分享主题:DeepRec: 大规模稀疏模型训练/预测引擎
分享嘉宾:丁辰 阿里云计算平台事业部PAI 技术专家
出品平台:DataFunTalk
-
DeepRec 背景(我们为什么要做 DeepRec)
-
-
DeepRec 社区(最新发布的 2206 版本主要功能)
DeepRec 背景介绍
我们为什么需要稀疏模型引擎?TensorFlow 目前的社区版本是能够支持稀疏场景的,但是在以下三个方面存在一些功能上的短板:
因此我们提出了 DeepRec,其功能定位在稀疏场景做深度的优化。
![]()
DeepRec 所做的工作主要在四大方面:稀疏功能、训练性能、Serving、以及部署 & ODL。
![]()
DeepRec 在阿里巴巴内部的应用主要在推荐(猜你喜欢)、搜索(主搜)、广告(直通车和定向)等几个核心场景。我们也给云上的一些客户提供了部分稀疏场景的解决方法,为其模型效果和迭代效率的提升带来了很大帮助。
DeepRec 的功能主要分为以下五大方
面
:稀疏功能 Embedding,训练框架(异步、同步),Runtime(Executor、PRMalloc),图优化(结构化模型,SmartStage),serving 部署相关功能。
Embedding 部分将介绍以下 5 个子功能:
![]()
![]()
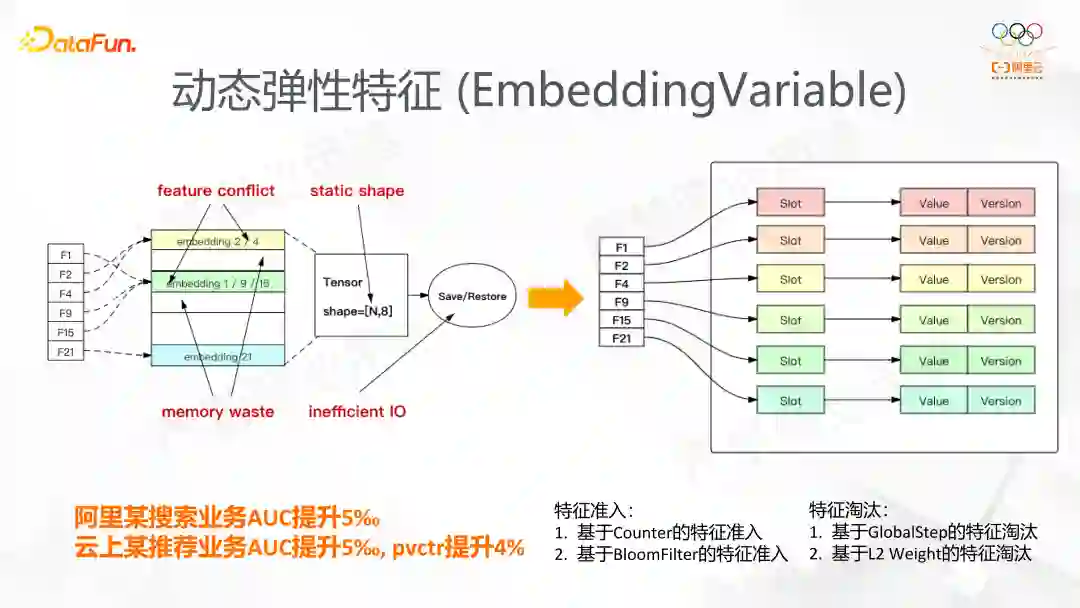
上图的左边是 TensorFlow 支持稀疏功能的主要方式。用户首先定义固定的 shape 的 Tensor,稀疏的特征通过 Hash+Mod 的方式 map 到刚刚定义的 Tensor 上。这个逻辑上有
4 个问题
:
-
稀疏特征的冲突,Hash+Mod 的方式容易引入特征冲突,这会导致有效特征的消失,进而影响效果。
