深度学习物体检测论文阅读路线图以及官方实现代码
极市平台是专业的视觉算法开发和分发平台,加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者:hoya012
编译:ronghuaiyang
来源:AI公园
物体检测是CV领域非常重要的场景,自从2012年深度学习开始发威以来,物体检测也不例外的屈服于深度学习的淫威之下,特别是RCNN以来,物体检测进展飞速,各种网络,各种loss,各种trick,层出不穷,perfermance也是一路飙升,今天在github上找到一个repo,整理了2014到目前为止的物体检测的论文列表,还有对应的官方代码哦。好了,废话少说,让我们进入正题。
github地址:
https://github.com/hoya012/deep_learning_object_detection
使用深度学习的物体检测论文列表,参考了这篇文章:
https://arxiv.org/pdf/1809.02165v1.pdf。
最近更新: 2018/12/07
从2014年到现在(2018年)的论文列表
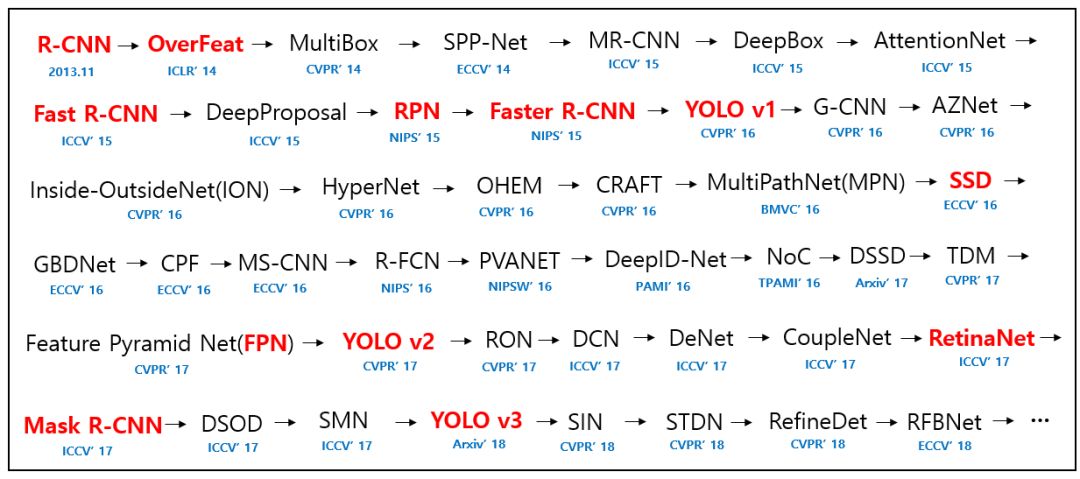
performance 表
| Detector | VOC07 (mAP@IoU=0.5) | VOC12 (mAP@IoU=0.5) | COCO (mAP) | Published In |
|---|---|---|---|---|
| R-CNN | 58.5 | - | - | CVPR'14 |
| OverFeat | - | - | - | ICLR'14 |
| MultiBox | 29.0 | - | - | CVPR'14 |
| SPP-Net | 59.2 | - | - | ECCV'14 |
| MR-CNN | 78.2 (07+12) | 73.9 (07+12) | - | ICCV'15 |
| AttentionNet | - | - | - | ICCV'15 |
| Fast R-CNN | 70.0 (07+12) | 68.4 (07++12) | - | ICCV'15 |
| Faster R-CNN | 73.2 (07+12) | 70.4 (07++12) | - | NIPS'15 |
| YOLO v1 | 66.4 (07+12) | 57.9 (07++12) | - | CVPR'16 |
| G-CNN | 66.8 | 66.4 (07+12) | - | CVPR'16 |
| AZNet | 70.4 | - | 22.3 | CVPR'16 |
| ION | 80.1 | 77.9 | 33.1 | CVPR'16 |
| HyperNet | 76.3 (07+12) | 71.4 (07++12) | - | CVPR'16 |
| OHEM | 78.9 (07+12) | 76.3 (07++12) | 22.4 | CVPR'16 |
| MPN | - | - | 33.2 | BMVC'16 |
| SSD | 76.8 (07+12) | 74.9 (07++12) | - | ECCV'16 |
| GBDNet | 77.2 (07+12) | - | 27.0 | ECCV'16 |
| CPF | 76.4 (07+12) | 72.6 (07++12) | - | ECCV'16 |
| MS-CNN | - | - | - | ECCV'16 |
| R-FCN | 79.5 (07+12) | 77.6 (07++12) | 29.9 | NIPS'16 |
| PVANET | - | - | - | NIPSW'16 |
| DeepID-Net | 69.0 | - | - | PAMI'16 |
| NoC | 71.6 (07+12) | 68.8 (07+12) | 27.2 | TPAMI'16 |
| DSSD | 81.5 (07+12) | 80.0 (07++12) | - | arXiv'17 |
| TDM | - | - | 37.3 | CVPR'17 |
| FPN | - | - | 36.2 | CVPR'17 |
| YOLO v2 | 78.6 (07+12) | 73.4 (07++12) | - | CVPR'17 |
| RON | 77.6 (07+12) | 75.4 (07++12) | - | CVPR'17 |
| DCN | - | - | - | ICCV'17 |
| DeNet | 77.1 (07+12) | 73.9 (07++12) | 33.8 | ICCV'17 |
| CoupleNet | 82.7 (07+12) | 80.4 (07++12) | 34.4 | ICCV'17 |
| RetinaNet | - | - | 39.1 | ICCV'17 |
| Mask R-CNN | - | - | - | ICCV'17 |
| DSOD | 77.7 (07+12) | 76.3 (07++12) | - | ICCV'17 |
| SMN | 70.0 | - | - | ICCV'17 |
| YOLO v3 | - | - | 33.0 | Arxiv'18 |
| SIN | 76.0 (07+12) | 73.1 (07++12) | 23.2 | CVPR'18 |
| STDN | 80.9 (07+12) | - | - | CVPR'18 |
