500万日订单下的高可用拼购系统,到底暗藏了什么“独门秘籍”?
零点提交订单峰值破 1 万 TPS,单日总订单量超 500 万,活跃用户数 200 万,苏宁 88 拼购日活动取得了丰硕的成果。

在大流量、高销量的背后,是我们近半年来付出的努力,针对拼购系统瞬时高并发能力的优化与升级,才能保证消费者丝滑顺畅的购物体验。下面就来介绍下苏宁拼购系统应对大促的术与道。
术为用:拼购系统高可用的架构设计
“术”是架构设计的方法论。拼购系统的架构历经多次更新和迭代,其目的是打造一个高可用、高性能、易扩展、可伸缩性强的应用系统。
将整个过程精炼出来,我们主要做了三个方面的工作:
系统架构优化设计
数据库性能的优化
应用高可用的优化
系统架构优化设计
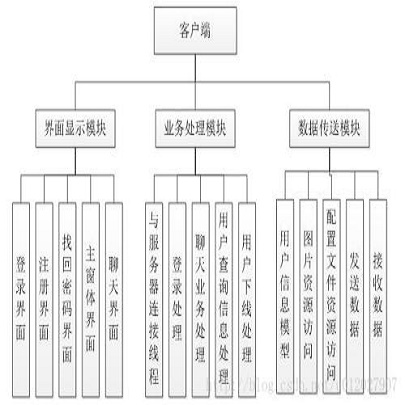
根据康威定律,组织形式等同系统设计。拼购系统之前为了满足快速的开发迭代节奏,所有功能是放在一个集群中的。
随着业务的发展,功能越来越复杂,单一集群已经成为限制系统性能的最大瓶颈。
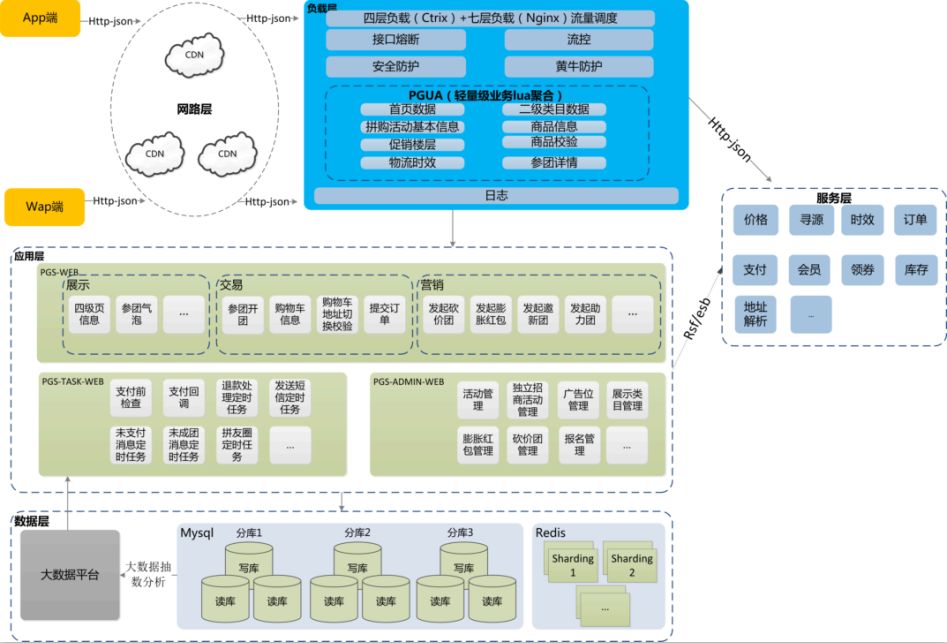
图 1:苏宁拼购系统架构设计
因此,系统优化所做的第一件事情就是对拼购系统架构进行了重构。一方面,进行横向切分,将系统分层,包括:
网络层:通过 CDN 加速响应。一方面 CDN 缓存提高静态内容访问速度,减少服务端压力;另一方面,CDN 内部网络专线,加快回源速度。
负载层:包括四层负载和七层负载。功能包括流量调度、流量控制、安全防护、黄牛防护等,另外在负载层也做了一些轻量级业务的 Lua 聚合,以提高响应性能。
应用层:这层主要实现业务功能逻辑。
服务层:为应用层提供原子服务,如会员、领券、寻源、时效、生成订单、支付等。
数据层:提供数据存储访问服务,如数据库、缓存等;提供数据抽取分析服务,如 Hbase、Hive。
另一方面,针对拼购的业务特性,进行纵向切分,将原来耦合的功能逻辑拆分为三层:PGS-WEB、PGS-TASK-WEB、PGS-ADMIN_WEB。
每个模块独立集群部署,集群之间通过分布式远程调用与服务层提供的原子服务协同工作。其中:
PGS-WEB:前台业务处理模块。包括展示、交易、营销三个单元模块。每个模块又能分割为更小粒度的子模块。
比如营销模块就又能细分为四个轻量级玩法模块:邀新团、砍价团、膨胀红包和助力团,可以针对业务需要,对不同模块进行拔插、拆分和扩展。
PGS-TASK-WEB:中台定时任务处理模块,主要用于处理定时任务,另外支付逻辑也在这一层。
PGS-ADMIN_WEB:后台管理模块,主要用于运营人员维护活动、商品、玩法等。
数据库性能优化
在高并发场景下,提交订单、生成拼团记录、查询订单等操作,会对数据库造成很大压力,而这些一致性要求高的操作又不能直接使用分布式缓存替代数据库。
而给数据库降温,提高数据库的并发处理能力,必须让数据库具备横向扩展能力。因此我们基于 Mycat 数据库中间件实现了拼购系统数据库的分库分表策略。
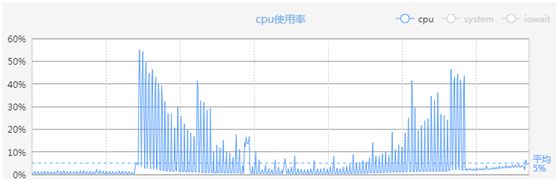
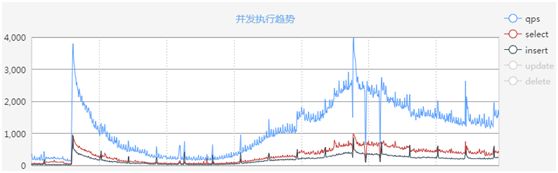
图 2:高并发场景下 MySQL 数据库负载能力趋势
Mycat 是 MySQL 分库分表中间件,和 Web 服务器的 Nginx 类似,是应用与数据库之间的代理层。
由于 Mycat 是开源中间件,这里对技术实现不做阐述,主要讲下它在拼购系统下是如何应用的。
如下图所示,业务逻辑的数据操作通过 Mycat 分为三个库 DataNode 1~3,这个分库过程应用本身是无感知的。
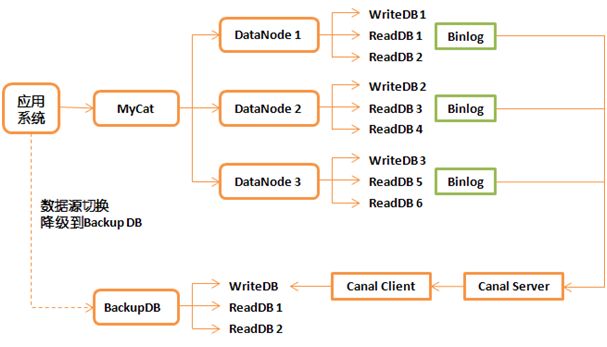
图 3:苏宁拼购系统基于 Mycat 的分库架构