-
存储部分会导致内存的浪费,有部分内存空间不会被使用到。
-
固定的 shape,一旦 Variable 的 shape 固定了,未来无法更改。
-
低效的 IO,假如用户用这种方式定义 Variable,必须通过全量的方式导出,如果 Variable 的维度很大,那么无论导出还是加载都是十分耗时的,但我们在稀疏的场景其实变化的部分是很少的。
在这种情况下,
DeepRec 定义的 EmbeddingVariable 设计的原理是
:
将静态的 Variable 转化为动态的类似 HashTable 的存储,每来一个 key,新创建一个 Embedding,这样就天然地解决了特征冲突的问题。
经过这样的设计,当特征特别的多的时候,EmbeddingVariable 无序的扩张,内存消耗也会变得很大,因此 DeepRec 引入了以下两个功能:特征准入和特征淘汰。它们都能有效的防止特征扩展到很大的维度。在搜索和推荐这样的稀疏场景,有些长尾特征被模型训练的次数十分少。因此特征准入能通过 CounterFilter 或者 BloomFilter 的方式对特征进入 EmbeddingVariable 设置一个门槛;在模型导出 Checkpoint 的时候也会有特征淘汰的功能,时间上比较老的特征也会被淘汰。这在阿里内部某个推荐业务 AUC 提升 5‰,在云上某推荐业务 AUC 提升 5‰,pvctr 也有提升 4%。
![]()
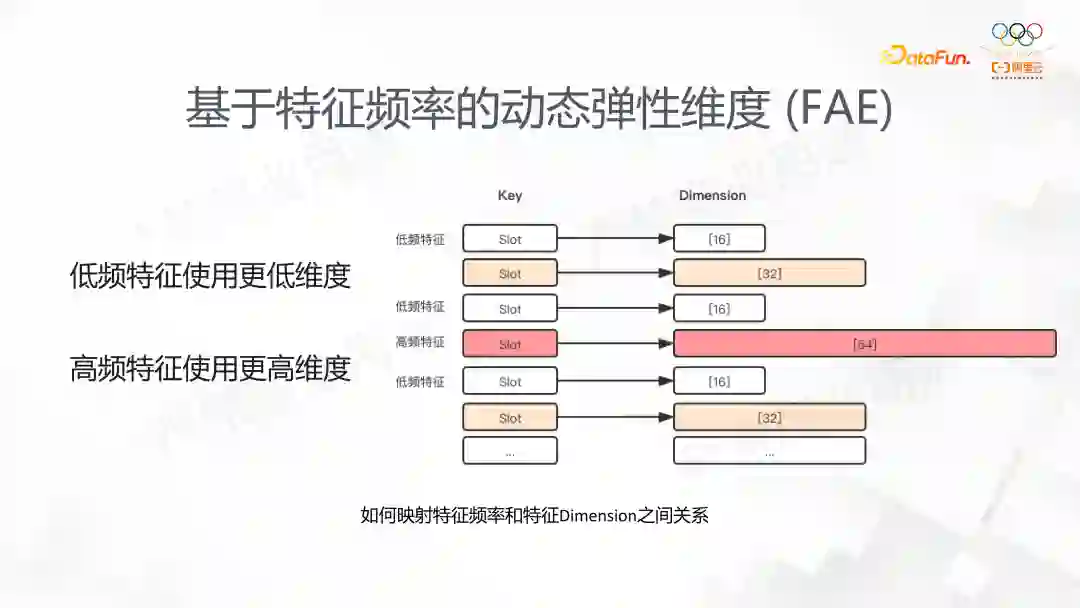