| RefineDet | 83.8 (07+12) | 83.5 (07++12) | 41.8 | CVPR'18 |
| MegDet | - | - | - | CVPR'18 |
| RFBNet | 82.2 (07+12) | - | - | ECCV'18 |
2014年的论文
[R-CNN] Rich feature hierarchies for accurate object detection and semantic segmentation | Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik | [CVPR' 14] |[
[pdf\]](https://arxiv.org/pdf/1311.2524.pdf) [[official code - caffe\]](https://github.com/rbgirshick/rcnn)[OverFeat] OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks | Pierre Sermanet, et al. | [ICLR' 14] |[
[pdf\]](https://arxiv.org/pdf/1312.6229.pdf) [[official code - torch\]](https://github.com/sermanet/OverFeat)[MultiBox] Scalable Object Detection using Deep Neural Networks | Dumitru Erhan, et al. | [CVPR' 14] |[
[pdf\]](https://www.cv-foundation.org/openaccess/content_cvpr_2014/papers/Erhan_Scalable_Object_Detection_2014_CVPR_paper.pdf)[SPP-Net] Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition | Kaiming He, et al. | [ECCV' 14]|[
[pdf\]](https://arxiv.org/pdf/1406.4729.pdf) [[official code - caffe\]](https://github.com/ShaoqingRen/SPP_net) [[unofficial code - keras\]](https://github.com/yhenon/keras-spp) [[unofficial code - tensorflow\]](https://github.com/peace195/sppnet)
2015年的论文
[MR-CNN] Object detection via a multi-region & semantic segmentation-aware CNN model | Spyros Gidaris, Nikos Komodakis | [ICCV' 15] |[
[pdf\]](https://www.cv-foundation.org/openaccess/content_iccv_2015/papers/Gidaris_Object_Detection_via_ICCV_2015_paper.pdf) [[official code - caffe\]](https://github.com/gidariss/mrcnn-object-detection)[DeepBox] DeepBox: Learning Objectness with Convolutional Networks | Weicheng Kuo, Bharath Hariharan, Jitendra Malik | [ICCV' 15] |[
[pdf\]](https://arxiv.org/pdf/1505.02146.pdf) [[official code - caffe\]](https://github.com/weichengkuo/DeepBox)[AttentionNet] AttentionNet: Aggregating Weak Directions for Accurate Object Detection | Donggeun Yoo, et al. | [ICCV' 15] |[
[pdf\]](https://arxiv.org/pdf/1506.07704.pdf)[Fast R-CNN] Fast R-CNN | Ross Girshick | [ICCV' 15] |[
[pdf\]](https://arxiv.org/pdf/1504.08083.pdf) [[official code - caffe\]](https://github.com/rbgirshick/fast-rcnn)[DeepProposal] DeepProposal: Hunting Objects by Cascading Deep Convolutional Layers | Amir Ghodrati, et al. | [ICCV' 15] |[
