阿里小蜜数字人互动决策的探索与落地

分享嘉宾:祖新星 阿里巴巴 算法专家
编辑整理:陈婷 平安科技
出品平台:DataFunTalk
导读:随着技术的进步,社会正在不断朝元宇宙时代迈进。以往的基于纯文本对话的交互形态,已经很难满足用户需要。结合潜在用户量、用户消费能力、以及用户活跃度数据来看,数字人将会有非常大的商业前景。本文将介绍近两三年以来,阿里小蜜在虚拟数字人方面的产品和技术探索。
今天的介绍会围绕下面几点展开:
阿里小蜜数字人发展史
如何从零构建一个数字人产品
如何提升数字人表现力
如何提升数字人互动能力
数字人多模态算法库-MMTK
阿里小蜜从在2019年开始探索大屏数字人应用,并构建了首个数字人形象,用于服务大厅、地铁站等进行咨询接待。之后从平台、数字人能力、IP、产品等不同维度逐步完善,近三年来,已提供了包括虚拟主播、虚拟辅播、公益数字人、云上数字人等多个产品。


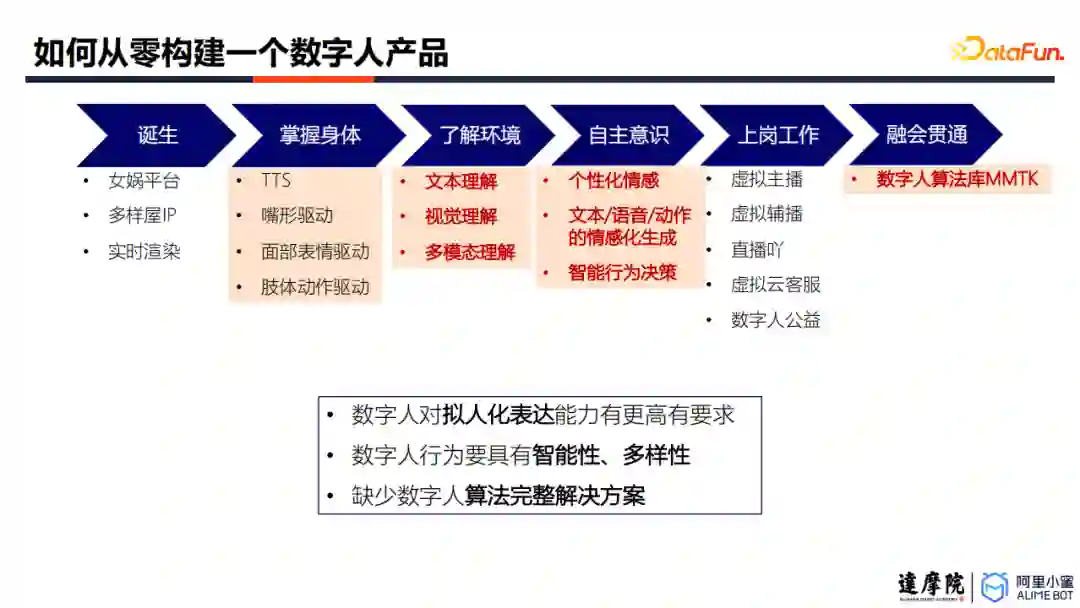
数字人构建主要包括六个部分,包括:
诞生:即构建基础的数字人形象的过程,包括数字人建模、数字人IP管理、数字人渲染等等;
掌握身体:使得数字人可以完成简单运动的过程,包括驱动数字人的声音、嘴型、表情以及肢体动作;
了解环境:通过多模态理解算法,使得数字人能够感知其环境,为进行互动奠定基础;
自主意识:让数字人拥有个性化的行为决策能力;
