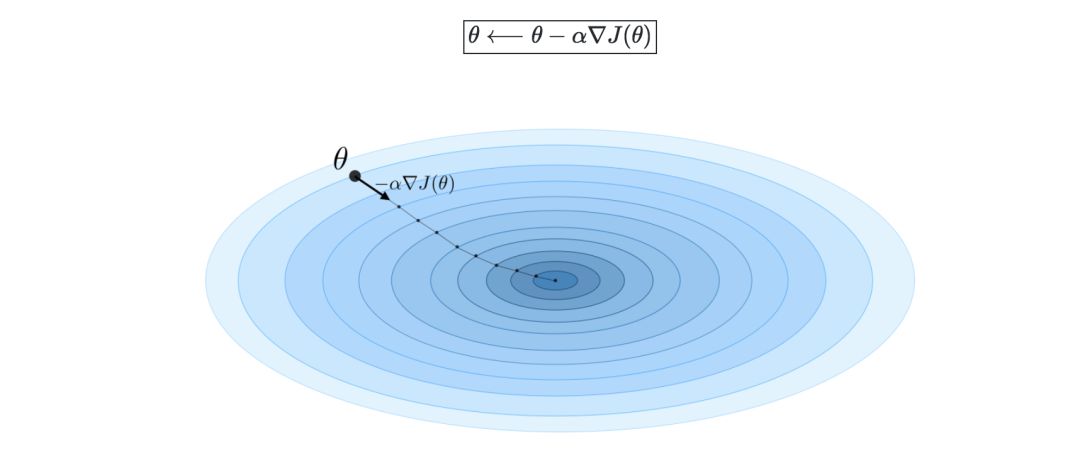
随机梯度下降法(SGD)是根据每个训练样本对参数进行更新,批量梯度下降法是对一批训练样本进行更新
似然—一个模型的似然(给定参数 L(θ)),是通过将其最大化来寻找最优参数θ。在实际过程中,我们一般采用对数似然 ℓ(θ)=log(L(θ)),因其优化操作较为容易。可表示如下:
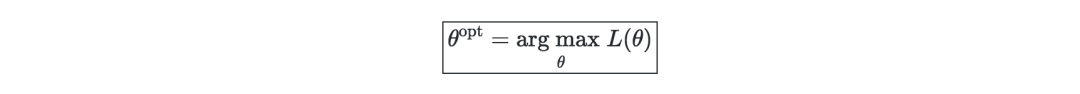
牛顿迭代法—是一种数值方法,用于找到一个θ,使 ℓ′(θ)=0成立。其更新规则如下:
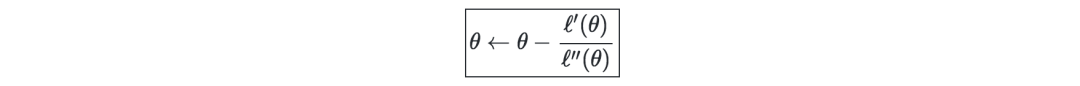
线性模型
线性回归
我们假设 y|x;θ∼N(μ,σ2)。
正规方程(Normal Equation)—记X为矩阵,能使成本函数最小化的θ的值是一个封闭的解:
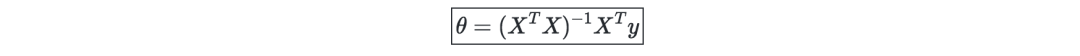
最小均方算法(LMS)—记 α为学习率,对一个包含m个数据点的训练集的LMS算法的更新规则(也叫Widrow-Hoff学习规则),如下所示:
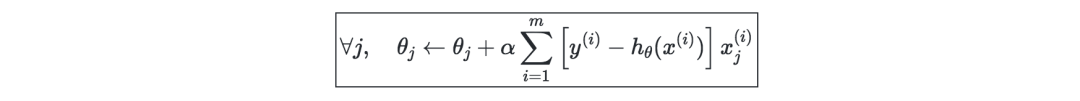
局部加权回归(LWR)—是线性回归的一种变体,它将每个训练样本的成本函数加权为w(i)(x),用参数 τ∈R可定义为:
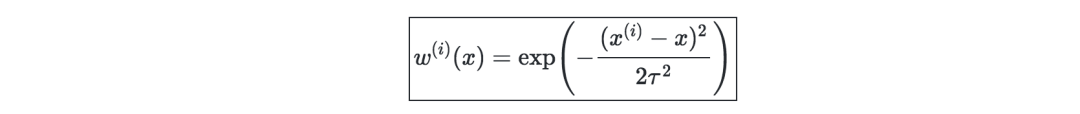
分类和逻辑回归
Sigmoid函数—即S型函数,可定义为:
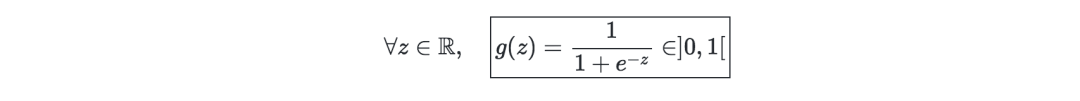
逻辑回归—一般用于处理二分类问题。假设y|x;θ∼Bernoulli(ϕ),可有如下形式:
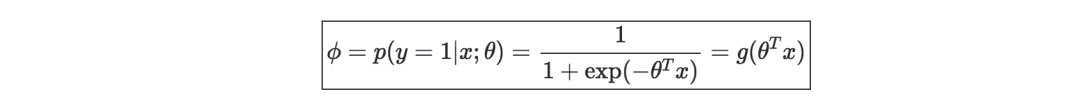