通常情况下同一个特征对应的 EmbeddingVariable 会被设置为同一个维度,如果 EmbeddingVariable 被设置一个较高的维度,低频的特征内容容易导致过拟合,并且会消耗大量的内存。相反的如果维度设置的过低,高频的特征内容则有可能因为表达的能力不足而影响模型的效果。FAE 的功能则提供了对于同一个特征里,根据不同特征冷热来配置不同的维度。这样让模型自动进行训练时第一个是模型的效果能得到保证,第二个也能解决训练对资源的使用。这是对于 FAE 功能的出发点的介绍。这个功能的使用目前是让用户传入一个维度和统计的算法,FAE 自动根据实现的算法来产生不同的 EmbeddingVariable;后面 DeepRec 计划在系统内部自适应的发现去分配特征的维度,从而提高用户的易用性。
![]()
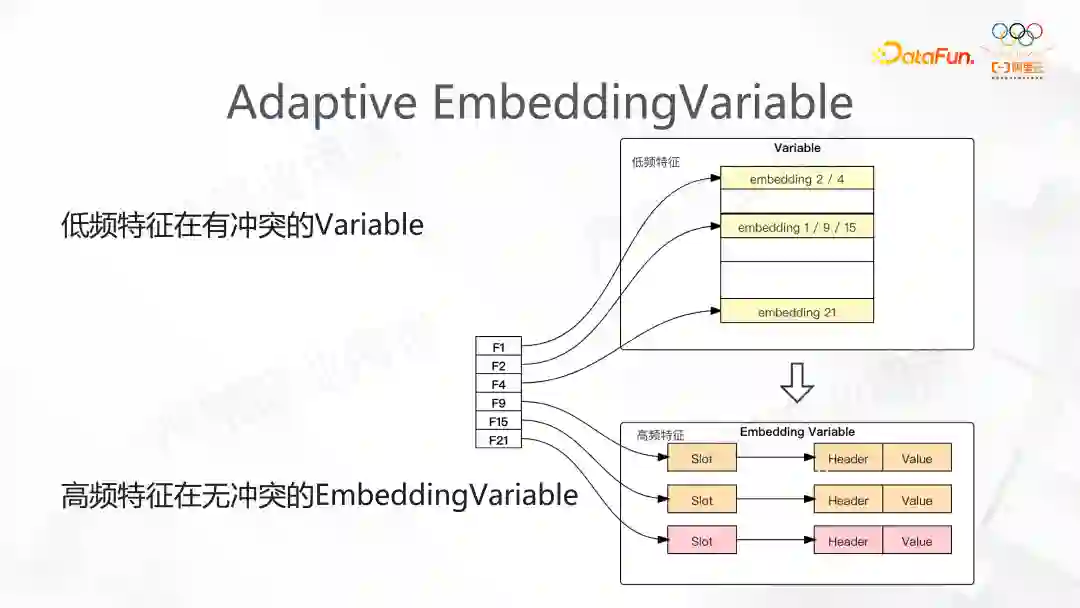
这个功能和第二个功能有些类似,都是以定义高低频的关系作为出发点。当前面提到的 EV 特别大时,我们会看到内存占用特别高。在 Adaptive Embedding Variable 中我们用两个 Variable 来表达,如右图展示。我们会定义其中一个 Variable 为静态的,低频的特征会尽可能映射到这个 Variable上;另外一个则定义为动态弹性维度特征,用于高频部分的特征。Variable 的内部支持低频和高频特征动态的转换,这样的优点是极大降低了系统对内存的使用。例如某个特征训练后第一维可能有接近 10 亿,而重要的特征只有 20%-30%,通过这种自适应的方式后,可以不需要那么大的维度,进而极大的降低了对内存的使用。我们在实际应用发现对模型的精度影响是很小的。
![]()
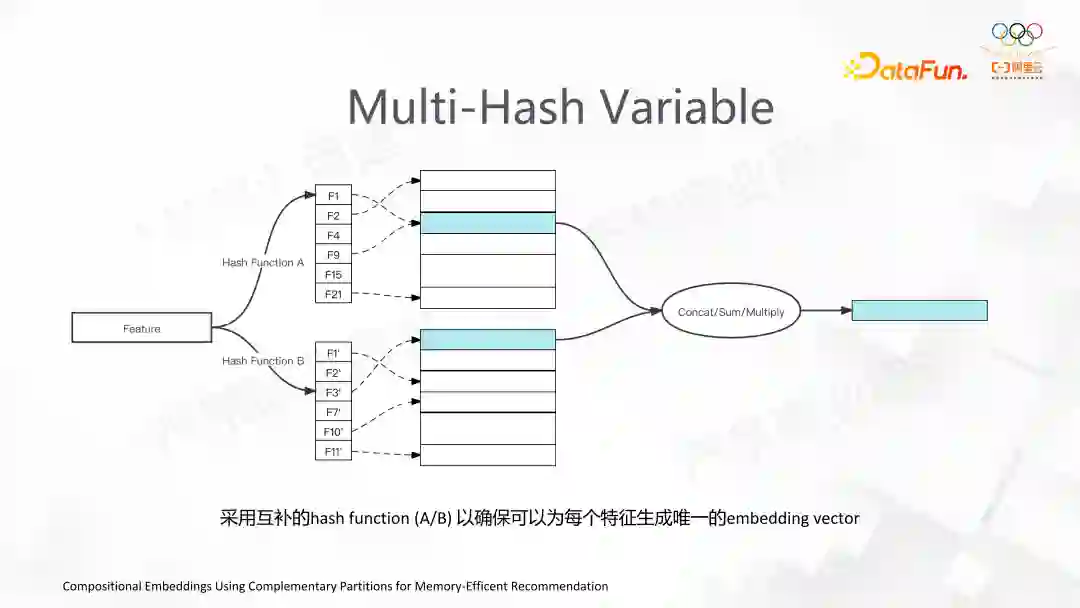