[pdf\]](https://arxiv.org/pdf/1510.04445.pdf) [[official code - matconvnet\]](https://github.com/aghodrati/deepproposal)[Faster R-CNN, RPN] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks | Shaoqing Ren, et al. | [NIPS' 15] |[
[pdf\]](https://papers.nips.cc/paper/5638-faster-r-cnn-towards-real-time-object-detection-with-region-proposal-networks.pdf) [[official code - caffe\]](https://github.com/rbgirshick/py-faster-rcnn) [[unofficial code - tensorflow\]](https://github.com/endernewton/tf-faster-rcnn) [[unofficial code - pytorch\]](https://github.com/jwyang/faster-rcnn.pytorch)
2016年的论文
[YOLO v1] You Only Look Once: Unified, Real-Time Object Detection | Joseph Redmon, et al. | [CVPR' 16] |[
[pdf\]](https://arxiv.org/pdf/1506.02640.pdf)[[official code - c\]](https://pjreddie.com/darknet/yolo/)[G-CNN] G-CNN: an Iterative Grid Based Object Detector | Mahyar Najibi, et al. | [CVPR' 16] |[
[pdf\]](https://arxiv.org/pdf/1512.07729.pdf)[AZNet] Adaptive Object Detection Using Adjacency and Zoom Prediction | Yongxi Lu, Tara Javidi. | [CVPR' 16] |[
[pdf\]](https://arxiv.org/pdf/1512.07711.pdf)[ION] Inside-Outside Net: Detecting Objects in Context with Skip Pooling and Recurrent Neural Networks | Sean Bell, et al. | [CVPR' 16] |[
[pdf\]](https://arxiv.org/pdf/1512.04143.pdf)[HyperNet] HyperNet: Towards Accurate Region Proposal Generation and Joint Object Detection | Tao Kong, et al. | [CVPR' 16] |[
[pdf\]](https://arxiv.org/pdf/1604.00600.pdf)[OHEM] Training Region-based Object Detectors with Online Hard Example Mining | Abhinav Shrivastava, et al. | [CVPR' 16] |[
[pdf\]](https://arxiv.org/pdf/1604.03540.pdf) [[official code - caffe\]](https://github.com/abhi2610/ohem)[CRAPF] CRAFT Objects from Images | Bin Yang, et al. | [CVPR' 16] |[
[pdf\]](https://arxiv.org/pdf/1604.03239.pdf) [[official code - caffe\]](https://github.com/byangderek/CRAFT)[MPN] A MultiPath Network for Object Detection | Sergey Zagoruyko, et al. | [BMVC' 16] |[
[pdf\]](https://arxiv.org/pdf/1604.02135.pdf) [[official code - torch\]](https://github.com/facebookresearch/multipathnet)[SSD] SSD: Single Shot MultiBox Detector | Wei Liu, et al. | [ECCV' 16] |[
[pdf\]](https://arxiv.org/pdf/1512.02325.pdf) [[official code - caffe\]](https://github.com/weiliu89/caffe/tree/ssd) [[unofficial code - tensorflow\]](https://github.com/balancap/SSD-Tensorflow) [[unofficial code - pytorch\]](https://github.com/amdegroot/ssd.pytorch)[GBDNet] Crafting GBD-Net for Object Detection | Xingyu Zeng, et al. | [ECCV' 16] |[
