Github 项目推荐 | SpaceX Falcon 9 Box2D 回收降落动作模拟器

这是一款 SpaceX Falcon 9 第一级火箭的垂直火箭着陆模拟器,该模拟器用 Python 3.5 开发并且在 OpenAI Gym 环境中编写。该模拟器采用的是 Box2D 物理引擎,环境和 Lunar Lander 类似。以下为演示动画:
https://www.youtube.com/watch?v=4_igzo4qNmQ
Github:
https://github.com/arex18/rocket-lander
OpenAI Gym Environment:
https://gym.openai.com/docs/
Lunar Lander:
https://gym.openai.com/envs/LunarLander-v2/
此代码可用于:
模拟 PID 控制
模拟 DDPG 控制
模拟 MPC 控制
也可以用于(非通常用法):
模拟进化策略算法(ES)
函数逼近 Q-learning(FA Q-Learning)
线性二次型调节器(LQR)
该项目主要贡献了模拟环境,其他的控制脚本在参考和文件中。
模拟代码在 environments 下。
快速开始
下载该库,然后用 pip 安装
前提
以下是运行该库所需的软件列表,Windows 用户请前往[Windows Python 扩展库](Python 扩展包的非官方 Windows 二进制文件)列表来安装 cvxpy 和其他任何失败的 pip 安装。
tensorflow
matplotlib
gym
numpy
Box2D
logging
pyglet
cvxpy
abc
concurrent
python pip install PATH_TO_YOUR_DOWNLOADED_LIBRARY (ending in whl)
检查功能
运行 main_simulation.py 并检查模拟是否开始,一个显示火箭的窗口应该弹出。如果从终端运行,只需:
python main_simulation.py
问题定义
介绍
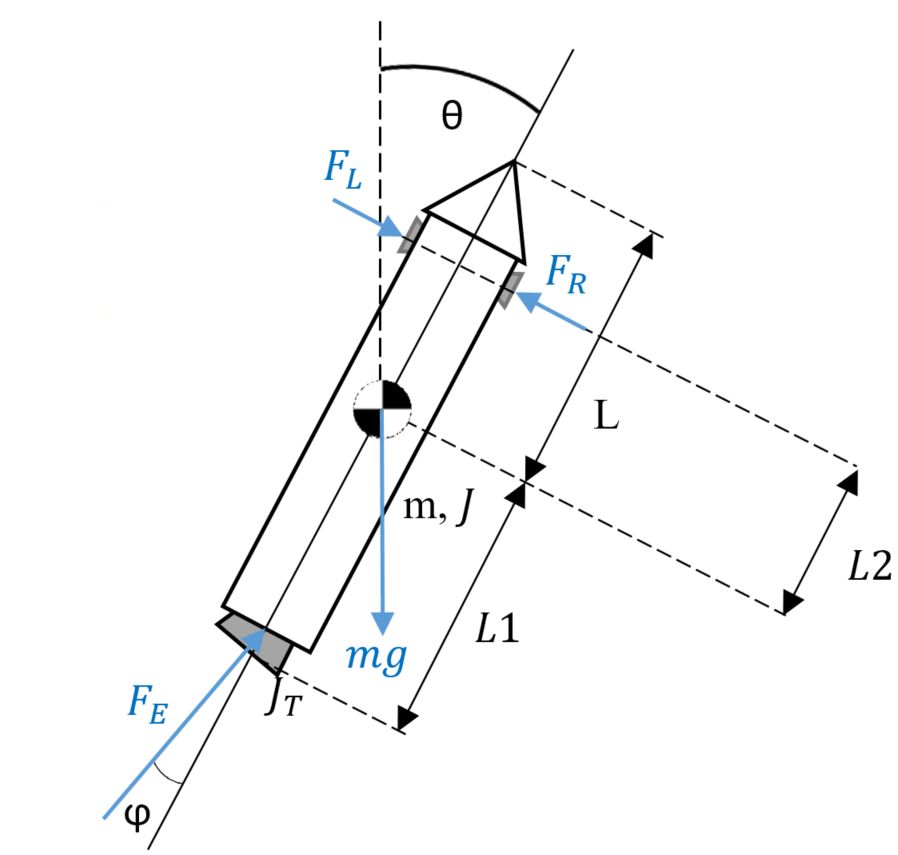
这个小型项目的重点在于将经典控制方法与 AI 算法进行比较和对比,以应用于连续控制问题。 这与动作空间离散的 lunar lander 不同。离散动作空间示例:
lunar_lander_horizontal_thrusters = {-1, -0.5, 0, 0.5, 1}
lunar_lander_vertical_thruster = {0, 0.5, 1}
连续动作空间示例:
lunar_lander_left_thruster = [0, 1] (negated in code)
lunar_lander_right_thruster = [0, 1]
lunar_lander_vertical_thruster = [0, 1]
然而,大多数现实生活问题都存在于连续状态和连续行动空间中。状态和动作域都可以离散化,但在实际应用中会有各种限制。
所以该模拟器的目的就是为了实现连续空间的仿真。PID,MPC,ES 和 DDPG算法进行比较之后,DDPG 表现出了令人印象深刻的结果。DDPG 解决了 Q-learning 离散动作空间的限制。虽然有些复杂,但 DDPG 获得最高效率和最佳总体控制。
模拟状态和动作
在代码中,状态被定义为:
State = [x_pos, y_pos, x_vel, y_vel, lateral_angle, angular_velocity]
Actions = Fe, Fs, $psi$
Fe = Main Engine (vertical thruster) [0, 1]
Fs = Side Nitrogen Thrusters [-1, 1]
Psi = Nozzle angle [-NOZZLE_LIMIT, NOZZLE_LIMIT]
所有的模拟设置,限制,多边形,云,海等都在 constants.py 文件中被定义为常量。
控制器
控制器的代码存放于 control_and_ai 下,DDPG 有独立的包。作者在设计原型和训练模型时写了一些非结构化的脚本,所以库中有些未经测试的混乱代码,在此作者表示歉意。另外,一些训练好的模型存放在不同的目录下。

从Python入门-如何成为AI工程师
BAT资深算法工程师独家研发课程
最贴近生活与工作的好玩实操项目
班级管理助学搭配专业的助教答疑
学以致用拿offer,学完即推荐就业

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据资料】
基于 Unity/OpenAI Gym/PyTorch/TF 的深度强化学习研究框架
▼▼▼





