语义分割新范式!StructToken:对per-pixel 分类范式的重新思考

极市导读
本文为上海AI lab、北邮和商汤提出的一种新的语义分割范式StructToken,选择使用结构信息作为先验直接构造语义掩码然后逐步细化,而不再是按照per-pixel分类的范式。>>加入极市CV技术交流群,走在计算机视觉的最前沿

论文链接:https://arxiv.org/abs/2203.12612
本文是对语义分割传统编解码逐像素分类范式的一种思考和改进。
之前语义分割的工作将其视作一种逐像素分类任务,主流范式是编解码结构,通过编码器和解码器学习逐像素表征后,通过对每个像素单独分类到不同的类别中从而获得预测的语义掩码结果。这篇文章选择了另一种策略,即将结构信息作为先验直接构造语义掩码然后逐步细化,而不再是按照逐像素分类的范式。
具体来看,对于给定的输入图像,模型中可学习的结构token会和图像表征进行交互,从而推理出最终的语义掩码。这一思路和最初的ViT结构中的cls token的行为颇为类似。考虑到这份工作的实现是基于ViT-L,所以可以很直观的推想出,StructToken的思路其实是将Transformer原本的形式向语义分割这样的密集预测任务的一种“直接”迁移,这其中并没有像其他工作那样,过多受到目标任务中原始的卷积神经网络设计范式的影响。
所以值得思考的几点可以由此提出:
-
本文定义的结构信息是什么? -
提出的设计是怎样表达出这些结构信息的? -
如何验证这些设计带来的提升与所谓的结构信息有关?
相关工作
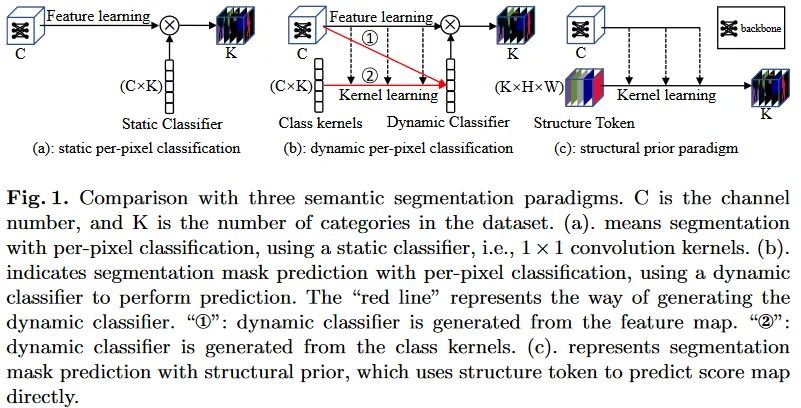
现有的语义分割领域已经出现了大量的工作,但是目前出现的工作中基本上都可以被归类为逐像素分类范式,差别主要在于分类参数是否是动态的:
-
静态逐像素分类:延续着以分割领域早期基于卷积神经网络的经典工作的范式,例如FCN。他们主要利用上下文语义信息的增强和多尺度特征的融合,从而获得更有效的图像特征表示。并利用独立的静态分类器(典型如1x1卷积)实现逐像素的语义类别预测。然而这类工作专注于提升逐像素特征的表达能力,却并未在模型设计中考虑图像中的结构信息。 -
