深度学习在情感分析中的应用
本文选自图书《Keras快速上手:基于Python的深度学习实战》第七章。
自然语言情感分析简介
情感分析无处不在,它是一种基于自然语言处理的分类技术。其主要解决的问题是给定一段话,判断这段话是正面的还是负面的。例如在亚马逊网站或者推特网站中,人们会发表评论,谈论某个商品、事件或人物。商家可以利用情感分析工具知道用户对自己的产品的使用体验和评价。当需要大规模的情感分析时,肉眼的处理能力就变得十分有限了。
情感分析的本质就是根据已知的文字和情感符号,推测文字是正面的还是负面的。处理好了情感分析,可以大大提升人们对于事物的理解效率,也可以利用情感分析的结论为其他人或事物服务,比如不少基金公司利用人们对于某家公司、某个行业、某件事情的看法态度来预测未来股票的涨跌。
进行情感分析有如下难点:
第一,文字非结构化,有长有短,很难适合经典的机器学习分类模型。
第二,特征不容易提取。文字可能是谈论这个主题的,也可能是谈论人物、商品或事件的。人工提取特征耗费的精力太大,效果也不好。
第三,词与词之间有联系,把这部分信息纳入模型中也不容易。
本章探讨深度学习在情感分析中的应用。深度学习适合做文字处理和语义理解,是因为深度学习结构灵活,其底层利用词嵌入技术可以避免文字长短不均带来的处理困难。使用深度学习抽象特征,可以避免大量人工提取特征的工作。深度学习可以模拟词与词之间的联系,有局部特征抽象化和记忆功能。正是这几个优势,使得深度学习在情感分析,乃至文本分析理解中发挥着举足轻重的作用。
顺便说一句,推特已经公开了他们的情感分API(http://help.sentiment140.com/api)。读者可以把其整合到自己的应用程序中,也可以试着开发一套自己的API。下面通过一个电影评论的例子详细讲解深度学习在情感分析中的关键技术。
首先下载http://ai.stanford.edu/~amaas/data/sentiment/中的数据。
输入下文安装必要的软件包:
pip install numpy scipy
pip install scikit-learn
pip install pillow
pip install h5py
下面处理数据。Keras 自带了imdb 的数据和调取数据的函数,直接调用load.data()就可以了。
import kerasimport numpy as npfrom keras.datasets import imdb
(X_train, y_train), (X_test, y_test) = imdb.load_data()
先看一看数据长什么样子的。输入命令:
X_train[0]
我们可以看到结果:

原来,Keras 自带的load_data 函数帮我们从亚马逊S3 中下载了数据,并且给每个词标注了一个索引(index),创建了字典。每段文字的每个词对应了一个数字。
print(y[:10])
得到array([1, 0, 0, 1, 0, 0, 1, 0, 1, 0]),可见y 就是标注,1 表示正面,0 表示负面。
print(X_train.shape)print(y_train.shape)
我们得到的两个张量的维度都为(25000,)。
接下来可以看一看平均每个评论有多少个字:
avg_len = list(map(len, X_train))print(np.mean(avg_len))
可以看到平均字长为238.714。
为了直观显示,这里画一个分布图(见图7.1):
import matplotlib.pyplot as plt
plt.hist(avg_len, bins = range(min(avg_len), max(avg_len) + 50, 50))
plt.show()
注意,如果遇到其他类型的数据,或者自己有数据,那么就得自己写一套处理数据的脚本。大致步骤如下。
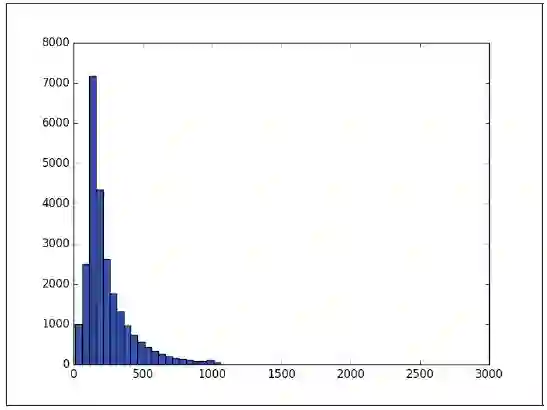
图7.1 词频分布直方图
第一,文字分词。英语分词可以按照空格分词,中文分词可以参考jieba。
第二,建立字典,给每个词标号。
第三,把段落按字典翻译成数字,变成一个array。
接下来就开始建模了。
文字情感分析建模
词嵌入技术
为了克服文字长短不均和将词与词之间的联系纳入模型中的困难,人们使用了一种技术——词嵌入。简单说来,就是给每个词赋一个向量,向量代表空间里的点,含义接近的词,其向量也接近,这样对于词的操作就可以转化为对于向量的操作了,在深度学习中,这被叫作张量(tensor)。
用张量表示词的好处在于:
第一,可以克服文字长短不均的问题,因为如果每个词已经有对应的词向量,那么对于长度为N 的文本,只要选取对应的N 个词所代表的向量并按文本中词的先后顺序排在一起,就是输入张量了,其中每个词向量的维度都是一样的。
第二,词本身无法形成特征,但是张量就是抽象的量化,它是通过多层神经网络的层层抽象计算出来的。
第三,文本是由词组成的,文本的特征可以由词的张量组合。文本的张量蕴含了多个词之间的组合含义,这可以被认为是文本的特征工程,进而为机器学习文本分类提供基础。
词的嵌入最经典的作品是Word2Vec,可以参见:https://code.google.com/archive/p/word2vec/。通过对具有数十亿词的新闻文章进行训练,Google 提供了一组词向量的结果,可以从http://word2vec.googlecode.com/svn/trunk/获取。其主要思想依然是把词表示成向量的形式,而不是One Hot 编码。图7.2展示了这个模型里面词与词的关系。
多层全连接神经网络训练情感分析
不同于已经训练好的词向量,Keras 提供了设计嵌入层(Embedding Layer)的模板。只要在建模的时候加一行Embedding Layer 函数的代码就可以。注意,嵌入层一般是需要通过数据学习的,读者也可以借用已经训练好的嵌入层比如Word2Vec 中预训练好的词向量直接放入模型,或者把预训练好的词向量作为嵌入层初始值,进行再训练。
Embedding 函数定义了嵌入层的框架,其一般有3 个变量:字典的长度(即文本中有多少词向量)、词向量的维度和每个文本输入的长度。注意,前文提到过每个文本可长可短,所以可以采用Padding 技术取最长的文本长度作为文本的输入长度,而不足长度的都用空格填满,即把空格当成一个特殊字符处理。空格本身一般也会被赋予词向量,这可以通过机器学习训练出来。Keras 提供了sequence.pad_sequences 函数帮我们做文本的处理和填充工作。
先把代码进行整理:
from keras.models import Sequentialfrom keras.layers import Densefrom keras.layers import Flattenfrom keras.layers.embeddings import Embeddingfrom keras.preprocessing import sequenceimport kerasimport numpy as npfrom keras.datasets import imdb
(X_train, y_train), (X_test, y_test) = imdb.load_data()
使用下面的命令计算最长的文本长度:
m = max(list(map(len, X_train)), list(map(len, X_test)))
print(m)
从中我们会发现有一个文本特别长,居然有2494 个字符。这种异常值需要排除,考虑到文本的平均长度为230 个字符,可以设定最多输入的文本长度为400 个字符,不足400 个字符的文本用空格填充,超过400 个字符的文本截取400 个字符,Keras 默认截取后400 个字符。
maxword = 400X_train = sequence.pad_sequences(X_train, maxlen = maxword)
X_test = sequence.pad_sequences(X_test, maxlen = maxword)
vocab_size = np.max([np.max(X_train[i]) for i in range(X_train.shape[0])]) + 1
这里1 代表空格,其索引被认为是0。
下面先从最简单的多层神经网络开始尝试:
首先建立序列模型,逐步往上搭建网络。
model = Sequential()
model.add(Embedding(vocab_size, 64, input_length = maxword))
第一层是嵌入层,定义了嵌入层的矩阵为vocab_size 64。每个训练段落为其中的maxword 64 矩阵,作为数据的输入,填入输入层。
model.add(Flatten())
把输入层压平,原来是maxword × 64 的矩阵,现在变成一维的长度为maxword × 64的向量。
接下来不断搭建全连接神经网络,使用relu 函数。relu 是简单的非线性函数:f(x) =max(0; x)。注意到神经网络的本质是把输入进行非线性变换。
model.add(Dense(2000, activation = 'relu'))
model.add(Dense(500, activation = 'relu'))
model.add(Dense(200, activation = 'relu'))
model.add(Dense(50, activation = 'relu'))
model.add(Dense(1, activation = 'sigmoid'))
这里最后一层用Sigmoid,预测0,1 变量的概率,类似于logistic regression 的链接函数,目的是把线性变成非线性,并把目标值控制在0~1。因此这里计算的是最后输出的是0 或者1 的概率。
model.compile(loss = 'binary_crossentropy', optimizer = 'adam', metrics = ['accuracy'])2 print(model.summary())
这里有几个概念要提一下:交叉熵(Cross Entropy)和Adam Optimizer。
交叉熵主要是衡量预测的0,1 概率分布和实际的0,1 值是不是匹配,交叉熵越小,说明匹配得越准确,模型精度越高。
其具体形式为
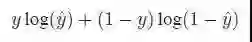
这里把交叉熵作为目标函数。我们的目的是选择合适的模型,使这个目标函数在未知数据集上的平均值越低越好。所以,我们要看的是模型在测试数据(训练时需要被屏蔽)上的表现。
Adam Optimizer 是一种优化办法,目的是在模型训练中使用的梯度下降方法中,合理地动态选择学习速度(Learning Rate),也就是每步梯度下降的幅度。直观地说,如果在训练中损失函数接近最小值了,则每步梯度下降幅度自然需要减小,而如果损失函数的曲线还很陡,则下降幅度可以稍大一些。从优化的角度讲,深度学习网络还有其他一些梯度下降优化方法,比如Adagrad 等。它们的本质都是解决在调整神经网络模型过程中如何控制学习速度的问题。
Keras 提供的建模API 让我们既能训练数据,又能在验证数据时看到模型测试效果。
model.fit(X_train, y_train, validation_data = (X_test, y_test), epochs = 20,batch_size = 100, verbose = 1)
score = model.evaluate(X_test, y_test)
其精确度大约在85%。如果多做几次迭代,则精确度会更高。读者可以试着尝试一下多跑几个循环。
以上提到的是最常用的多层全连接神经网络模型。它假设模型中的所有上一层和下一层是互相连接的,是最广泛的模型。
卷积神经网络训练情感分析
全连接神经网络几乎对网络模型没有任何限制,但缺点是过度拟合,即拟合了过多噪声。全连接神经网络模型的特点是灵活、参数多。在实际应用中,我们可能会对模型加上一些限制,使其适合数据的特点。并且由于模型的限制,其参数会大幅减少。这降低了模型的复杂度,模型的普适性进而会提高。
接下来我们介绍卷积神经网络(CNN)在自然语言的典型应用。
在自然语言领域,卷积的作用在于利用文字的局部特征。一个词的前后几个词必然和这个词本身相关,这组成该词所代表的词群。词群进而会对段落文字的意思进行影响,决定这个段落到底是正向的还是负向的。对比传统方法,利用词包(Bag of Words),和TF-IDF 等,其思想有相通之处。但最大的不同点在于,传统方法是人为构造用于分类的特征,而深度学习中的卷积让神经网络去构造特征。
以上便是卷积在自然语言处理中有着广泛应用的原因。
接下来介绍如何利用Keras 搭建卷积神经网络来处理情感分析的分类问题。下面的代码构造了卷积神经网络的结构。
from keras.layers import Dense, Dropout, Activation, Flattenfrom keras.layers import Conv1D, MaxPooling1D
model = Sequential()
model.add(Embedding(vocab_size, 64, input_length = maxword))
model.add(Conv1D(filters = 64, kernel_size = 3, padding = 'same', activation= 'relu'))
model.add(MaxPooling1D(pool_size = 2))
model.add(Dropout(0.25))
model.add(Conv1D(filters = 128, kernel_size = 3, padding = 'same',activation= 'relu'))
model.add(MaxPooling1D(pool_size = 2))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(64, activation = 'relu'))
model.add(Dense(32, activation = 'relu'))
model.add(Dense(1, activation = 'sigmoid'))
model.compile(loss = 'binary_crossentropy', optimizer = 'rmsprop', metrics =['accuracy'])
print(model.summary())
下面对模型进行拟合。
model.fit(X_train, y_train, validation_data = (X_test, y_test), epochs = 20,batch_size = 100)
scores = model.evaluate(X_test, y_test, verbose = 1)print(scores)
精确度提高了一点,在85.5% 左右。读者可以试着调整模型的参数,增加训练次数等,或者使用其他的优化方法。这里还要提一句,代码里用了一个Dropout 的技巧,大致意思是在每个批量训练过程中,对每个节点,不论是在输入层还是隐藏层,都有独立的概率让节点变成0。这样的好处在于,每次批量训练相当于在不同的小神经网络中进行计算,当训练数据大的时候,每个节点的权重都会被调整过多次。
另外,在每次训练的时候,系统会努力在有限的节点和小神经网络中找到最佳的权重,这样可以最大化地找到重要特征,避免过度拟合。这就是为什么Dropout 会得到广泛的应用。
循环神经网络训练情感分析
下面介绍如何用长短记忆模型(LSTM)处理情感分类。
LSTM 是循环神经网络的一种。本质上,它按照时间顺序,把信息进行有效的整合和筛选,有的信息得到保留,有的信息被丢弃。在时间t,你获得到的信息(比如对段落文字的理解)理所应当会包含之前的信息(之前提到的事件、人物等)。LSTM 说,根据我手里的训练数据,我得找出一个方法来如何进行有效的信息取舍,从而把最有价值的信息保留到最后。那么最自然的想法是总结出一个规律用来处理前一时刻的信息。
由于递归性,在处理前一个时刻信息时,会考虑到再之前的信息,所以到时间t 时,所有从时间点1 到现在的信息都或多或少地被保留一部分,也会被丢弃一部分。LSTM 对信息的处理主要通过矩阵的乘积运算来实现的(见图7.3)。
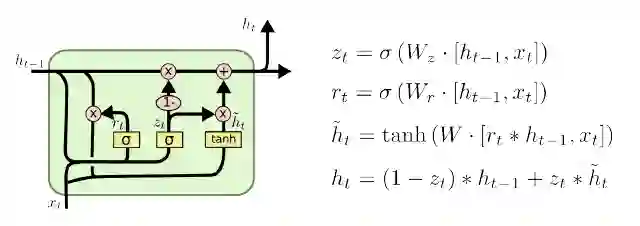
图7.3 长短记忆神经网络示意图(图片来源:http://colah.github.io/posts/2015-08-Understanding-LSTMs/)
构造LSTM 神经网络的结构可以使用如下的代码。
from keras.layers import LSTM
model = Sequential()
model.add(Embedding(vocab_size, 64, input_length = maxword))
model.add(LSTM(128, return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(64, return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(32))
model.add(Dropout(0.2))
model.add(Dense(1, activation = 'sigmoid'))
然后把模型打包。
model.compile(loss = 'binary_crossentropy', optimizer = 'rmsprop', metrics =['accuracy'])print(model.summary())
最后输入数据集训练模型。
model.fit(X_train, y_train, validation_data = (X_test, y_test), epochs = 5,batch_size = 100)
scores = model.evaluate(X_test, y_test)
print(scores)
预测的精确度大致为86.7%,读者可以试着调试不同参数和增加循环次数,从而得到更好的效果。
总结
本文介绍了不同种类的神经网络,有多层神经网络(MLP),卷积神经网络(CNN)和长短记忆模型(LSTM)。它们的共同点是有很多参数,需要通过后向传播来更新参数。
CNN 和LSTM 作为神经网络的不同类型的模型,需要的参数相对较少,这也反映了它们的一个共性:参数共享。这和传统的机器学习原理很类似:对参数或者模型加的限制越多,模型的自由度越小,越不容易过度拟合。反过来,模型参数越多,模型越灵活,越容易拟合噪声,从而对预测造成负面影响。通常,我们通过交叉验证技术选取最优参数(比如,几层模型、每层节点数、Dropout 概率等)。
最后需要说明的是,情感分析本质是一个分类问题,是监督学习的一种。除了上述模型,读者也可以试试其他经典机器学习模型,比如SVM、随机森林、逻辑回归等,并和神经网络模型进行比较。