Softmax回归—是逻辑回归的推广,一般用于处理多分类问题,可表示为:
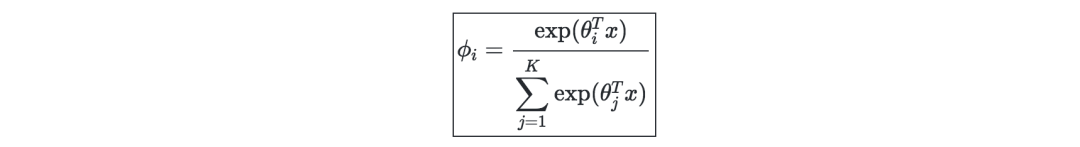
广义线性模型
指数族(Exponential family )—若一类分布可以用一个自然参数来表示,那么这类分布可以叫做指数族,也称作正则参数或连结函数,如下所示:
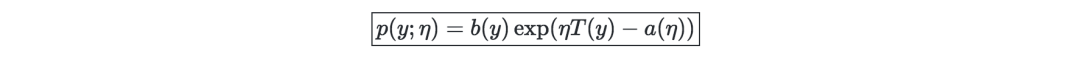
下表是常见的一些指数分布:
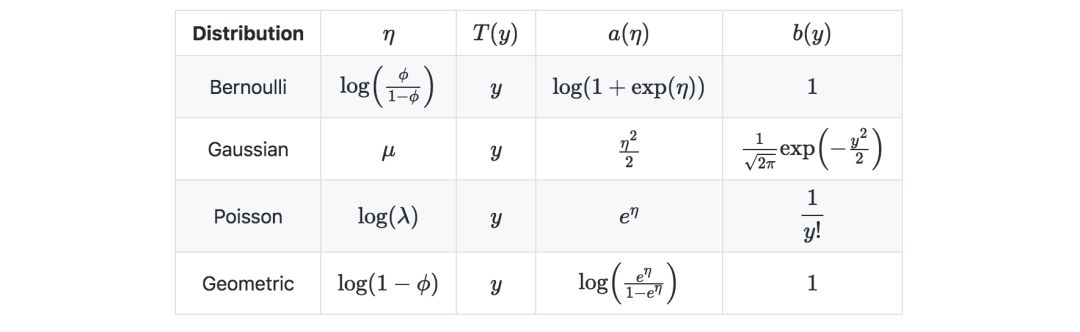
广义线性模型的假设—广义线性模型旨在预测一个随机变量y,作为x∈Rn+1的函数,并且以来于以下3个假设:
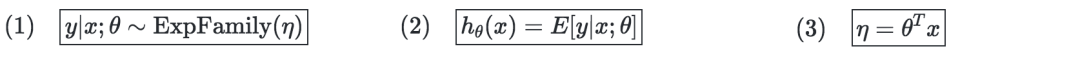
支持向量机
通俗来讲,支持向量机就是要找到一个超平面,对样本进行分割。
最优边缘分类器—以h表示,可定义为:
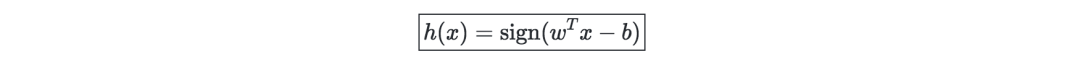
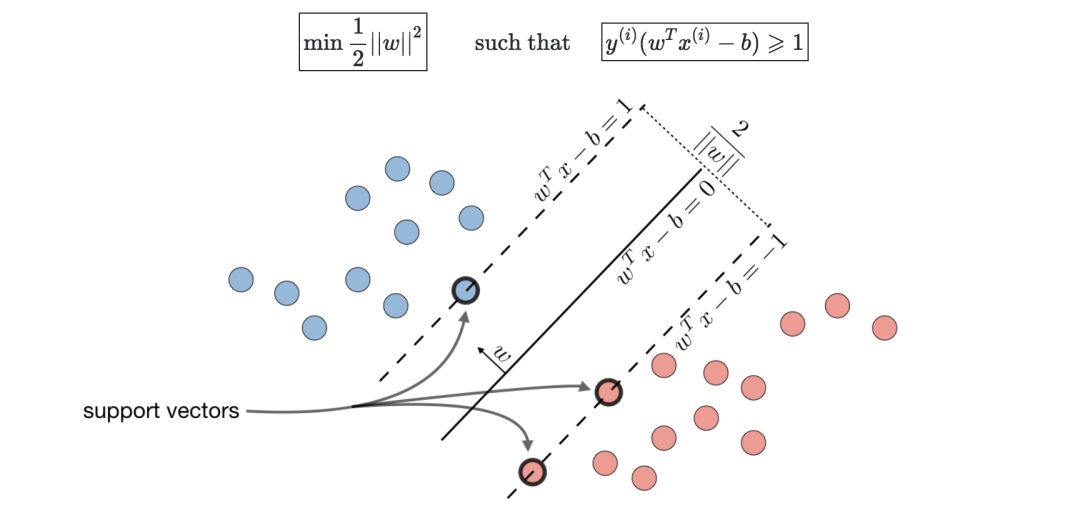
其中,(w,b)∈Rn×R是如下最优问题的解:
Hinge损失—用于SVM的设置,定义如下:
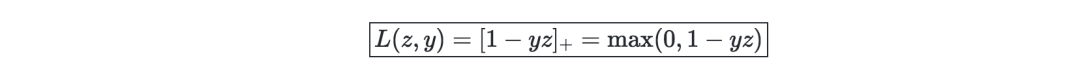
核(Kernel)—给定一个特征映射ϕ,核可以表示为:
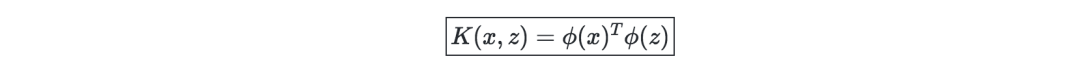
在实际问题当中,高斯核是较为常用的。
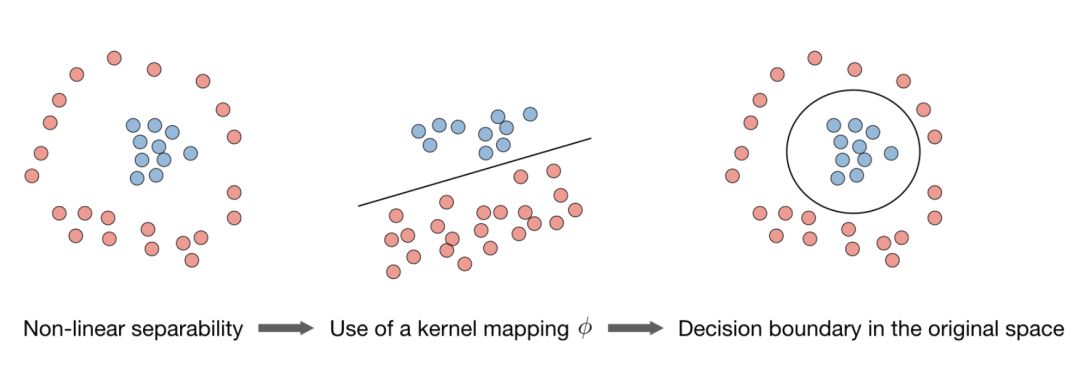
我们一般不需要知道XX的显式映射,只需要知道K(x,z)的值即可
拉格朗日—我们定义拉格朗日L(w,b)为:
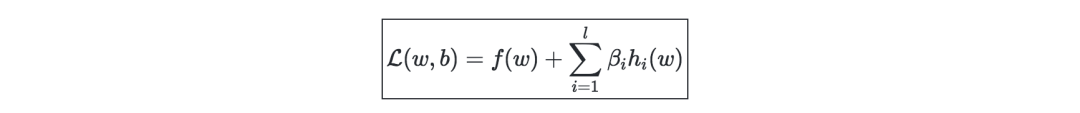
生成学习