[pdf\]](https://arxiv.org/pdf/1610.02579.pdf) [[official code - caffe\]](https://github.com/craftGBD/craftGBD)[CPF] Contextual Priming and Feedback for Faster R-CNN | Abhinav Shrivastava and Abhinav Gupta | [ECCV' 16] |[
[pdf\]](https://pdfs.semanticscholar.org/40e7/4473cb82231559cbaeaa44989e9bbfe7ec3f.pdf)[MS-CNN] A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection | Zhaowei Cai, et al. | [ECCV' 16] |[
[pdf\]](https://arxiv.org/pdf/1607.07155.pdf) [[official code - caffe\]](https://github.com/zhaoweicai/mscnn)[R-FCN] R-FCN: Object Detection via Region-based Fully Convolutional Networks | Jifeng Dai, et al. | [NIPS' 16] |[
[pdf\]](https://arxiv.org/pdf/1605.06409.pdf)[[official code - caffe\]](https://github.com/daijifeng001/R-FCN) [[unofficial code - caffe\]](https://github.com/YuwenXiong/py-R-FCN)[PVANET] PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection | Kye-Hyeon Kim, et al. | [NIPSW' 16] |[
[pdf\]](https://arxiv.org/pdf/1608.08021.pdf) [[official code - caffe\]](https://github.com/sanghoon/pva-faster-rcnn)[DeepID-Net] DeepID-Net: Deformable Deep Convolutional Neural Networks for Object Detection | Wanli Ouyang, et al. | [PAMI' 16] |[
[pdf\]](https://arxiv.org/pdf/1412.5661.pdf)[NoC] Object Detection Networks on Convolutional Feature Maps | Shaoqing Ren, et al. | [TPAMI' 16] |[
[pdf\]](https://arxiv.org/pdf/1504.06066.pdf)
2017年的论文
[DSSD] DSSD : Deconvolutional Single Shot Detector | Cheng-Yang Fu1, et al. | [arXiv' 17] |[
[pdf\]](https://arxiv.org/pdf/1701.06659.pdf) [[official code - caffe\]](https://github.com/chengyangfu/caffe/tree/dssd)[TDM] Beyond Skip Connections: Top-Down Modulation for Object Detection | Abhinav Shrivastava, et al. | [CVPR' 17] |[
[pdf\]](https://arxiv.org/pdf/1612.06851.pdf)[FPN] Feature Pyramid Networks for Object Detection | Tsung-Yi Lin, et al. | [CVPR' 17] |[
[pdf\]](http://openaccess.thecvf.com/content_cvpr_2017/papers/Lin_Feature_Pyramid_Networks_CVPR_2017_paper.pdf) [[unofficial code - caffe\]](https://github.com/unsky/FPN)[YOLO v2] YOLO9000: Better, Faster, Stronger | Joseph Redmon, Ali Farhadi | [CVPR' 17] |[
[pdf\]](https://arxiv.org/pdf/1612.08242.pdf) [[official code - c\]](https://pjreddie.com/darknet/yolo/)[[unofficial code - caffe\]](https://github.com/quhezheng/caffe_yolo_v2) [[unofficial code - tensorflow\]](https://github.com/nilboy/tensorflow-yolo) [[unofficial code - tensorflow\]](https://github.com/sualab/object-detection-yolov2) [[unofficial code - pytorch\]](https://github.com/longcw/yolo2-pytorch)[RON] RON: Reverse Connection with Objectness Prior Networks for Object Detection | Tao Kong, et al. | [CVPR' 17] |[