上岗工作:将数字人应用到各个业务场景中,包括虚拟主播、手语翻译等等;
融会贯通:不断对数字人技术进行更新迭代。
虽然上述流程中的很多技术要点与文本客服是共通的,例如TTS技术、文本理解、情感化技术等等。但实际上,数字人对这些技术会有更高的要求。具体来讲,客服场景是一个一对一场景,且大多基于单轮对话;但在数字人场景中,我们会尝试和虚拟人进行大段的交流,并期待数字人提供长时间的情感陪伴。那么,就对数字人的拟人化有更高的要求。同时,我们不希望数字人的行为千篇一律。也就是说,我们需要让数字人的行为具有一定的多样性。
目前,数字人技术有三大难点:
数字人对拟人化表能力有更高的要求
数字人的行为要有智能性、多样性
缺少数字人算法完整解决方案
接下来将介绍针对以上三大难点,数字人小蜜团队近年来开展的工作。
清水出芙蓉,天然去雕饰
——如何提升数字人表现力——
与文本客服场景不同,数字人需要具有丰富的情感,以及贴近人类的表达形式,才能够在长时间的交流中吸引用户的注意力。要提高数字人的表现力,首先要对情感具有更加细致的定义,并通过文本、声音、动作三方面,增强其表现能力。
1. 个性化情感分析方法
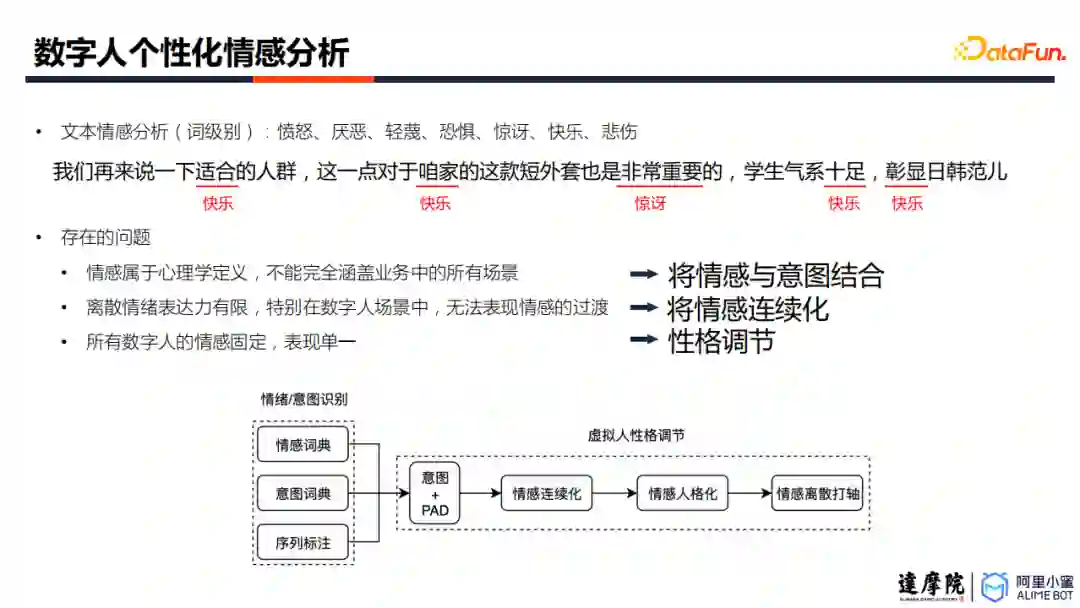