生成模型首先尝试通过估计P(x|y)来了解数据是如何生成的,而后我们可以用贝叶斯规则来估计P(y|x)。
高斯判别分析
Setting—高斯判别分析假设存在y、x|y=0和x|y=1,满足:

估计—下表总结了最大化似然时的估计:
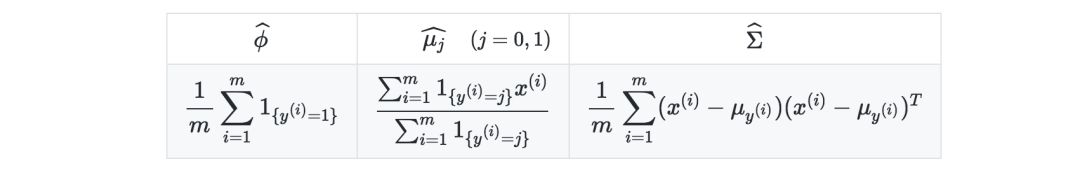
朴素贝叶斯
假设—朴素贝叶斯模型假设每个数据点的特征都是独立的:
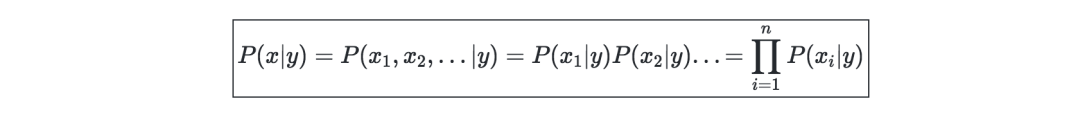
解决方案—当 k∈{0,1},l∈[[1,L]]时,最大化对数似然给出了如下解决方案:
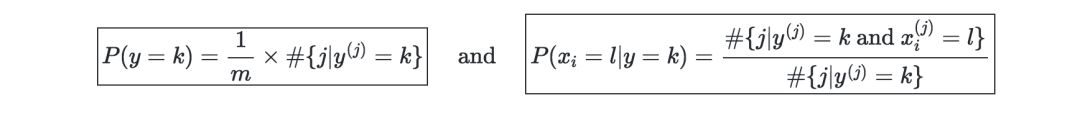
基于树方法和集成方法
即可用于回归,又可用于分类的方法。
决策树—分类和回归树(CART),非常具有可解释性特征。
Boosting—其思想就是结合多个弱学习器,形成一个较强的学习器。
随机森林—在样本和所使用的特征上采用Bootstrap,与决策树不同的是,其可解释性较弱。
其它非参数方法
KNN—即k近邻,数据点的响应由其k个“邻居”的性质决定。
学习理论(Learning Theory)
Union Bound—令A1,...,Ak为k个事件,则有:

Hoeffding inequality —刻画的是某个事件的真实概率与m各不同的Bernoulli试验中观察到的频率之间的差异。
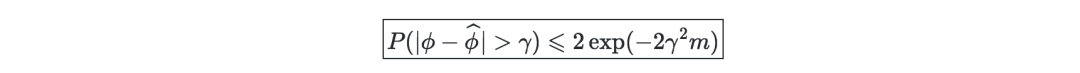
训练误差—给定一个分类器h,我们将训练误差定义为error ˆϵ(h),也被称作经验风险或经验误差,如下所示:
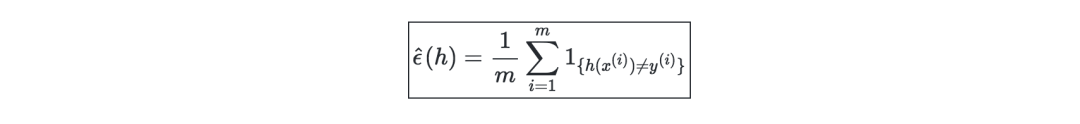
Probably Approximately Correct—即PAC,是一个框架,在此框架下,许多关于学习理论的结果都得到了证明,并且有以下一组假设:
训练和测试集遵循相同的分布
训练样本是独立绘制的
除上述学习理论之外,还有Shattering、上限定理、VC维、Theorem (Vapnik)等概念,读者若感兴趣,可由文末链接进入原文做进一步了解。
非监督学习简介
无监督学习旨在无标记数据中发现规律。
詹森不等式—令f为凸函数、X为一个随机变量。将会有如下不等式:
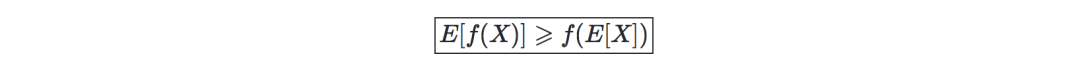
聚类
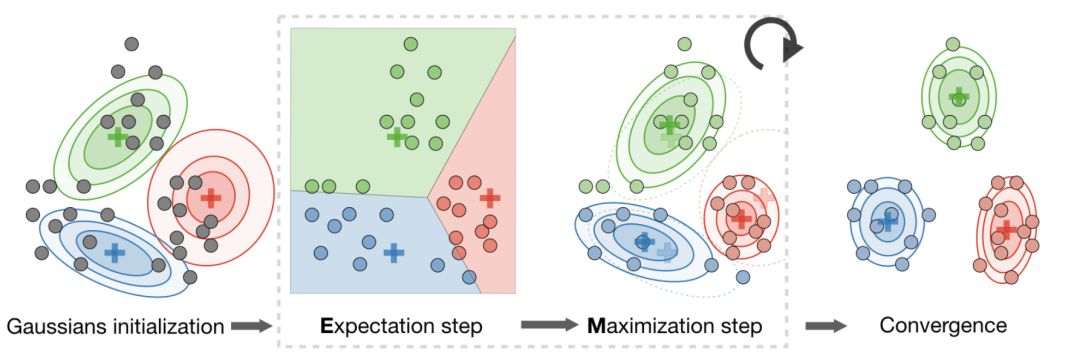
最大期望算法(EM)
隐变量—是指使估计问题难以解决的隐藏/未观察到的变量,通常表示为z。下表是涉及到隐变量的常用设置:

算法—EM算法通过重复构建似然下界(E-step)并优化该下界(M-step)来给出通过MLE估计参数θ的有效方法,如下:
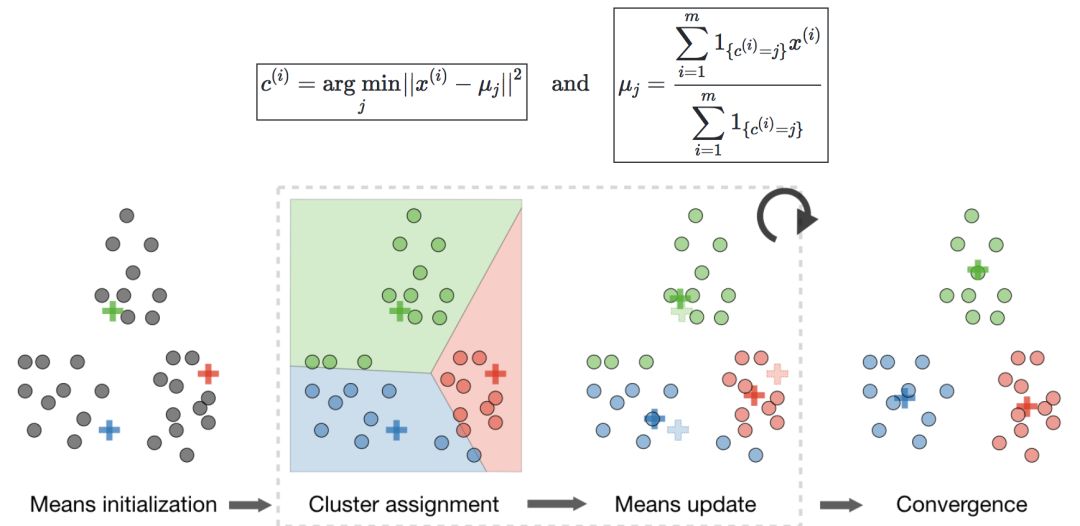
k-means聚类
令c(i)表示为数据点i的类,μj为类j的中心。
算法—在随机初始化聚类质心μ1,μ2,...,μk∈Rn之后,k均值算法重复以下步骤直到收敛:
失真函数(distortion function)—为了查看算法是否收敛,定义如下的失真函数:
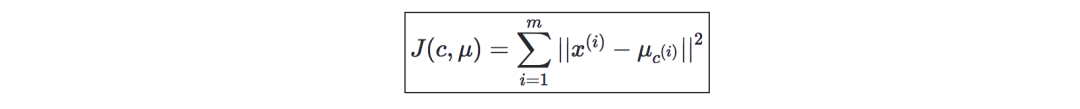
分层聚类
算法—它是一种聚类算法,采用聚合分层方法,以连续方式构建嵌套的聚类。
类型—为了优化不同的目标函数,有不同种类的层次聚类算法,如下表所示:

聚类评估指标
在无监督的学习环境中,通常很难评估模型的性能,因为没有像监督学习环境中那样的ground-truth标签。
轮廓系数—记a为一个样本和同一个类中其它点距离的平均,b为一个样本与它最近的类中所有点的距离的平均。一个样本的轮廓系数可定义为:
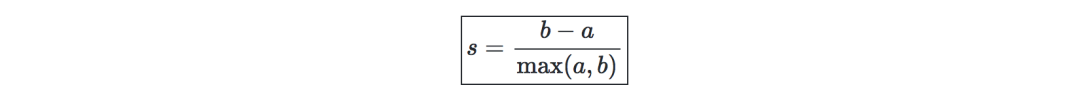
Calinski-Harabaz指数—记k为类的数量,XX和XX是类间、类内矩阵的dispersion矩阵分别表示为:
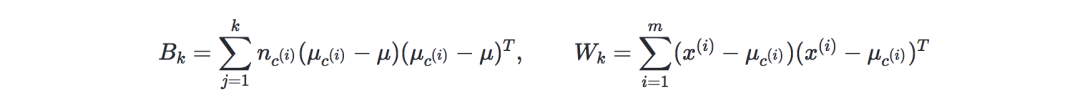
Calinski-Harabaz指数s(k)表明了聚类模型对聚类的定义的好坏,得分越高,聚类就越密集,分离得也越好。定义如下:
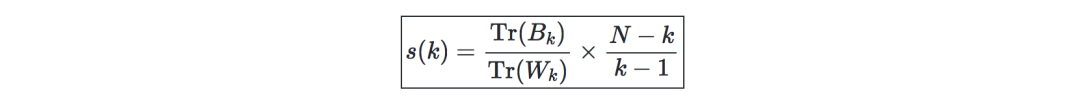
降维
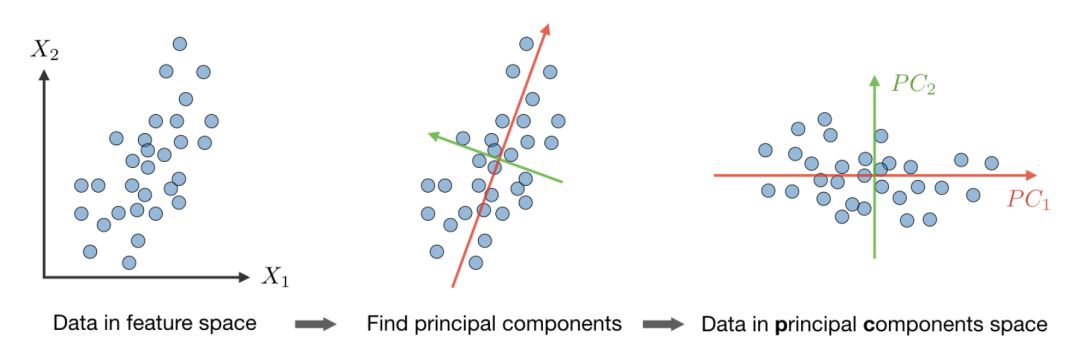
主成分分析
主成分分析是一种统计方法。通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫主成分。
特征值、特征向量—给定一个矩阵A∈Rn×n,如果存在一个向量z∈Rn∖{0},那么λ就叫做A的特征值,而z称为特征向量:
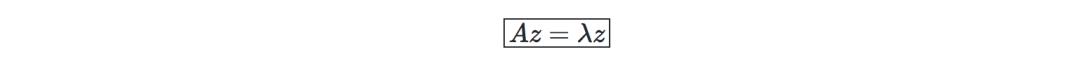
普定理(Spectral theorem)—令A∈Rn×n。若A是对称的,那么A可以通过实际正交矩阵U∈Rn×n对角化。记Λ=diag(λ1,...,λn),我们有:
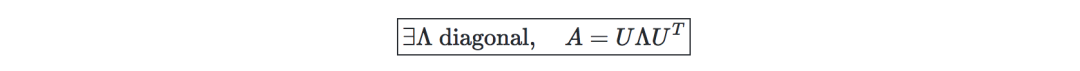
算法—主成分分析(PCA)过程是一种降维技术,通过使数据的方差最大化,在k维上投影数据,方法如下:
第一步:将数据标准化,使其均值为0,标准差为1。
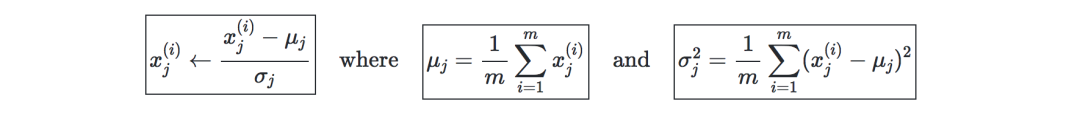
第二步:计算
,它与实特征值对称。
第三步:计算Σ的k个正交主特征向量,即k个最大特征值的正交特征向量。
第四步:在spanR(u1,...,uk)上投射数据。
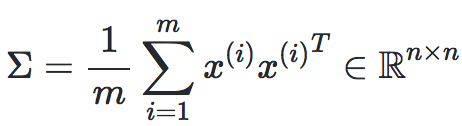 ,它与实特征值对称。
