NeurlPS 2020 | 简约任务型对话,让对话实现不再繁琐

作者 | 蜗牛慢月
论文标题:A Simple Language Model for Task-Oriented Dialogue

1
介绍
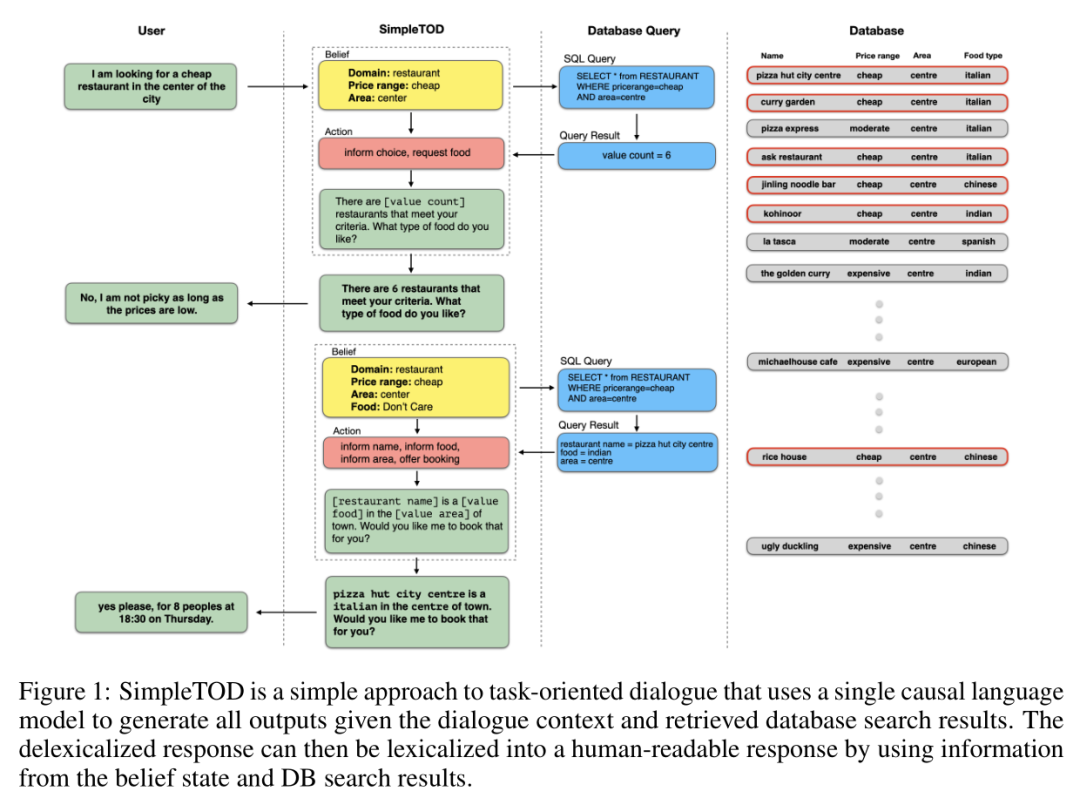
-
用户部分包含用户输入部分 -
Simple TOD返回给用户的答案
-
belief(信念状态):是用户文本处理机制,主要是用户信念提取(意图提取)。 -
Action(对话管理):对话流程的决策,主要依据从belief获取的信念状态,从数据库查询出的结果,生成问题答案。 -
其中,belief产生的结果,作为SQL Query的查询条件,去数据库检索结果。其检索得到的结果返回给Action,用于生成问题答案。
-
sql query:基于belief的查询语句的生成。 -
query result:从数据库中获取的查询结果。
2
模型
-
Task-Orientend Dialogue
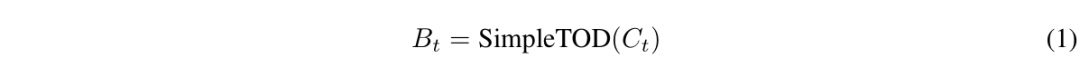
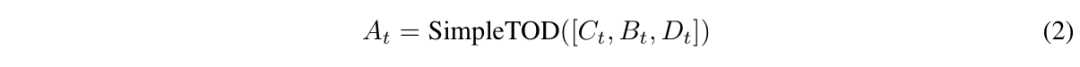
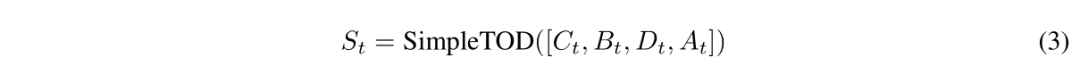
-
Causal Language Modeling
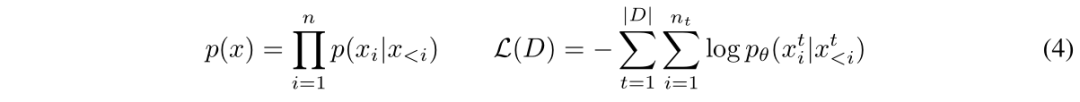
-
Architecture