[pdf\]](https://arxiv.org/pdf/1707.01691.pdf) [[official code - caffe\]](https://github.com/taokong/RON) [[unofficial code - tensorflow\]](https://github.com/HiKapok/RON_Tensorflow)[DCN] Deformable Convolutional Networks | Jifeng Dai, et al. | [ICCV' 17] |[
[pdf\]](http://openaccess.thecvf.com/content_ICCV_2017/papers/Dai_Deformable_Convolutional_Networks_ICCV_2017_paper.pdf) [[official code - mxnet\]](https://github.com/msracver/Deformable-ConvNets) [[unofficial code - tensorflow\]](https://github.com/Zardinality/TF_Deformable_Net) [[unofficial code - pytorch\]](https://github.com/oeway/pytorch-deform-conv)[DeNet] DeNet: Scalable Real-time Object Detection with Directed Sparse Sampling | Lachlan Tychsen-Smith, Lars Petersson | [ICCV' 17] |[
[pdf\]](https://arxiv.org/pdf/1703.10295.pdf) [[official code - theano\]](https://github.com/lachlants/denet)[CoupleNet] CoupleNet: Coupling Global Structure with Local Parts for Object Detection | Yousong Zhu, et al. | [ICCV' 17]|[
[pdf\]](https://arxiv.org/pdf/1708.02863.pdf) [[official code - caffe\]](https://github.com/tshizys/CoupleNet)[RetinaNet] Focal Loss for Dense Object Detection | Tsung-Yi Lin, et al. | [ICCV' 17] |[
[pdf\]](https://arxiv.org/pdf/1708.02002.pdf) [[official code - keras\]](https://github.com/fizyr/keras-retinanet)[[unofficial code - pytorch\]](https://github.com/kuangliu/pytorch-retinanet) [[unofficial code - mxnet\]](https://github.com/unsky/RetinaNet) [[unofficial code - tensorflow\]](https://github.com/tensorflow/tpu/tree/master/models/official/retinanet)[Mask R-CNN] Mask R-CNN | Kaiming He, et al. | [ICCV' 17] |[
[pdf\]](http://openaccess.thecvf.com/content_ICCV_2017/papers/He_Mask_R-CNN_ICCV_2017_paper.pdf) [[official code - caffe2\]](https://github.com/facebookresearch/Detectron) [[unofficial code - tensorflow\]](https://github.com/matterport/Mask_RCNN) [[unofficial code - tensorflow\]](https://github.com/CharlesShang/FastMaskRCNN) [[unofficial code - pytorch\]](https://github.com/multimodallearning/pytorch-mask-rcnn)[DSOD] DSOD: Learning Deeply Supervised Object Detectors from Scratch | Zhiqiang Shen, et al. | [ICCV' 17] |[