这个功能是为了解决特征冲突的问题。我们原来是通过一个 Hash+Mod的方式解决特征冲突,现在用两个或多个 Hash+Mod 去得到 Embedding,并且随后对得到的 Embedding 做 Reduction,这样的好处是能用更少的内存来解决特征冲突的问题。
![]()
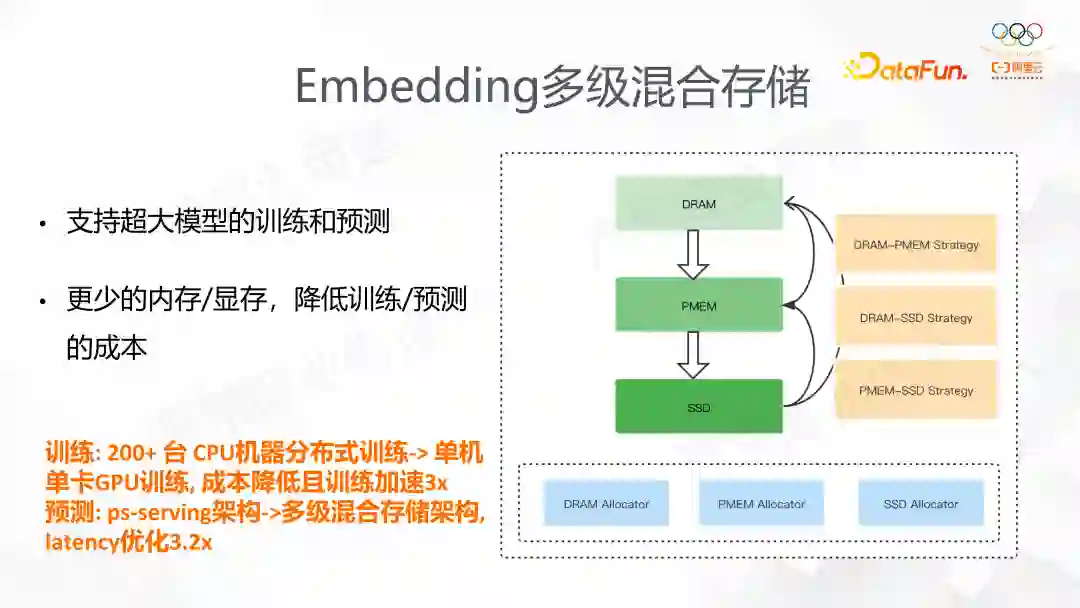
这一功能的出发点同样也是发现EV在特征个数多的时候,内存开销十分大,训练的时候 worker 占用的内存可能达到了几十上百G。我们发现,特征实际上遵循典型的幂律分布。考虑到这个特征点,我们将热点特征放到 CPU 这样更宝贵的资源,而相对长尾低频的特征则放到相对廉价的资源中。如右图,有 DRAM、PMEM、SSD 三种结构,PMEM 是英特尔提供的速度介于 DRAM 和 SSD 之间,但容量很大。我们目前支持 DRAM-PMEM、DRAM-SSD、PMEM-SSD 的混合,也在业务上取得了效果。云上有个业务原来用 200+ 多 CPU 分布式训练,现在使用多级存储后改成了单机 GPU 训练。
![]()
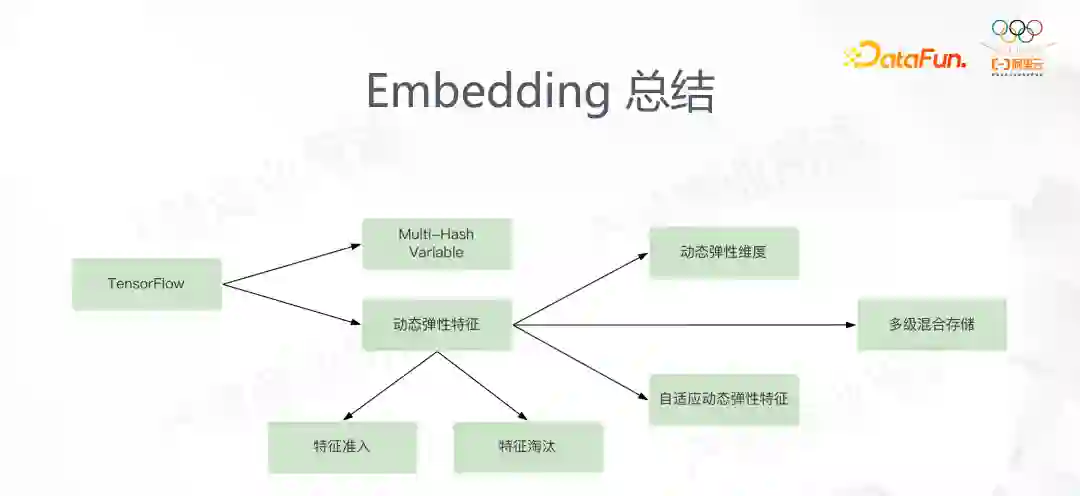
以上是对 Embedding 所有功能的介绍。我们做这些功能的动机是由于TensorFlow 的几个问题(主要是特征冲突),我们解决的方案是动态弹性特征和 Multi-Hash 特征,针对动态弹性特征内存开销较大的问题,我们又开发了特征准入和特征淘汰的功能;针对特征频次,我们开发了 3 组功能:动态弹性维度和自适应动态弹性特征是从维度的方向解决的问题,多级混合存储则是从软硬件的方向解决的问题。
第二个要介绍的功能是训练框架,分为异步和同步两个方向来介绍。
![]()
![]()
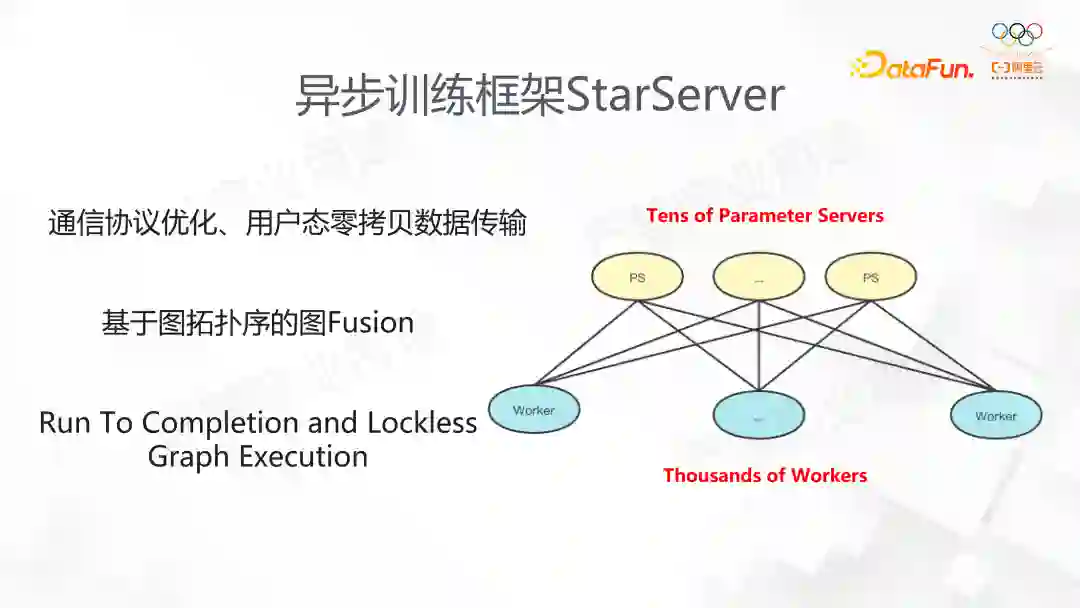
在超大规模任务情况下,上千个 worker,原生 TensorFlow 存在的问题是:线程调度十分低效,关键路径开销凸显,另外小包通信十分频繁,这些都成为了分布式通信的瓶颈。
StarServer 在图的线程调度、内存的优化方面做得很好,将框架中Send/Recv 修改为了 Push/Pull 语义,PS 在执行的时候使用了 lockless 的方法,极大地提高了执行的效率。我们对比原生框架有数倍的性能提升,并且在内部 3Kworker 左右的数量能达到线性的扩展。
![]()
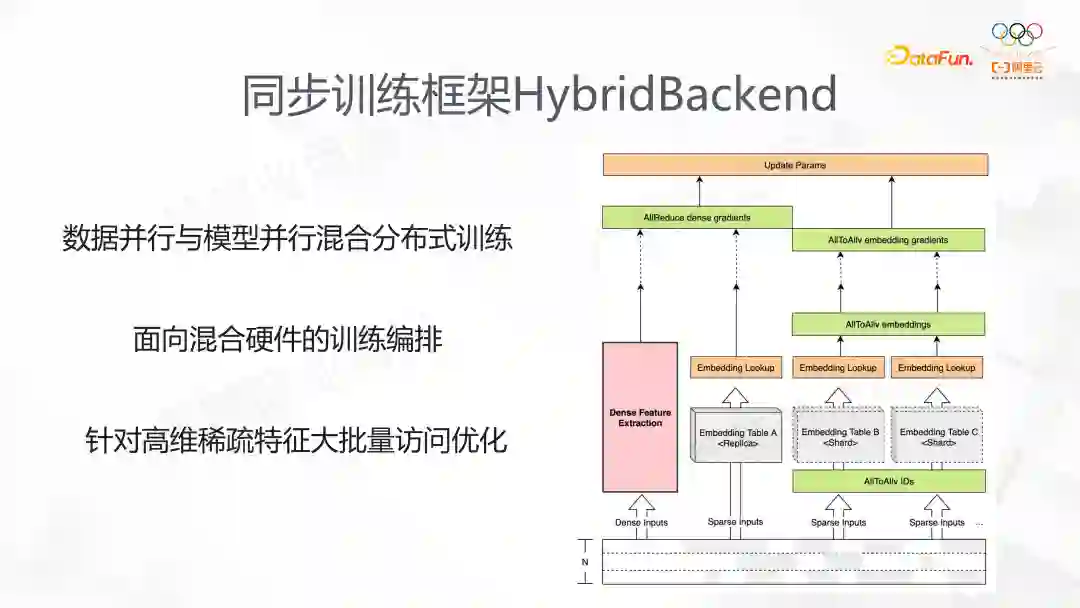
这是我们为同步训练开发的方案,它支持数据并行和模型并行混合分布式训练。数据读取通过数据并行来完成,模型并行能支持大参数量训练,最后使用数据并行做稠密计算。我们针对不同 EmbeddingLookup 的特征,做了多路 Lookup 合并的优化,分组优化,还利用了 GPU Direct RDMA 的优点,基于网络拓扑的感知,设计整个同步的框架。
第三个大方面的功能是 Runtime,主要介绍 PRMalloc 和 Executor 优化。
![]()
![]()
首先是内存分配,内存分配在 TensorFlow 和 DeepRec 中都是无处不在的,我们首先在稀疏训练中发现,大块内存分配造成了大量的 minorpagefault,此外在多线程的分配中也存在并发分配的问题。
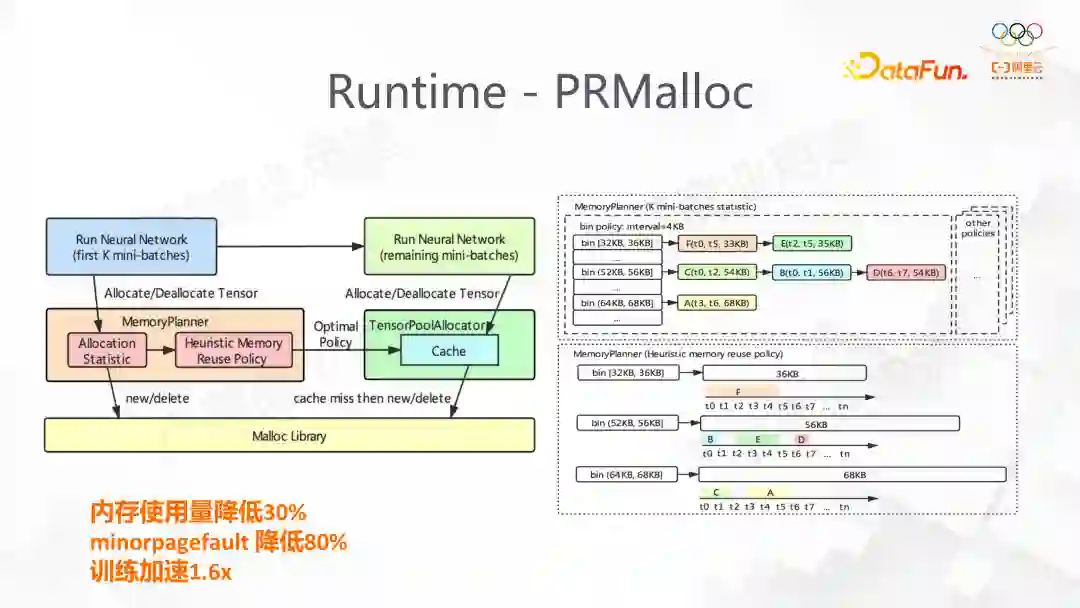
我们在 DeepRec 中针对稀疏训练前向反向的特点,设计了针对深度学习的内存分配方案,称为 PRMalloc
。它提高了内存使用率和系统的性能。在图中可以看到主要的一块是 MemoryPlanner,它的作用是在模型训练的前 k 轮的 minibatch 先统计当前训练的特点,每次需要分配多少 Tensor,将这些行为记录通过 bin 的 buffer 记录下来,并且做相应的优化。在k步后,我们将其应用,从而极大减少上述的问题。我们在 DeepRec 的使用中发现,这能大大减少 minorpagefault 的出现,减少了内存的使用,训练速度也得到了 1.6 倍的加速。
![]()
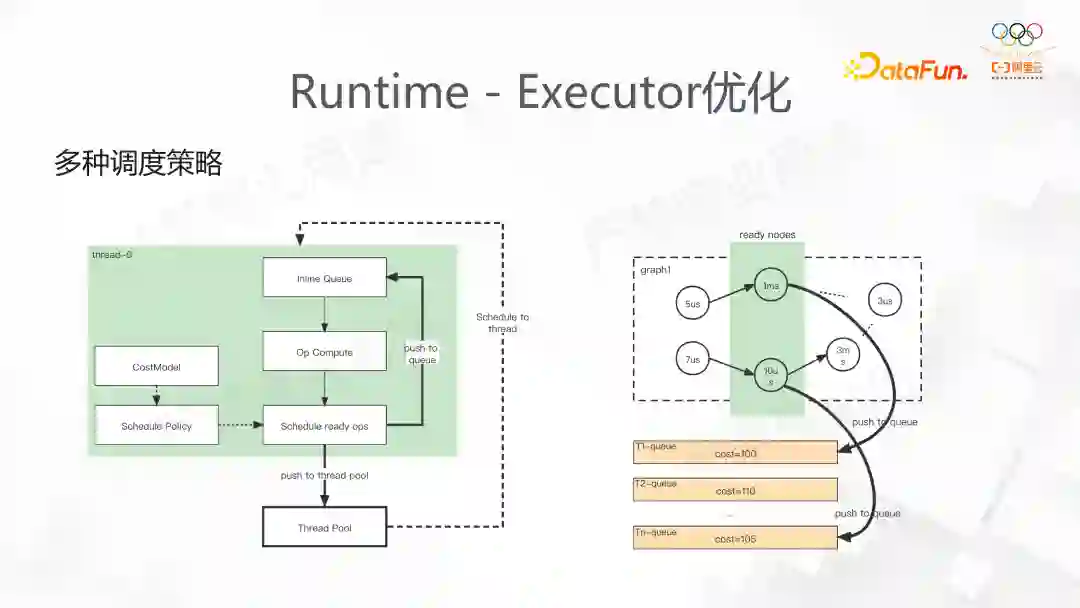
TensorFlow 原生的 Executor 的实现十分简单,首先对 DAG 做拓扑排序,随后将 Node 插入到执行队列中,通过 Task 利用 Executor 调度。这样的实现没有结合业务考虑,ThreadPool 默认使用了Eigen线程池,若线程负载不均匀,会发生大量的线程间抢占 Steal,带来极大开销。我们在 DeepRec 中定义调度更均匀,同时定义了关键路径使得在调度的时候有一定的优先级顺序,来执行 Op。最终 DeepRec 也提供了多种包括基于 Task,SimpleGraph 的调度策略。
![]()
![]()
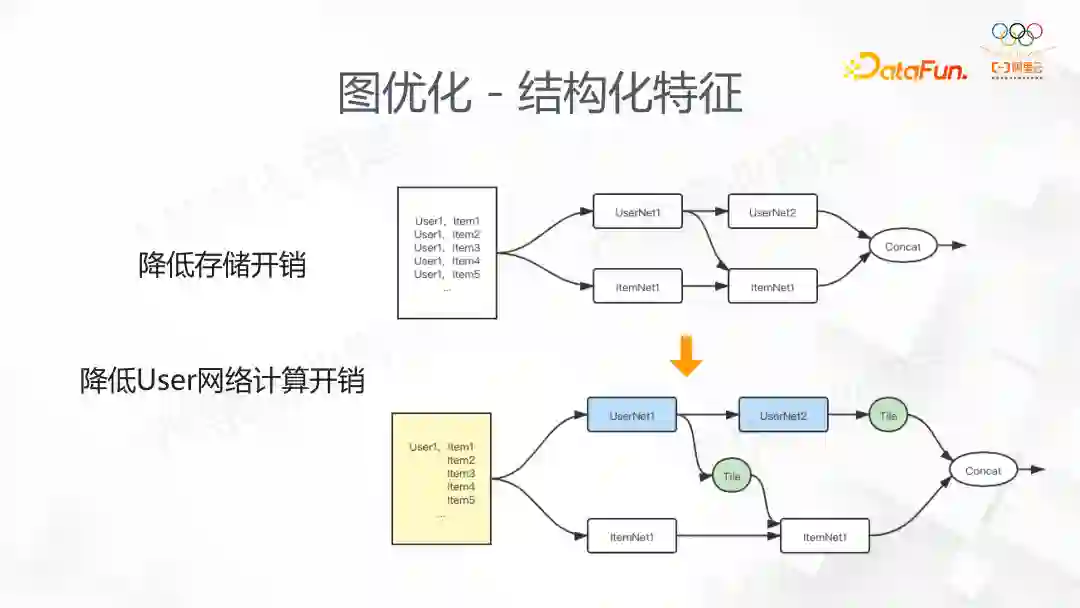
这是从业务启发的一个功能。我们发现在搜索场景下,不管是训练还是推理,样本往往是 1 个 user 对应多个 item,多个 label 的特点。原来的处理方式会视为多个样本,这样 user 的存储是冗余的,我们为了节省这部分开销,自定义了存储格式来做这部分优化。如果这些样本在一个 minibatch 中是同一个 user,部分 user 网络和 item 网络会分别计算,最后在做相应的逻辑计算,这样能节省计算开销。所以我们分别从存储和计算端做了结构化的优化。
![]()
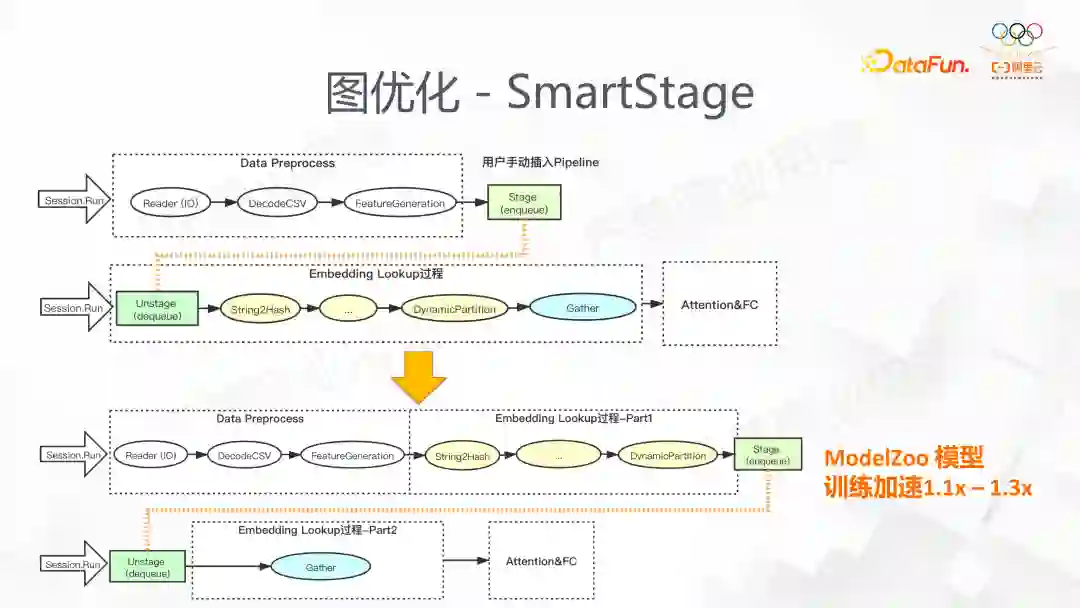
我们看到稀疏模型的训练通常包括样本的读取,EmbeddingLookup,还有MLP 的网络计算。样本的读取和 Embedding 查找往往不是计算密集型的,并不能有效利用计算资源。原生框架提供的 prefetch 接口虽然能一定程度上完成异步操作,但是我们在 EmbeddingLookup 过程中设计部分复杂的子图,这些不能通过 TensorFlow 的 prefetch 实现流水线。TensorFlow 提供的流水线功能,实际使用中需要用户显示的指定 stage 边界,一方面会提高使用难度,另一方面由于 stage 的精度不够,无法精确到 op 级别。对于 High Level 的 API 用户无法手动插入,会导致很多步伐并行化。下图是 SmartStage 的具体操作,它会将 Op 自动的归类到不同的 Stage,使得并发的流水线能得到性能的提升。我们在 ModelZoo 里模型的测试效果最大加速比能达到 1.1-1.3。
![]()
![]()
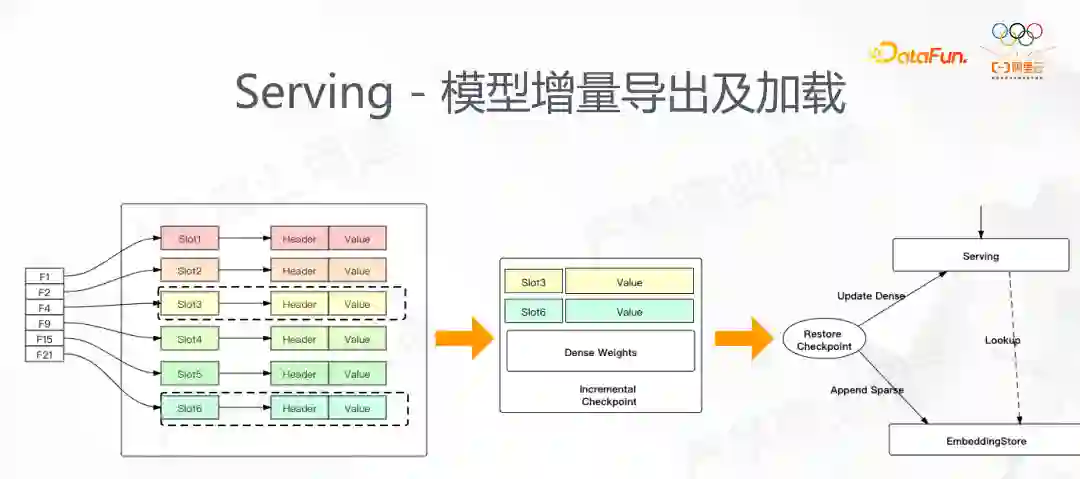
一开始在介绍 Embedding 的时候其中一个重要的点是低效的 IO,如果将前面提到动态弹性功能应用后,我们天然能做增量的导出。只要在图中加入曾经访问的稀疏 ID,那么在增量导出的时候就能准确的导出这部分我们需要的 ID。我们做这个功能有两个出发点:首先,模型训练时我们原有的方法,在每个 step 导出全量的模型导出,在程序中断 restore 时候也是 restore checkpoint,最差的时候可能损失两个 checkpoint 区间所有的结果,有了增量导出,我们对于 dense 部分会全量导出,sparse 部分是增量导出,这在实际场景 10 分钟的增量导出能很大程度节约 restore带来的损失;另外,增量导出的场景是在线 serving,如果每次都全量加载,那么对于稀疏场景,模型十分大,每次加载都需要耗费很长时间,如果要做在线学习会很困难,所以增量导出也会用到 ODL 场景。
![]()
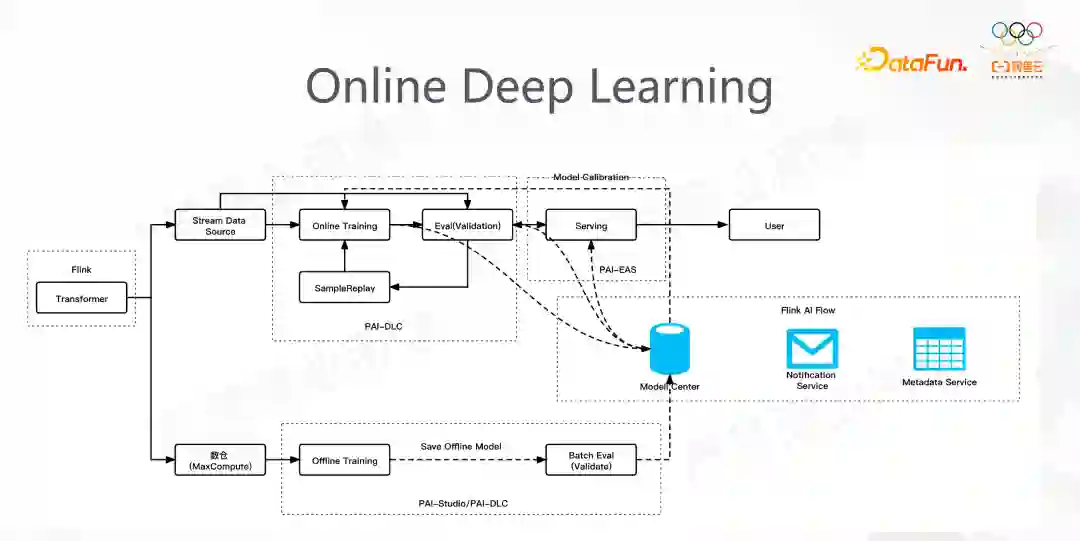
最左边是样本处理,上下两部分是离线和在线的训练,右边是 serving。这里面应用了很多 PAI 的组件来完成 Pipeline 的构造。
社区方面,我们在 6 月份发布了新版本 2206,主要包括以下新功能:
![]()
![]()
本文PPT下载👇
![]()
01/分享嘉宾
北京邮电大学硕士。在阿里云工作7年,先后在 MaxCompute、PAI 团队工作,负责 PAI-Tensorflow 框架相关工作,开源项目 DeepRec、TFRA maintainer。工作内容:大规模稀疏模型训练/推理框架功能开发、图执行优化、稀疏功能。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
专知,专业可信的人工智能知识分发
,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取100000+AI(AI与军事、医药、公安等)主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询!
点击“
阅读原文
”,了解使用
专知
,查看获取100000+AI主题知识资料