,它与实特征值对称。这个过程使所有k维空间的方差最大化。
独立分量分析
这是一种寻找潜在生成源的技术。
假设—我们假设数据x是通过混合和非奇异矩阵A,由n维源向量 s=(s1,...,sn)生成的(其中,si是独立的随机变量),那么:
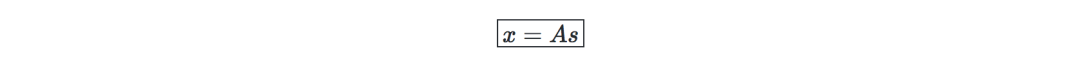
目标是找到混合矩阵W=A−1
Bell和Sejnowski的ICA算法—该算法通过以下步骤找到解混矩阵W:
将x=As=W−1sx=As=W−1s的概率表示为:
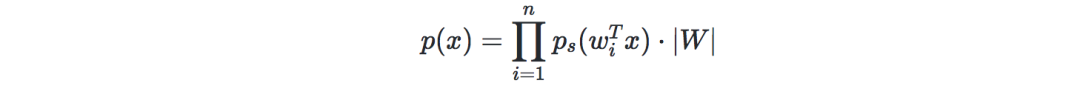
记g为sigmoid函数,给定我们的训练数据{x(i),i∈[[1,m]]},则对数似然可表示为:
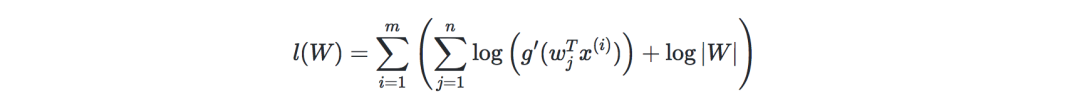
因此,随机梯度上升学习规则是对于每个训练样本x(i),我们更新W如下:

神经网络
神经网络是一类用层构建的模型。常用的神经网络类型包括卷积神经网络和递归神经网络。
结构—关于神经网络架构的描述如下图所示:
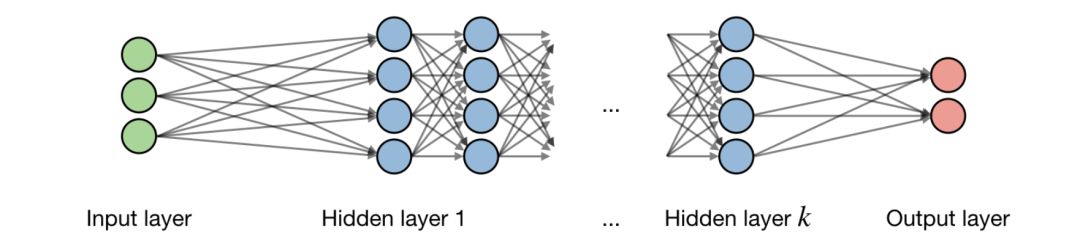
记i为网络中的第i层,j为一个层中第j个隐含单元,这有:
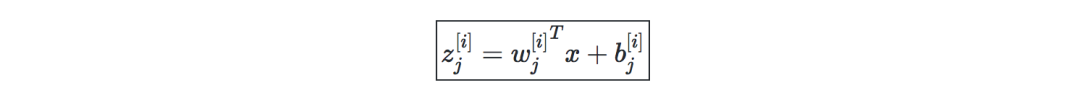
激活函数—在隐含单元的末端使用激活函数向模型引入非线性复杂性。以下是最常见的几种:
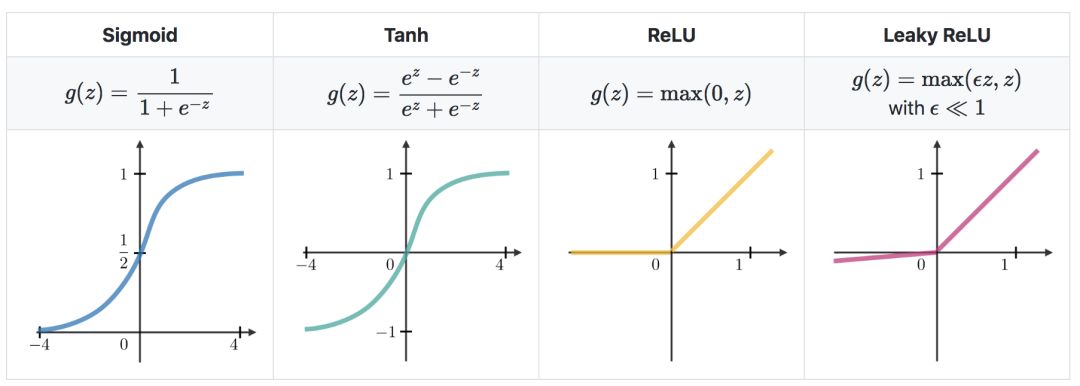
交叉熵损失-在神经网络中,交叉熵损失L(z,y)是常用的,定义如下:
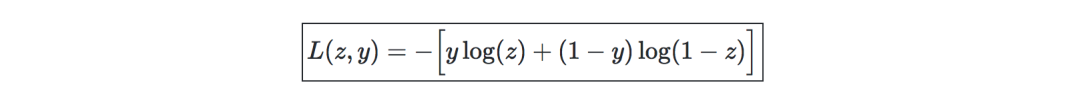
学习率—通常被记作α或η,可表明在哪一步权重得到了更新。这可以被修正或自适应的改变。目前最流行的方法是Adam,这是一种适应学习率的方法。
