让AI自己写AI?AlphaGo Zero之后,谷歌提出从零开始摸索AI算法的AutoML-Zero

AutoML Zero能发现什么

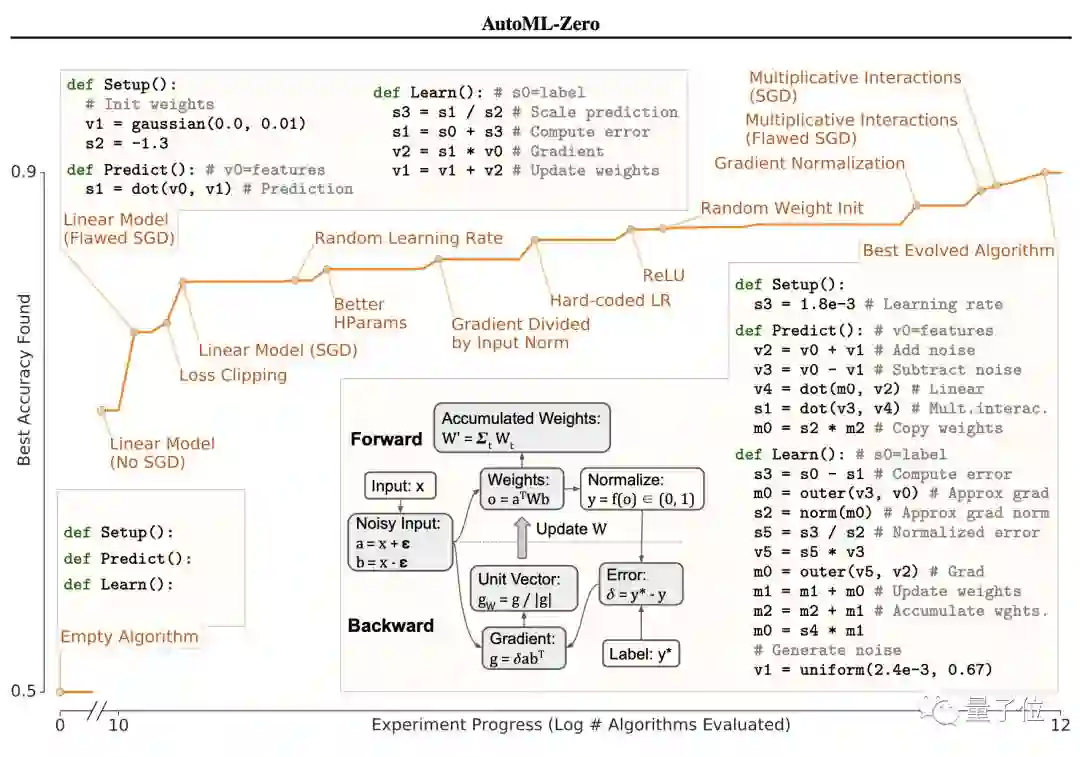
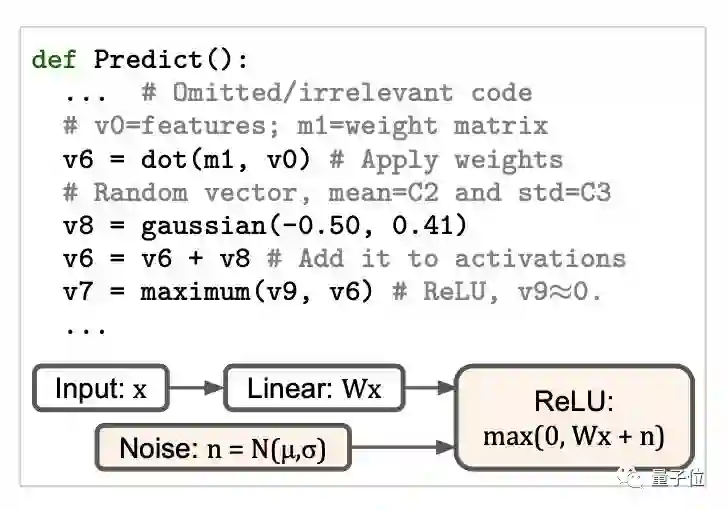
是一个我们在快速训练训练机器学习模型中常见的策略。
演示
git
clone https://github.com/google-research/google-research.git
cd google-research/automl_zero
./run_demo.sh
found:
def Setup():
s3 =
-0.520936
s2 = s2 * s3
s2 = dot(v1, v1)
v2 = s2 * v1
s2 = s3 * s2
v1 = s0 * v2
s2 = s0 - s3
s2 =
-0.390138
v2 = s2 * v0
s1 = dot(v1, v0)
def Predict():
s2 =
-0.178737
s1 = dot(v1, v0)
def Learn():
s1 = s1 * s2
s3 = s3 * s2
s2 = s0 * s2
s1 = s1 - s2
v2 = s1 * v0
v1 = v2 + v1
v2 = s3 * v0
v1 = v2 + v1
def Setup():
s2 =
0.001
# Init learning rate.
def Predict():
# v0 = features
s1 = dot(v0, v1)
# Apply weights
def Learn():
# v0 = features; s0 = label
s3 = s0 - s1
# Compute error.
s4 = s3 * s1
# Apply learning rate.
v2 = v0 * s4
# Compute gradient.
v1 = v1 + v2
# Update weights.
关于作者


传送门
https://arxiv.org/abs/2003.03384
https://github.com/google-research/google-research/tree/master/automl_zero


登录查看更多
相关内容
Arxiv
4+阅读 · 2018年1月29日




相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2018年1月29日