[pdf\]](https://arxiv.org/pdf/1708.01241.pdf)[[official code - caffe\]](https://github.com/szq0214/DSOD) [[unofficial code - pytorch\]](https://github.com/uoip/SSD-variants)[SMN] Spatial Memory for Context Reasoning in Object Detection | Xinlei Chen, Abhinav Gupta | [ICCV' 17] |[
[pdf\]](http://openaccess.thecvf.com/content_ICCV_2017/papers/Chen_Spatial_Memory_for_ICCV_2017_paper.pdf)
2018年的论文
[YOLO v3] YOLOv3: An Incremental Improvement | Joseph Redmon, Ali Farhadi | [arXiv' 18] |[
[pdf\]](https://pjreddie.com/media/files/papers/YOLOv3.pdf) [[official code - c\]](https://pjreddie.com/darknet/yolo/)[[unofficial code - pytorch\]](https://github.com/ayooshkathuria/pytorch-yolo-v3) [[unofficial code - pytorch\]](https://github.com/eriklindernoren/PyTorch-YOLOv3) [[unofficial code - keras\]](https://github.com/qqwweee/keras-yolo3) [[unofficial code - tensorflow\]](https://github.com/mystic123/tensorflow-yolo-v3)[ZIP] Zoom Out-and-In Network with Recursive Training for Object Proposal | Hongyang Li, et al. | [IJCV' 18] |[
[pdf\]](https://arxiv.org/pdf/1702.05711.pdf)[[official code - caffe\]](https://github.com/hli2020/zoom_network)[SIN] Structure Inference Net: Object Detection Using Scene-Level Context and Instance-Level Relationships | Yong Liu, et al. | [CVPR' 18] |[
[pdf\]](http://openaccess.thecvf.com/content_cvpr_2018/papers/Liu_Structure_Inference_Net_CVPR_2018_paper.pdf) [[official code - tensorflow\]](https://github.com/choasup/SIN)[STDN] Scale-Transferrable Object Detection | Peng Zhou, et al. | [CVPR' 18] |[
[pdf\]](http://openaccess.thecvf.com/content_cvpr_2018/papers/Zhou_Scale-Transferrable_Object_Detection_CVPR_2018_paper.pdf)[RefineDet] Single-Shot Refinement Neural Network for Object Detection | Shifeng Zhang, et al. | [CVPR' 18] |[
[pdf\]](http://openaccess.thecvf.com/content_cvpr_2018/papers/Zhang_Single-Shot_Refinement_Neural_CVPR_2018_paper.pdf)[[official code - caffe\]](https://github.com/sfzhang15/RefineDet) [[unofficial code - chainer\]](https://github.com/fukatani/RefineDet_chainer) [[unofficial code - pytorch\]](https://github.com/lzx1413/PytorchSSD)[MegDet] MegDet: A Large Mini-Batch Object Detector | Chao Peng, et al. | [CVPR' 18] |[
[pdf\]](http://openaccess.thecvf.com/content_cvpr_2018/papers/Peng_MegDet_A_Large_CVPR_2018_paper.pdf)[DA Faster R-CNN] Domain Adaptive Faster R-CNN for Object Detection in the Wild | Yuhua Chen, et al. | [CVPR' 18] |[
[pdf\]](http://openaccess.thecvf.com/content_cvpr_2018/papers/Chen_Domain_Adaptive_Faster_CVPR_2018_paper.pdf) [[official code - caffe\]](https://github.com/yuhuayc/da-faster-rcnn)[SNIP] An Analysis of Scale Invariance in Object Detection – SNIP | Bharat Singh, Larry S. Davis | [CVPR' 18] |[
[pdf\]](https://arxiv.org/pdf/1711.08189.pdf)[Relation-Network] Relation Networks for Object Detection | Han Hu, et al. | [CVPR' 18] |[
[pdf\]](https://arxiv.org/pdf/1711.11575.pdf) [[official code - mxnet\]](https://github.com/msracver/Relation-Networks-for-Object-Detection)[Cascade R-CNN] Cascade R-CNN: Delving into High Quality Object Detection | Zhaowei Cai, et al. | [CVPR' 18] |[
[pdf\]](http://openaccess.thecvf.com/content_cvpr_2018/papers/Cai_Cascade_R-CNN_Delving_CVPR_2018_paper.pdf)[[official code - caffe\]](https://github.com/zhaoweicai/cascade-rcnn)Finding Tiny Faces in the Wild with Generative Adversarial Network | Yancheng Bai, et al. | [CVPR' 18] |[
[pdf\]](https://ivul.kaust.edu.sa/Documents/Publications/2018/Finding%20Tiny%20Faces%20in%20the%20Wild%20with%20Generative%20Adversarial%20Network.pdf)[STDnet] STDnet: A ConvNet for Small Target Detection | Brais Bosquet, et al. | [BMVC' 18] |[
[pdf\]](http://bmvc2018.org/contents/papers/0897.pdf)[RFBNet] Receptive Field Block Net for Accurate and Fast Object Detection | Songtao Liu, et al. | [ECCV' 18] |[
[pdf\]](https://arxiv.org/pdf/1711.07767.pdf)[[official code - pytorch\]](https://github.com/ruinmessi/RFBNet)Zero-Annotation Object Detection with Web Knowledge Transfer | Qingyi Tao, et al. | [ECCV' 18] |[
[pdf\]](http://openaccess.thecvf.com/content_ECCV_2018/papers/Qingyi_Tao_Zero-Annotation_Object_Detection_ECCV_2018_paper.pdf)[CornerNet] CornerNet: Detecting Objects as Paired Keypoints | Hei Law, et al. | [ECCV' 18] |[
[pdf\]](https://arxiv.org/pdf/1808.01244.pdf) [[official code - pytorch\]](https://github.com/princeton-vl/CornerNet)[Pelee] Pelee: A Real-Time Object Detection System on Mobile Devices | Jun Wang, et al. | [NIPS' 18] |[
[pdf\]](http://papers.nips.cc/paper/7466-pelee-a-real-time-object-detection-system-on-mobile-devices.pdf) [[official code - caffe\]](https://github.com/Robert-JunWang/Pelee)[HKRM] Hybrid Knowledge Routed Modules for Large-scale Object Detection | ChenHan Jiang, et al. | [NIPS' 18] |[
[pdf\]](http://papers.nips.cc/paper/7428-hybrid-knowledge-routed-modules-for-large-scale-object-detection.pdf)[MetaAnchor] MetaAnchor: Learning to Detect Objects with Customized Anchors | Tong Yang, et al. | [NIPS' 18] |[
[pdf\]](http://papers.nips.cc/paper/7315-metaanchor-learning-to-detect-objects-with-customized-anchors.pdf)[SNIPER] SNIPER: Efficient Multi-Scale Training | Bharat Singh, et al. | [NIPS' 18] |[
[pdf\]](http://papers.nips.cc/paper/8143-sniper-efficient-multi-scale-training.pdf)
2019年的论文
[M2Det] M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network | Qijie Zhao, et al. | [AAAI' 19] |[
[pdf\]](https://arxiv.org/pdf/1811.04533.pdf)
实验
SlowFast 网络在 Kinetics 和 AVA 数据集上具体表现如何?我们通过研究中的一些实验数据对比看一下各数据结果。
▌Kinetics 数据集的动作分类
对于视频动作分类,作者采用 Kinetics-400 数据集,其中包含约 240k 个训练视频数据和20k个验证数据,共涵盖400种动作类别。实验结果得到 Top1 和 Top5 的分类准确性,单条 Slow 网络与 SlowFast 网络的性能对比,以及 SlowFast 网络与 Kibetics-400 数据集上当前最佳模型之间的性能对比,详细结果如下图3,图4,图5所示。
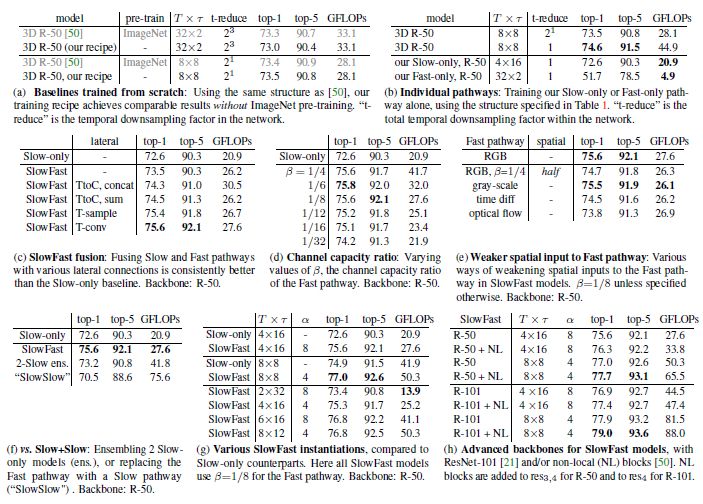
图3 Kinetics-400 数据集动作分类结果,包括 top-1 和 top-5 分类准确度,以及计算复杂度 GFLOPs。
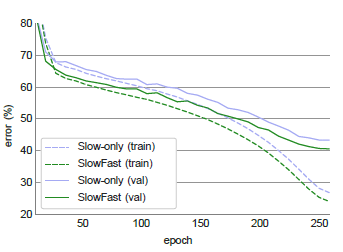
图4 Kinetics-400 数据集上 Slow-only 网络与 SlowFast 网络的性能对比;top-1 训练误差 (虚线表示) 和验证误差 (实线表示)。
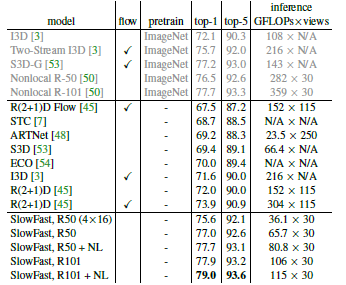
图5 Kinetics-400 数据集上当前最佳模型与 SlowFast 网络的性能对比。
▌AVA 数据集的动作检测
对于视频动作检测,作者采用 AVA 数据集,其中包含有 211k 个训练数据和 57k 个验证数据,共涵盖 60 种动作类别。实验结果得到 60 个类别的平均精度 mAP 值,SlowFast 网络与 AVA 数据集上当前最佳模型之间的性能对比,以及 AVA 数据集动作检测结果的可视化过程,详细结果如下图 6,图 7,图 8 所示。
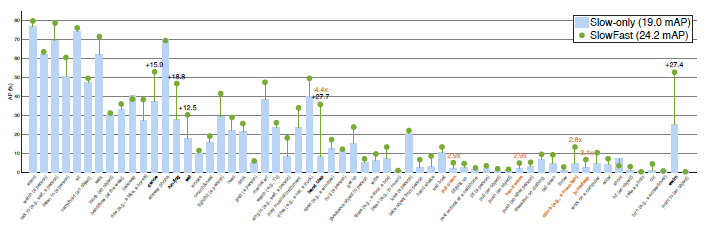
图6 AVA 数据集上每个类别的 AP:Slow-only 模型的 19.0 mAP vs. SlowFast 模型的 24.2 mAP。其中,黑色突出显示的是绝对增长最高的5个类别,而这里实例化的 SlowFast 网络并不是最佳的模型。
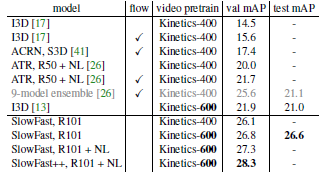
图7 AVA 数据集上最佳模型与 SlowFast 网络的性能对比。其中,++ 表示在测试过程引入了诸如水平翻转的图像增强操作。
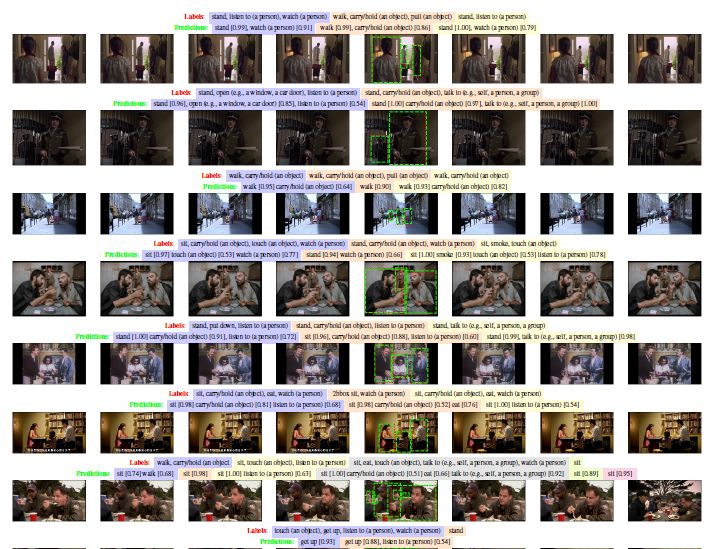
图8 可视化 AVA 数据集的动作检测结果。其中真实的标签用红色表示,而 SlowFast 模型在验证集上的预测结果用绿色表示。
总结
本文提出了一种用于视频识别的 SlowFast 网络。该模型由两部分组成:以低帧率运行以捕捉空间语义信息的 Slow pathway;以高帧率运行捕捉较好时序分辨率的运动信息的 Fast pathway。通过减少通道容量,所设计的 Fast pathway 是个非常轻量级的、同时又能够将学习到有用的时间信息用于视频识别的网络。
SlowFast 网络在视频动作分类及检测任务上展现了强大的性能,同时这种快慢结合思想的提出也为视频目标识别和检测领域做出了重要贡献。实验结果表明,在没有使用任何预训练模型的情况下,SlowFast 网络在 Kinetics 数据集上取得了 79.0% 的准确率,大大超过了以前同类方法的最佳结果。而在 AVA 动作检测数据集上,该网络同样实现了 28.3 mAP 的当前最佳水准。
总的来说,时间维度是视频任务中一个特殊的因素,本文的 SlowFast 网络框架考虑时间维度上不同的速度对时空信息捕捉的影响,实例化的 SlowFast 模型在 Kinetics 和 AVA 数据集上实现当前最佳的视频动作分类和检测结果,希望这种快慢结合的设计理念能够促进视频识别领域未来的研究。有关的项目代码将会在近期开源。
论文地址:
https://arxiv.org/abs/1812.03982
*推荐文章*
每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击左下角“阅读原文”立刻申请入群~