反向传播—是一种通过考虑实际输出和期望输出来更新神经网络权重的方法。关于权重w的导数是用链式法则计算的,它的形式如下:
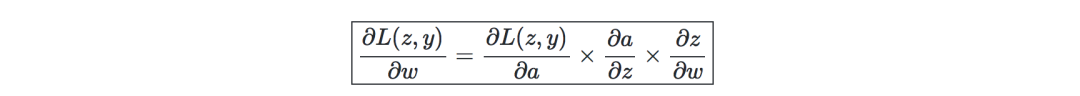
因此,权重更新如下:
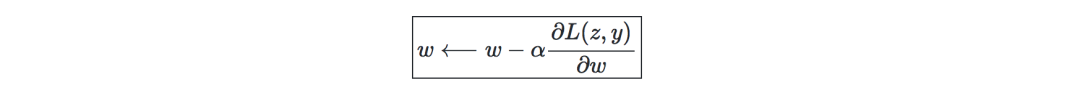
更新权重—在神经网络中,权重的更新方式如下:
第一步:对训练数据取一个batch;
第二步:进行正向传播以获得相应的损失;
第三步:反向传播损失,得到梯度;
第四步:使用梯度更新网络的权重。
Dropout—是一种通过在神经网络中删除单元来防止过度拟合训练数据的技术。
卷积神经网络
超参数—在卷积神经网络中,修正了以下超参数:

层的类型—在卷积神经网络中,我们可能遇到以下类型的层:

卷积层要求—记W为输入量大小,F为卷积层神经元大小,P是zero padding的数量,那么在给定体积(volumn)内的神经元数量N是这样的:
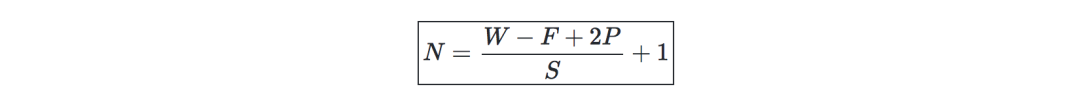
Batch归一化—记γ,β为我们想要更正的batch的均值和方差,则:
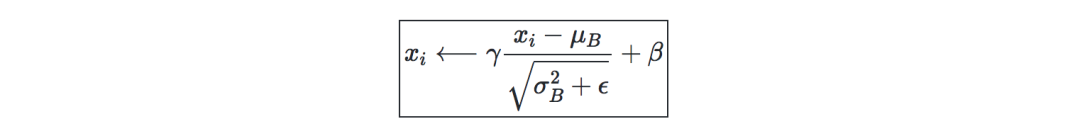
它通常是在完全连接/卷积层和非线性层之前完成的,目的是提高学习率并减少对初始化的强烈依赖。
递归神经网络
gate的类型—以下是在典型递归神经网络中存在的不同类型的gate:

LSTM—该网络是一种RNN模型,它通过添加“forget” gates来避免梯度消失问题。
强化学习与控制
强化学习的目标是让智能体学会如何在环境中进化。
马尔科夫决策过程—即MDP,是一个五元组 (S,A,{Psa},γ,R),其中:
S是一组状态;
A是一组行为;
{Psa}是s∈S和 a∈A的状态转换率;