以往在文本客服场景下,只需要将文本情感分为离散的几个类别,就可以大致满足需求。但如此简单的情感定义无法满足细致的情感控制。主要有三个原因:第一,情感定义困难,无法涵盖所有业务场景;第二,离散标签下,无法表现情绪的过渡;第三,所有数字人的情感固定,表现单一。针对以上三个问题,数字人小蜜团队提供了三个解决方案。

首先,将情感与用户行为意图相结合,实现更为丰富的情感建模。
第二,通过标签连续化技术,将情感建模为可连续化调节的参数,从而实现更细粒度的控制。
第三,可以引入不同的“性格脚本”,结合连续化情感控制技术,实现多样性的数字人性格调节。例如,生气的过程包括诱发、积累、爆发、平复四个阶段。对于比较腼腆的人,诱发较困难,积累会较慢,爆发的延续较短,平复速度较快;但比较暴躁的人,诱发较容易,积累会更快,爆发的持续时间更长,而平复也需要更长时间。
2. 文本表现力增强方案-StyleTransfer
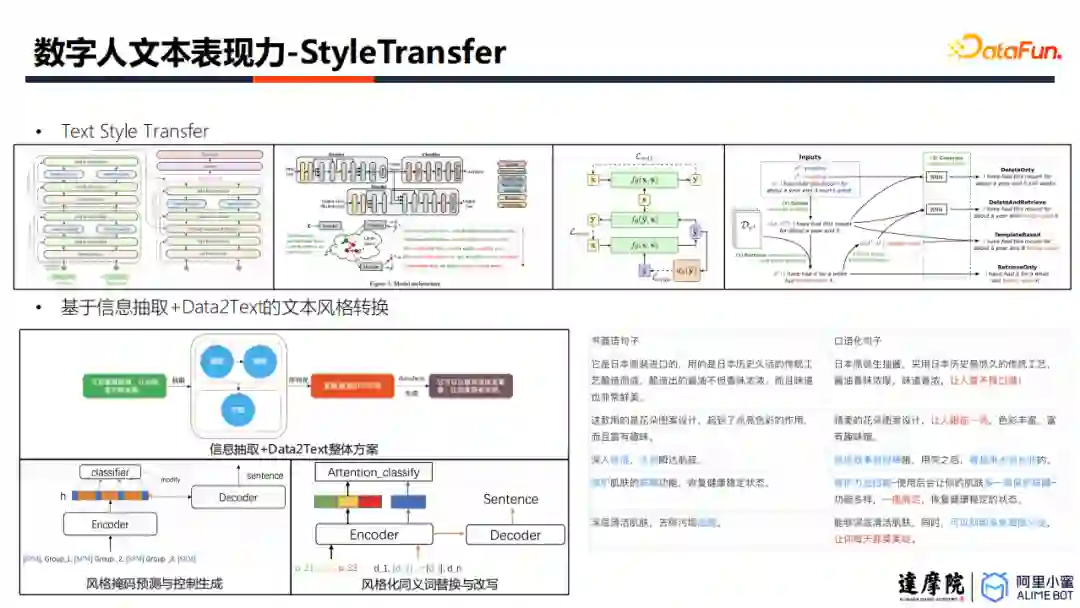
有了细粒度的情感控制能力之后,我们需要考虑如何将情感融入到虚拟人需要表达的内容中去。也就是说,需要在保证文本内容不变的情况下,对文本的风格进行修改。数字人小蜜团队将其定义为文本风格迁移问题。
文本风格迁移的主要方案有几类,包括有监督翻译、内容改写、风格解耦等。数字人小蜜团队选择使用信息抽取+Data2Text的方案实现风格迁移。它包括两个关键技术,其一是引入情绪风格掩码实现非平行语料下的文本风格迁移,其二是实现风格化的同义词改写与替换。这样做有两大优点,第一是结构上方便在预训练模型进行微调,第二是比起单纯依赖GPT实现文本生成,Data2Text方案可以依赖更多模型输入,实现更好的输出控制。
3. 声音表现力增强方案-风格化TTS
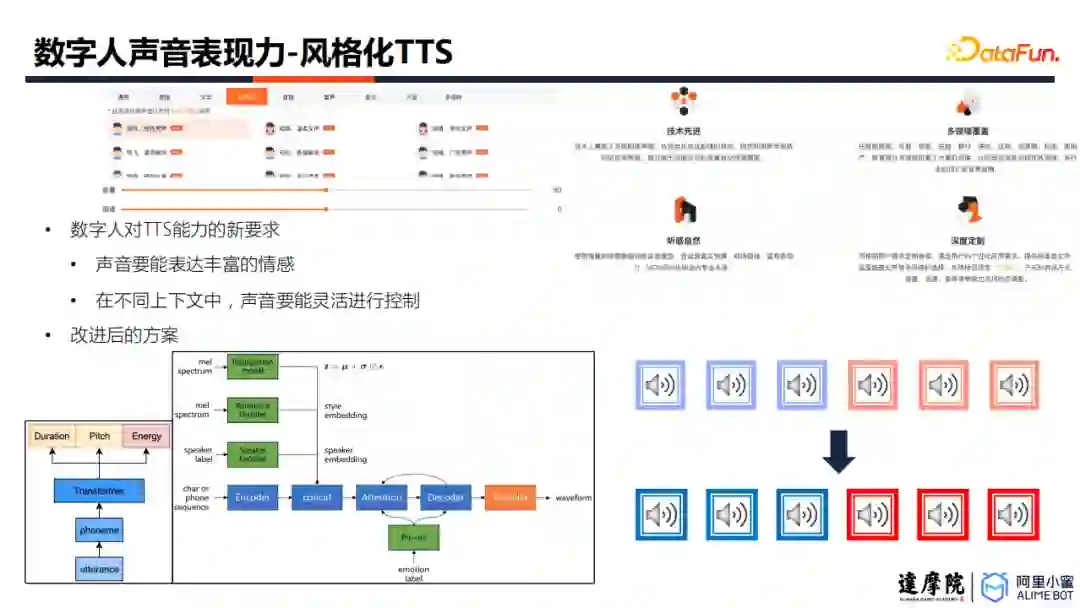
内容有了之后,我们希望数字人使用具有高表现力的声音,将内容表达出来,以实现更加丰富的情感表达。为了实现更加丰富的韵律控制,需要对原有的TTS方案进行改进。数字人小蜜团队引入了五个控制参数,包括pitch、energy、duration、speaker embedding以及emotion label。改进之后,合成的语音会有更加丰富的语音表现力。
4. 动作表现力增强方案-Text2Action
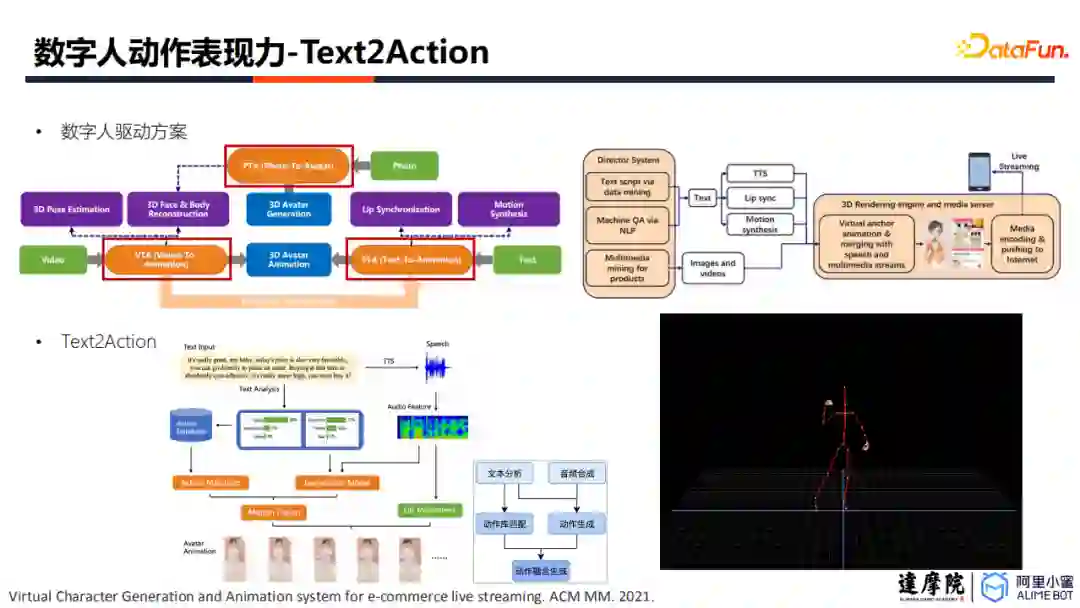
接下来需要实现数字人动作模拟,也就是如何驱动数字人的动作。首先,产生候选的动作列表,可以通过输入文本标签,自动在预录制的动作库中匹配动作,也可以结合文本与音频,通过模型预测动作序列;接着,需要对动作进行衔接,依靠模型生成串接动作,并结合动作融合技术,提高数字人的肢体协调性;最后,需要配合音频,实现数字人动作与声音的卡点融合。
海内存知己,天涯若比邻
——如何提升数字人互动能力——
通过上述的技术,数字人已经拥有很好的情感、声音和动作,可以以高表现力进行任意单句话的表达。但是,仅靠高表现力,无法驱动数字人和用户进行长时间的交流。因此,需要提高数字人的互动能力。
1. 可控性直播剧本生产
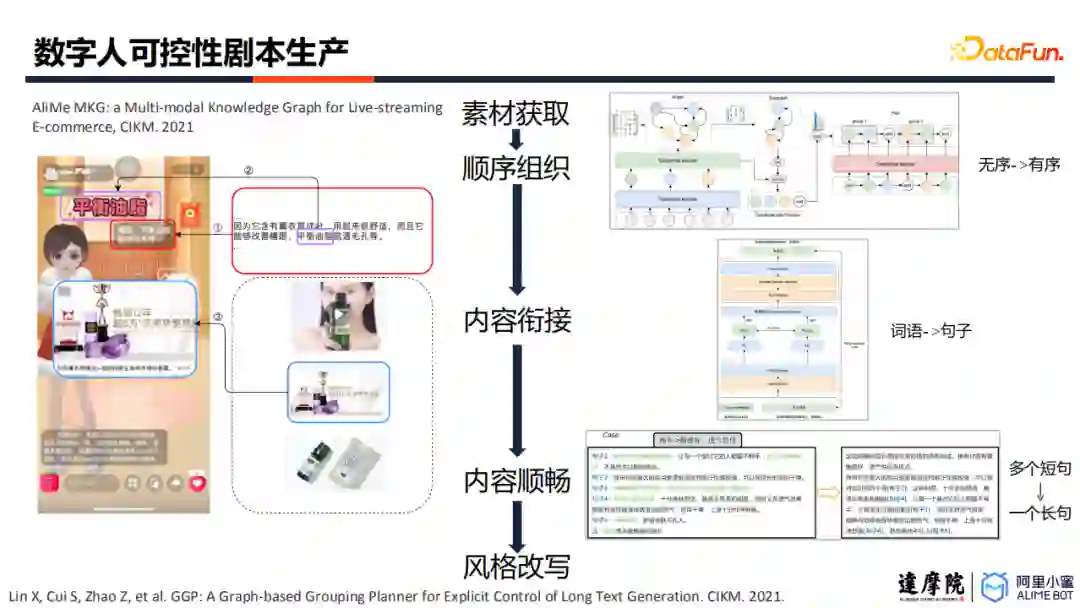
为了实现长时间的互动,需要完成长文本生成任务,数字人小蜜团队将该任务共建模为五个阶段:
第一个阶段,素材获取。通过淘系以往积累的商品知识图谱,获取商品的销售卖点。
第二个阶段,顺序组织。将孤立的卖点进行串联,形成有序的内容。需要把相关内容进行分组,并且按照层次递进关系为其排序。
第三个阶段,内容衔接。通过Data2Text技术,将有序的词语改写为句子。
第四个阶段,内容顺畅。将多个短句融合为一个长句,需要对句子进行检索、排序、摘要以及改写。
第五个阶段,风格改写。对已合成的长文本进行风格化的改写。
2. 多模态问答
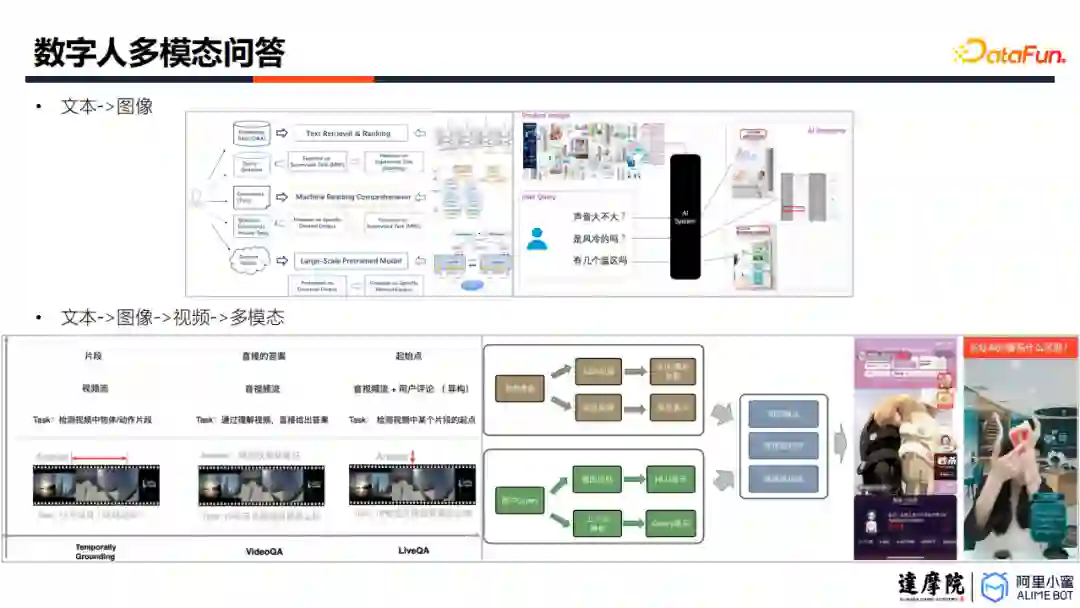
数字人需要结合文本、图像、视频、声音、动作等多个模态提供回答,就需要解决用户问题理解、多模态素材理解,以及二者之间的匹配对齐问题。相关技术在之前文章中有很多涉及,大家也可以关注后续的阿里数字人小蜜多模态交互/问答专题,这里就不再赘述。
3. 双向手语翻译
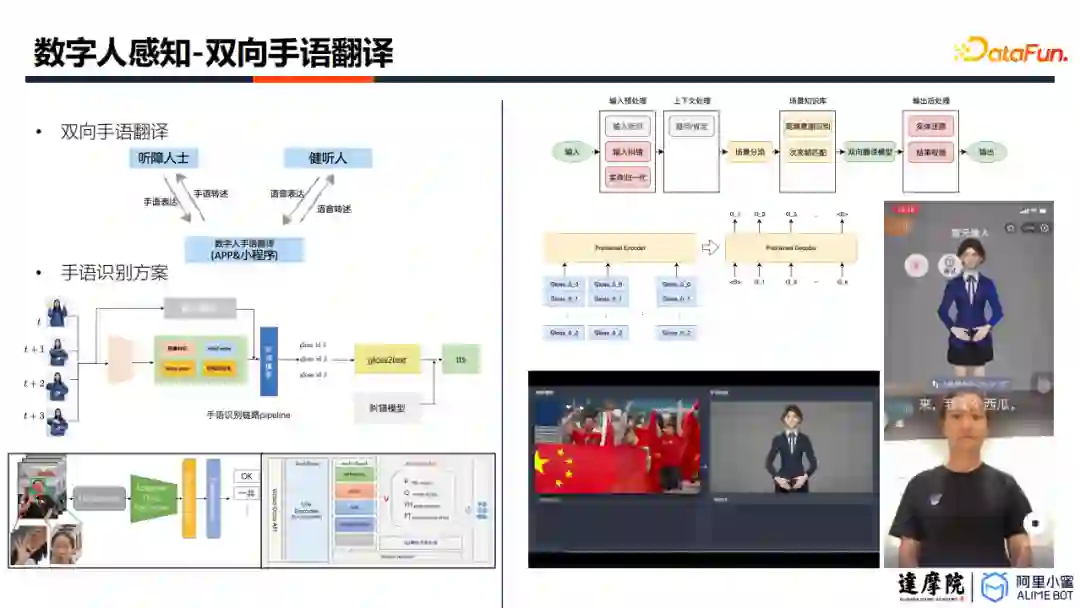
在数字人感知互动方面,数字人小蜜团队推出了双向手语翻译的产品。虽然已有一些厂商相继推出了手语合成产品,但数字人小蜜团队实现了双向互译。其链路一共包括三个技术环节:手势识别、自然手语与自然语言互译,以及手势合成。
手势识别:是双向手语翻译的核心难点。在获得视觉信号后,需要进行特征提取、关键帧检测、断句等技术之后,才能实现手语词汇识别。
自然手语与自然语言互译:聋人所使用的自然手语区别于手势汉语,其手势语言的语法语序,与自然语言有较大差距。因此,自然手语无法直接被普通人所理解,反之亦然。需要使用序列到序列的翻译模型,实现两者的互译。
手势合成:与传统的数字人驱动算法相类似,不再赘述。
4. 智能行为决策
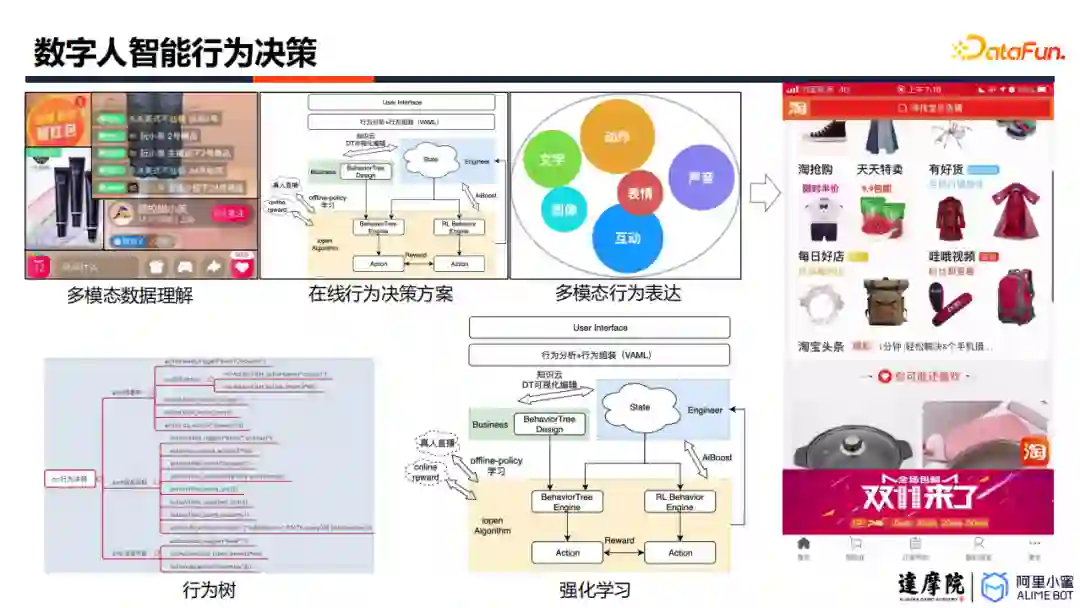
在数字人场景中,会有多个数字人同时出现(元宇宙),或者一个数字人需要响应多个用户(互动直播)。因此,数字人需要拥有行为决策能力,根据其环境决定其后续行为。数字人小蜜团队提出专家行为决策+强化学习的解决方案。首先,基于行为树构建数字人的初始行为能力;后续,利用强化学习技术,设计不同的reward来调节数字人行为,使得在线上运行一段时间之后,各个数字人会拥有差异性的决策逻辑。
工欲善其事,必先利其器

数字人技术是一个非常综合的方向,它不仅仅是单纯的文本或者单纯的视觉,而是涉及到文本、视觉、声音等多个模态,以及渲染相关的工作。MMTK是数字人小蜜团队在数字人构建方向沉淀下的算法工作,提供了多个开箱即用的模型。该库已经支持了10+个阿里数字人算法项目。同时,为了支持后续可能的技术发展,该库采用了分层以及可插拔的架构设计。数字人小蜜团队已经在该领域积累了近10篇相关顶会论文,未来还将继续探索该领域。
最后回顾一下前面介绍的内容:
首先,介绍了数字人新时代具有的大规模商业潜力,以及我们近两年在数字人产品上的布局;
接着,从数字人诞生、模型驱动、环境感知与理解、自主行为驱动、落地场景、基础算法库等方面,介绍了阿里数字人从零开始的构建过程;
第三部分介绍了个性化情感分析方法、以及在此基础上的文本/声音/动作增强方案,以提升数字人的表现力;
第四部分从可控性直播剧本生产、多模态问答、双向手语翻译、智能行为决策等几个方面,讲解了如何提升数字人的互动能力;
最后,简单介绍了我们团队为数字人产品化搭建的多模态算法库-MMTK。
展望未来,还有很多工作需要我们去探索和沉淀,除了更多业务场景的落地,在技术上我们希望实现更加拟人化、更丰富的情感化表达,以及更智能的互动能力。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“虚拟数字人” 就可以获取《虚拟数字人相关报告》专知下载链接

请扫码加入专知人工智能群(长按二维码),或者加专知小助手微信(zhuanzhi02),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG、论文等)交流~