动态逐像素分类:最近的工作中开始引入动态结构的思想。除了模型本身特征处理结构之外,分类器也开始转变为动态形式。论文列出的典型的工作有Segmenter[ Segmenter: Transformer for semantic segmentation]、MaskFormer[ Per-pixel classification is not all you need for semantic segmentation]、Mask2Former[ Masked-attention mask transformer for universal image segmentation]和K-Net[ K-Net: Towards unified image segmentation]。他们主要是使用了一系列与语义类别相关的可学习的token,与图像自身的特征进行交互,从而实现最终mask的预测。这从形式上来看,可以认为是一种动态分类的过程。这些方法同时由没有完全抛弃上面提到的经典范式,整体上获得了更好的表现。但是从本文的角度来看,这类方法仍然没有抛开逐像素分类的范式:)。
这些工作从整体上来看, 都是在学习针对每一类的线性判别函数,要么是静态的卷积,要么动态的矩阵乘法运算。这会作用在逐像素的特征表示上,从而来为其赋予一个最相关的语义类别。
作者们认为,按照人识别物体的过程,先是捕获语义类别的结构信息(形状等),然后关注于内部细节。想要分割图像中不同语义类别的区域,通常先根据结构生成一个粗略的mask,之后在调整mask的细节。现有的两种逐像素分类范式并没有充分的体现这一过程,而更多的是,直接在模型倒数第二层的特征图上分类像素从而获得得分图。这一特性鼓励网络优化单一像素的表征,而忽略甚至破坏了最重要的结构特征。
本文中作者们提出了一种结构先验范式来解决这一问题,直接从结构token中构造得分图来分割图像,然后逐渐细化。
主要内容
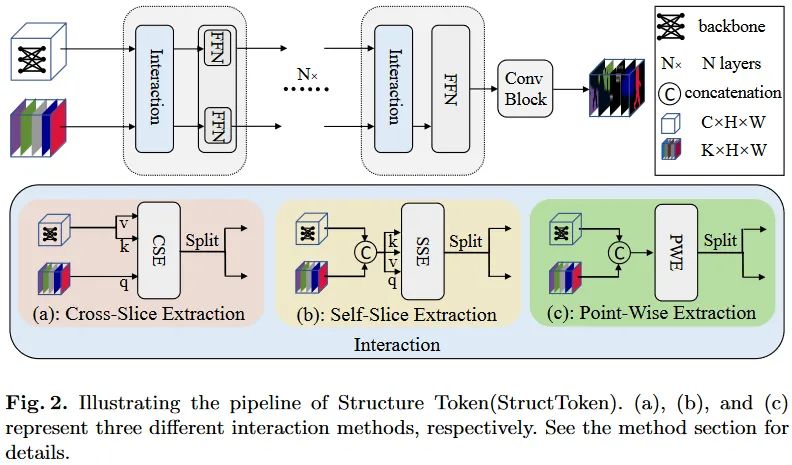
文中主要研究了如何从特征图中根据结构token提取有用的信息。提出的结构整体遵循这样的过程:
-
提取特征:使用Transformer骨干网络,例如ViT,提取特征图F,大小为[C,H/16,W/16]。 -
构造结构token:随机初始化可学习的结构token S,大小为[K,N],K为数据集类别数量,N为patch数量,即[H/16,W/16]。 -
信息交互:使用交互结构来处理S。捕获特征图中的结构信息,并根据学习到的先验为每一类构建粗略的mask。 -
特征细化:独立的FFN用于结构token的细化,并处理特征图。 -
级联处理:堆叠多个基础单元(包括交互和细化)来重复处理特征。 -
预测结果:尾部使用两个卷积层和跳过链接构成的卷积块来细化最终构建的分割mask并得到最终的结果。
这些步骤中,交互式结构的设计是本文的核心。文中主要探索了三种交互式结构。其中包含两种动态结构和一种静态结构。
-
动态结构:基于Attention的思路,但是计算相关的token并非是空间patch,而是基于通道,即S中的类别token和F中的特征通道之间的交互。 -
第一种CSE基于Cross-Attention范式,经过线性变换,S生成Query,F生成Key和Value,送入Cross-Attention。这里得到的结果与S形状一致。按照图示,这里也有个拆分操作,但是论文并未明说具体如何实现。 -
第二种SSE基于Self-Attention范式,S和F沿通道拼接后经过线性变换得到Query、Key和Value,并送入Self-Attention。结果会被按照通道的原始比例进行拆分。 -
静态结构:直接使用1x1卷积处理SSE模块中的相似性注意力的计算。卷积结果即为最终对应于拆分之前的结果。这一过程使用1x1卷积直接混合不同的输入通道的信息,实现了类似于SSE的过程。
上面结构中在执行Attention操作之前,S和F会被送入投影层处理,虽然是针对通道的Attention处理,但是这里的投影层使用的是1x1卷积+3x3深度卷积+1x1卷积的形式,仍然是空间维度共享的操作。
这些模块的两个输出都会各自接一个FFN。这里的FFN使用的是FC+3x3分组卷积+FC的结构。即可以细化局部特征,也可以看作是一种隐式位置编码。
实验结果
对比实验
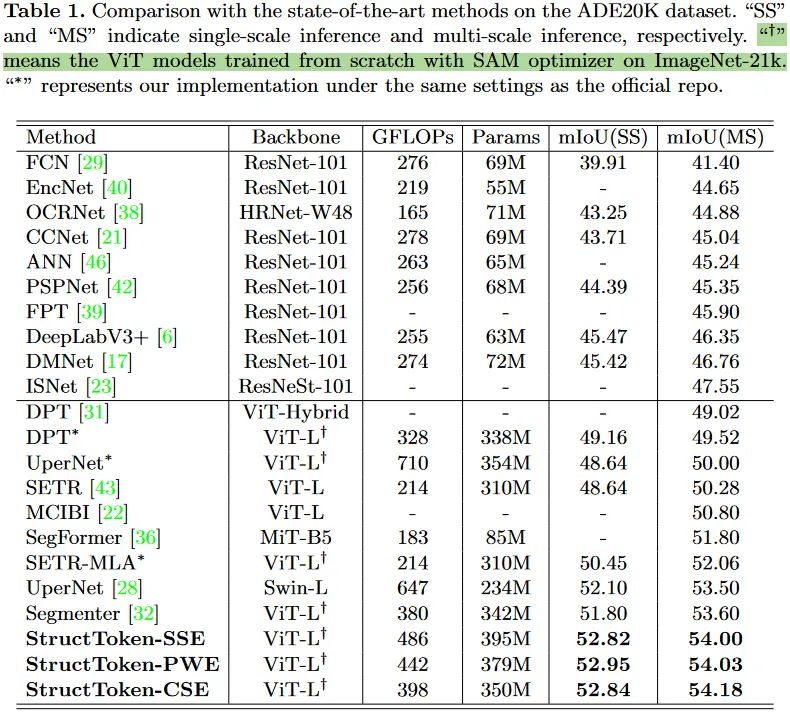
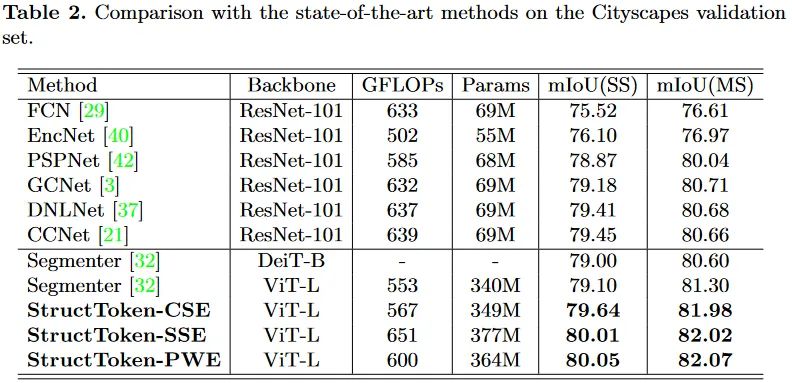
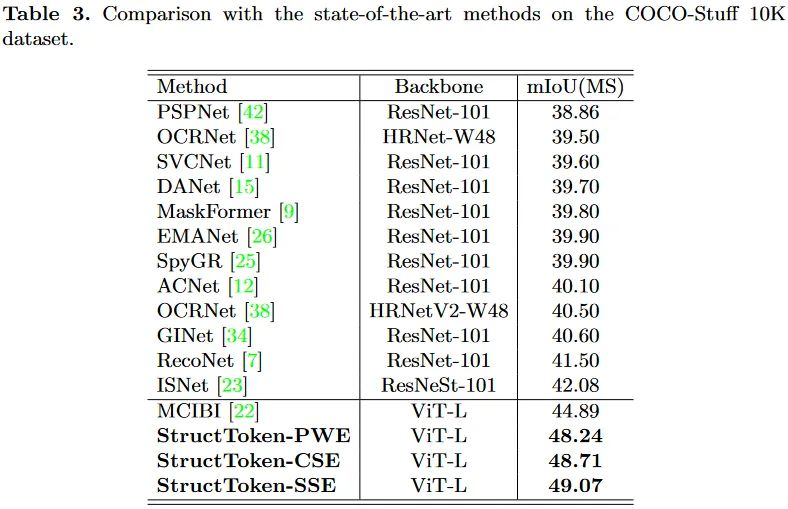
文中在三个主要的语义分割数据集上进行了验证。本文的方法是构建在ViT的不同变体之上的,也因此没有使用那些金字塔架构形式的多尺度特征。
从这里的实验中可以发现一个趋势,语义分割方法使用的backbone越来越大,从早期的的Res101,到现在的ViT-L、MiT-B5、Swin-L。预训练权重甚至都开始使用ImageNet21K上的了。不知道这样的潮流是否真的有意义。
消融实验
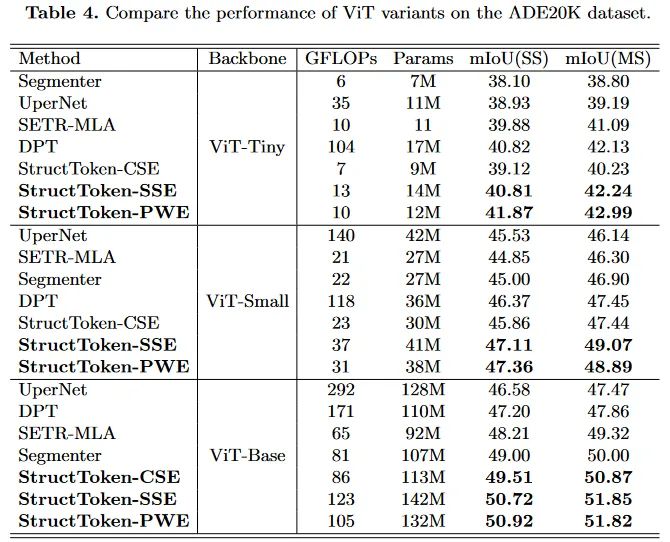
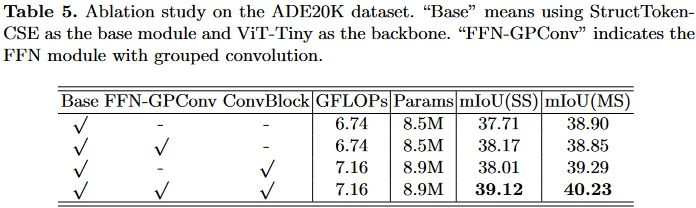
对提出的结构中的不同组件进行了消融实验。这里的baseline模型基于ViT,仅隔着一个CSE模块和FFN模块。这里的FFN没有使用分组卷积,另外这里不对Query、Key和Value的投影层进行消融实验,因为作者们觉得如果替换成常规的全连接成,会导致无法支持多尺度推理。因为为了保持attention操作本身的原始性,仅对输入转置来实现通道attention而非手动修改投影层的情况下,此时的投影层就成了空间上的全连接了。
这里还对提出的解码块堆叠数量进行了实验,最终作者们考虑性能与计算复杂度的平衡,就选择了4。实际上实验中反映出来,更多的块会带来更好的性能表现。
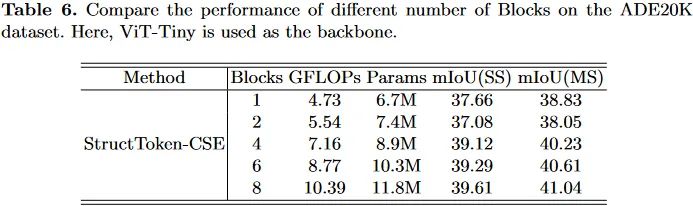
但是作者们并没有讨论这些伴随而来的计算量和参数量对于性能的影响。
为了验证提出的结构token保留结构信息的能力,作者们构建了一个逐像素分类范式的对等参考,backbone提取的特征会先将通道数量调整到类别数(类似于本文提出的结构token那样),每个通道认为对应一个类别。之后通过四个残差块来进行处理,最终使用1x1卷积生成最终的得分图。来自每个残差块的输出会被用来与本文模型中每个交互块的结构token输出进行可视化对比。下图中,不同的行组对应着不同的类别。可以看到,尽管输出的得分图很类似,但是结构token在中间的输出却展现出了更清晰的目标形状、轮廓等结构信息。而且随着多个块的处理,这些目标信息更加清晰(典型如第9行)。
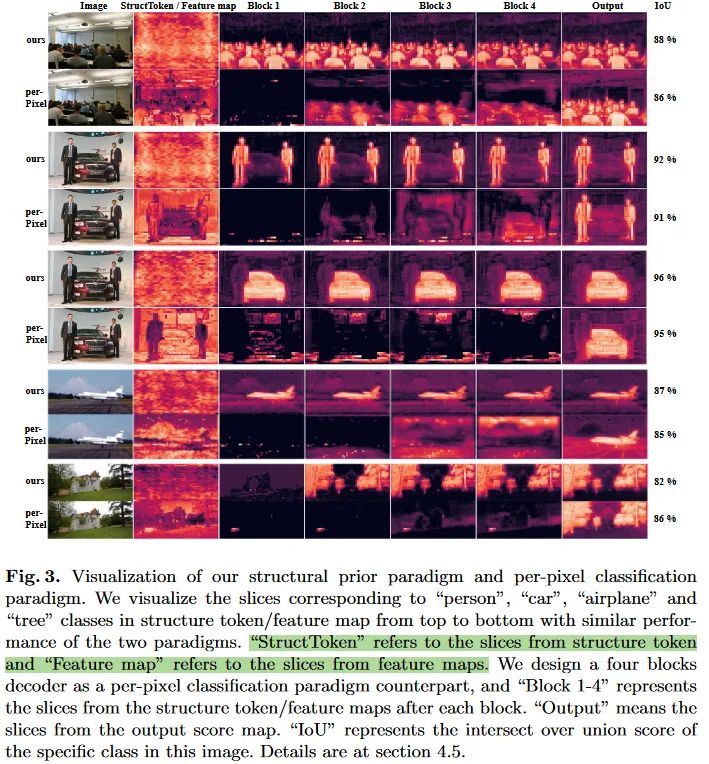
总结与思考
回答开头的问题:
-
本文定义的结构信息是什么?文章反复在强调的结构其实直观上可以理解为反映目标信息的形状和外观。本文提出的结构Token在多次堆叠的处理单元的输出中都明显的凸显出了特定类别的目标,确实实现了“粗略预测”的效果。
-
提出的设计是怎样表达出这些结构信息的?基于通道的交互方式,使得结构token可以对图像特征不同的通道进行自适应的组合与强化。双流中各自的FFN实现了独立的空间变换和通道整合,这保证了各自学习过程的差异性和多样性。这种交互方式保留了图像空间结构信息的独立性和完整性。同时由于真值的监督,目标类别对应的结构token经过优化,会愈发具有与真值接近的空间上的外观,也即论文中图3中所展示的那样。
-
这是为什么呢?我觉得这是因为通道注意力的使用的结果。基于通道之间的相似性计算的attention运算中,会为图像特征中对应空间位置激活更加明显(即与结构token对应类别通道更加相似)的通道赋予更大的比重,这样才会让损失越来越小。 -
如何验证这些设计带来的提升与所谓的结构信息有关?作者对此并未进行探讨,或许可以构造这样一个实验:在目前这种在最后单一监督的形式中,后续处理单元中结构token各个类别通道的可视化结果非常趋于真值了。那若是使用深监督策略,直接对论文中提供的逐像素分类范式的卷积模型,对这些位置的特征进行额外监督,进一步强化这些特征对于这些目标区域的分割效果。如果性能进一步提升,则说明这样的结构信息的强化是有必要的。
公众号后台回复“CVPR 2022”获取论文合集打包下载~

# 极市平台签约作者#

Lart
知乎:人民艺术家
CSDN:有为少年
大连理工大学在读博士
研究领域:主要方向为图像分割,但多从事于二值图像分割的研究。也会关注其他领域,例如分类和检测等方向的发展。
作品精选