γ∈[0,1]是discount系数;
R:S×A⟶R或R:S⟶R是算法要最大化的奖励函数
加粗:策略—是一个函数 π:S⟶A,是将状态映射到行为中。
加粗:Value Function—给定一个策略π和状态s,可定义value functionVπ
为:
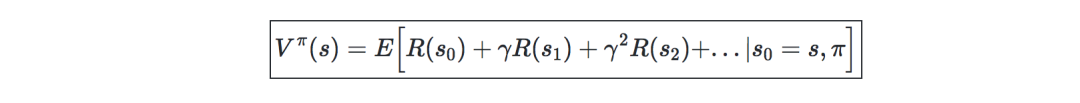
贝尔曼方程—最优贝尔曼方程刻画了最优策略π的value function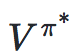
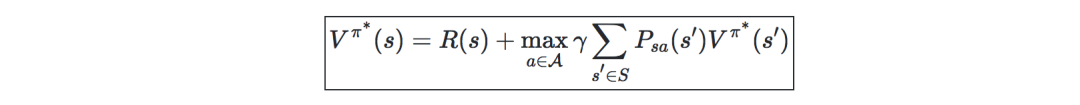
Value迭代算法—主要分为两个步骤:
初始化value:
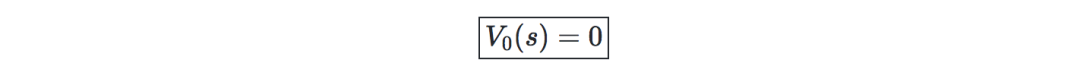
基于之前的value进行迭代:
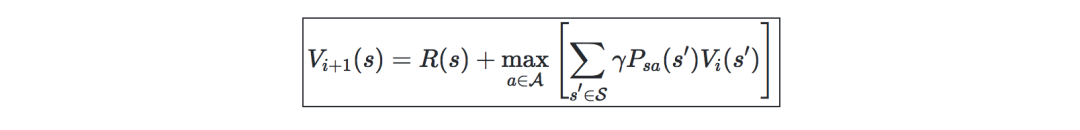
最大似然估计—状态转移概率的最大似然估计如下:

Q-Learning—是Q一种无模型估计,公式如下:
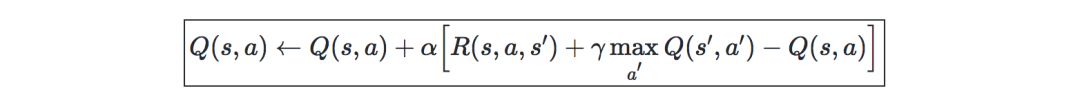
参考链接:
https://stanford.edu/~shervine/teaching/cs-229/
新智元AI WORLD 2018大会倒计时26天
门票已开售!
新智元将于9月20日在北京国家会议中心举办AI WORLD 2018 大会,邀请机器学习教父、CMU教授 Tom Mitchell,迈克思·泰格马克,周志华,陶大程,陈怡然等AI领袖一起关注机器智能与人类命运。
大会官网:
http://www.aiworld2018.com/

活动行购票链接:
http://www.huodongxing.com/event/6449053775000
活动行购票二维码:




