业界 | 谷歌开源大规模神经网络模型高效训练库 GPipe

AI 科技评论按:谷歌昨日在博客中宣布开源大规模神经网络模型高效训练库 GPipe,这是一款分布式机器学习库,可以让研究员在不调整超参数的情况下,部署更多的加速器以对大规模模型进行训练,有效扩展了模型性能。雷锋网 AI 科技评论对此进行编译如下。
深度神经网络(DNNs)推进诸多机器学习任务的进步,其中包括语音识别、视觉识别和语言处理等。BigGan、Bert 、GPT2.0 等最新成果表明,DNN 的模型越大,任务处理的表现就越好,而该结论也在过去的视觉识别任务中得到了验证,表明模型大小与分类准确性之间存在很强的关联性。举个例子,2014 年 ImageNet 视觉识别挑战赛的冠军 GoogleNet 通过对 400 万参数进行调整,最终取得 74.8 % 的精确度成绩;仅仅过了三年,2017 年 ImageNet 挑战赛冠军 Squeeze-and-Excitation Networks 调整的参数便高达 1.458 亿(36 倍以上),最终取得了 82.7% 的精确度成绩。与此对应的是,市面的 GPU 内存仅仅提高了 3 倍左右,目前最先进的图像模型早已达到云 TPUv2 可用内存的极限。因此,我们迫切需要一种高效、可扩展的基础设施,以实现大规模的深度学习训练,并克服当前的加速器内存受限问题。
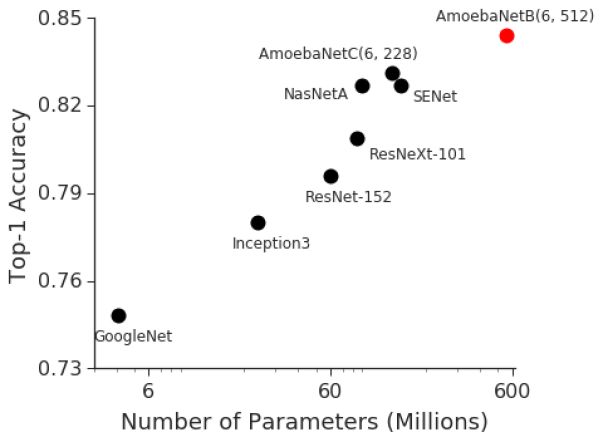
最具有代表性的图像分类模型体现出了 ImageNet 精确度结果与模型大小的强关联性
在《GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism》(https://arxiv.org/pdf/1811.06965.pdf)一文中,我们展示了如何通过流水并行技术(pipeline parallelism)对 DNN 的训练进行扩展以克服这一限制。简单来说,GPipe 是一款分布式机器学习库,基于同步随机梯度下降与流水并行技术进行模型训练,适用于由多个连续层组成的任意 DNN。最重要的是,GPipe 可以让研究员在不调整超参数的情况下,部署更多的加速器以训练大规模模型,由此有效扩展了性能。为了证明 GPipe 的能力,我们在 Google Cloud TPUv2s 上训练了一个具有 5.57 亿模型参数、 480 x 480 输入图像尺寸的 AmoebaNet-B。该模型在多个流行数据集上表现良好,取得的成就包括:single-crop ImageNet 的精确度提高至 84.3%、 CIFAR-10 的精确度提高至 99%、CIFAR-100 的精确度提高至 91.3%。
核心 GPipe 库已在 Lingvo 框架下进行开源:
https://github.com/tensorflow/lingvo/blob/master/lingvo/core/gpipe.py
从小批次至微批次
目前存在两种标准方法可以对中等规模的 DNN 模型进行加速。数据并行方法(The data parallelism)可以纳入更多的机器,并将输入的数据区分开来。另一种方法则是将模型置于加速器上(比如 GPU 或 TPU)——这些加速器的特殊硬件可加速模型的训练进程。然而加速器却面临着内存与主机通信带宽两方面受限的问题。因此,通过将模型进行分区,并根据分区配置相应的加速器,模型并行技术可以让我们在加速器上训练更大规模的 DNN 模型。由于 DNN 存在顺序性,这种策略最后可能变成计算期间只有一个加速器处于活跃状态,未能将加速器的计算能力充分利用起来。此外,标准的数据并行技术只允许在多个加速器上同时训练具有不同输入数据的相同模型,却无法提升加速器所能支持的最大模型规模。
为了实现跨加速器的高效训练,GPipe 先按照加速器对模型进行划分,然后自动将小批次的训练示例拆分为更小的微批次。通过在微批次中执行流水管理,加速器得以并行运行。此外,梯度将在微批次中持续累积,以免分区的数量影响到模型的质量。
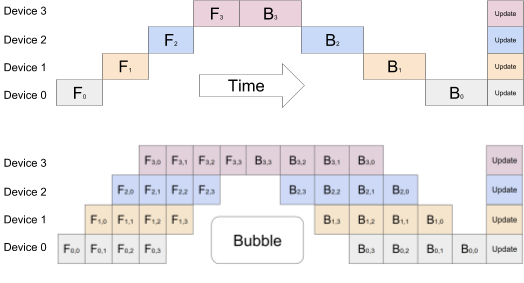
上图:由于网络存在顺序性,模型并行策略导致严重的利用不充分问题。 每次都只有一个加速器处于活动状态。
下图:GPipe 将输入的小批次拆成更小的微批次,使不同的加速器可以同时在单独的微批次上运作。
内存和效率的最大化
GPipe 会对模型参数的内存分配进行最大化处理。我们在每个 TPUv2 均配有 8 个加速器核心以及 64 GB 内存(每个加速器 8 GB)的云 TPUv2 上做了相关实验。如果没有 GPipe,由于内存的限制,单个加速器顶多只能训练 8200 万个模型参数。而通过反向传播以及批量分割技术进行重新计算的 GPipe ,成功将中间激活内存从 6.26 GB 减至 3.46GB,由此实现单个加速器上训练 3.18 亿个参数的成果。此外,我们还发现在流水并行技术的作用下,模型的最大规模与分区数量成正比,正如事前所预料的那样。总的来说,GPipe 使 AmoebaNet 能在云 TPUv2 的 8 个加速器上纳入 18 亿个参数,比起之前高出了 25 倍。
为了测试模型的效率,我们研究了 GPipe 对 AmoebaNet-D 模型吞吐量的影响情况。由于训练过程需要至少两个加速器以适应模型尺寸,因此我们只能对没有实施流水并行技术的两个分区案例的加速情况进行观察。我们发现训练过程存在近乎线性的加速效果。与两个分区案例相比,将模型分布在四倍数量的加速器上能有效实现 3.5 倍的加速效果。我们的实验均使用了云 TPUv2,但我们了解到最新的的云 TPUv3 由于每个 TPUv3 均配备了 16 个加速器核心以及 256 GB(每个加速器 16 GB),因此拥有更理想的表现性能。当我们在所有 16 个加速器上对模型进行分发,GPipe 能让基于 1024-token 句子的 80 亿参数 Transformer 语言模型的训练速度提高 11 倍。
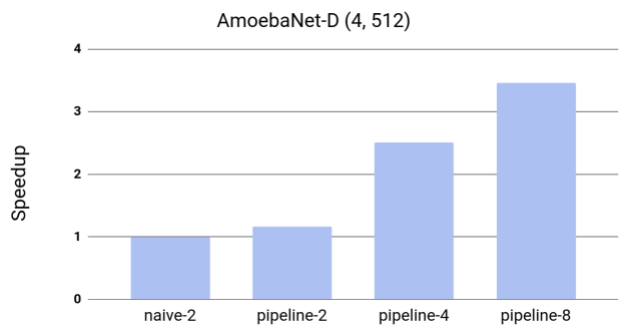
通过 GPipe 对 AmoebaNet-D 进行加速。这种模型不适用于单个加速器。naive-2 基线是将模型拆分为两个分区,最终取得的性能结果。Pipeline-k 对应的是 GPipe 将模型分成带有 k 个加速器的 k 个分区的最终性能结果。
在无需更改超参数的情况下,GPipe 还能通过使用更多加速器来扩展训练结果。因此,它可以与数据并行技术相结合,通过互补的方式使用更多的加速器来扩展神经网络的训练规模。
精准度测试
我们试图通过 GPipe 证明,对现有的神经网络进行扩展,可以实现更理想的模型质量。为此,我们在 ImageNet ILSVRC-2012 数据集上训练一个模型参数为 5.57 亿、输入图像尺寸为 480 x 480 的 AmoebaNet-B。该网络被分为 4 个分区,在模型与数据上执行了并行训练程序。该巨型模型在没有任何外部数据的情况下,最终达到了最先进的 84.3% top-1 / 97% top-5 的single-crop 验证准确度结果。这说明大型的神经网络不仅适用于 ImageNet 等数据集,还能通过迁移学习的方式作用于其他数据集。事实证明,更好的 ImageNet 模型拥有更理想的传输效果。我们在 CIFAR10 和 CIFAR100 数据集上进行了迁移学习实验。我们的巨型模型成功将 CIFAR-10 的精确度提高至到 99%、CIFAR-100 的精确度提高到 91.3%。
结论
当下许多机器学习应用(如自动驾驶和医学成像)得以持续发展并取得成功的原因,在于实现了尽可能高的模型精确度。然而这也意味着我们需要构建一个更大、更复杂的模型,我们很高兴能够为研究社区提供 GPipe,我们希望未来它可以成为高效训练大规模 DNN 的基础设施。
via https://ai.googleblog.com/2019/03/introducing-gpipe-open-source-library.html

点击阅读原文,查看 大规模机器学习框架的四重境界