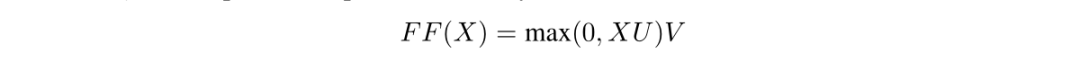

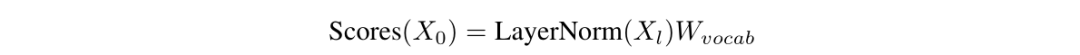
-
Training Details
-
Dataset Details
-
Evaluation Details
3
实验
-
Dialogue State Tracking

-
Action and Response Generation
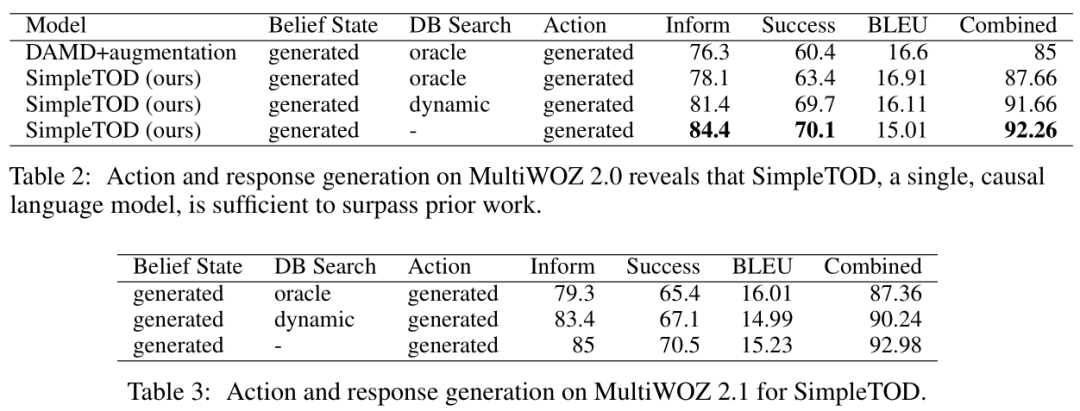
-
The Role of Special Tokens
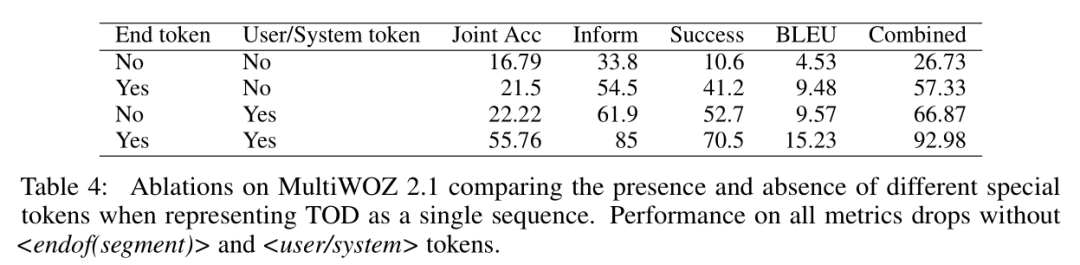
-
Pre-training
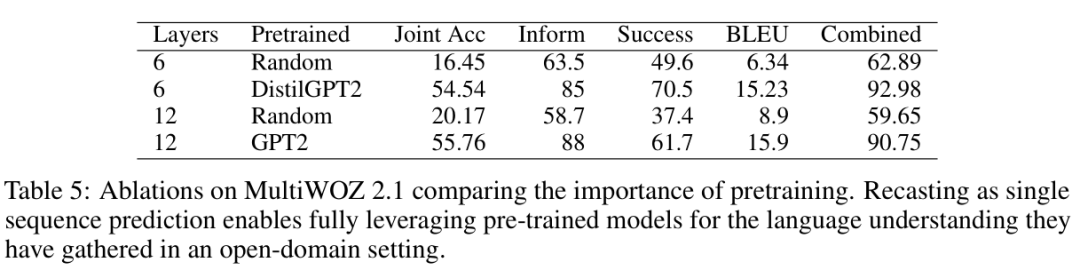
-
Robustness to Noisy Annotation
4
总结

由于微信公众号试行乱序推送,您可能不再能准时收到AI科技评论的推送。为了第一时间收到AI科技评论的报道, 请将“AI科技评论”设为星标账号,以及常点文末右下角的“在看”。
登录查看更多
相关内容
专知会员服务
33+阅读 · 2020年2月29日
Arxiv
7+阅读 · 2019年2月8日
Arxiv
4+阅读 · 2018年6月11日
Arxiv
5+阅读 · 2018年4月16日


相关VIP内容
专知会员服务
33+阅读 · 2020年2月29日
相关资讯
相关论文
Arxiv
7+阅读 · 2019年2月8日
Arxiv
4+阅读 · 2018年6月11日
Arxiv
5+阅读 · 2018年4月16日