每个库一写两读,针对团和团详情的操作分片规则基于团 ID(GROUP_ID),针对订单的操作分片规则基于订单 ID(ORDER_ID)。
另外,还有一个单独的 BackupDB 用于大数据抽取和数据备份,通过 Canal 保证 BackupDB 中是全量数据。
当 Mycat 出现问题时,我们可以通过应用层的数据源切换,降级为单库,保证业务。
应用高可用优化
对于应用层面的优化,主要包括分布式缓存和异步化两方面。
利用 Redis 分布式锁解决并发场景一致性问题
比如为了防止订单被重复处理,我们使用 Jedis 的事务 Transaction + SETNX 命令来实现 Redis 分布式锁:
Transaction transaction = jedis.multi();//返回一个事务控制对象
transaction.setnx(tmpLockKey, "lock");//Set if Not Exist
transaction.expire(tmpLockKey, locktime);
List<Object> rets = transaction.exec();//事务执行
利用 Redis 实现活动库存,解决数据库资源竞争问题
对于每一个拼团活动,我们是维护了活动库存的,或者叫做资格/剩余数,并非真正的实际库存。
在 1 元秒杀等活动中,这个活动库存的变化会很迅速,大量数据库 UpDate 操作,造成行锁非常影响系统吞吐率。
优化方案是 在Redis 中做活动库存扣减,并以一定周期同步给数据库:
/**
* Redis缓存扣减活动库存
* */
private Long updateStoreByRedis(String actId, String field, int count) {
String key = redis.key(PGS_STORE_INFO, actId);
// 如果活动库存缓存信息存在,则更新对应field的数量
if (!redis.exists(key)) {
// 从数据库读取该活动库存信息并初始化到redis
ActivityStoreEntity entity = queryStoreInfoFromDb(actId);
if (entity == null) {
return -1L;
}
Map<String, String> values = new HashMap<String, String>();
values.put(PGS_STORE_ALL,…);
values.put(PGS_STORE_REMAIN, …);
values.put(PGS_STORE_LOCK, …)
redis.hmset(key, values);
// 若活动有效期内库存缓存信息失效,初始化缓存信息一小时
redis.expire(key, ONE_HOUR);
}
return redis.hincrby(key, field, count);
}
/**
* Redis同步活动库存给数据库
* */
public int syncActivityStoreToDB(String actId) {
…
try {
// 判断同步锁状态
String key = redis.key(PGS_STORE_SYNC, actId);
if(!redis.exists(key)){
更新活动可被锁库存数量
redis.setex(key, actId,STORE_SYNC_TIME);
}
}
} catch (Exception e) {
Log;
}
…
}
异步化操作,消除并发访问高峰
比如支付完成后,有一系列的后续处理流程,包括活动库存扣减、拼团状态变更等,其中有些逻辑实时性要求高,要同步处理。
有些则可以通过异步化的方式来处理,像通知物流发货。我们采用 Kafka 队列来进行异步通信,让下游系统进行消费处理。
道为体:拼购系统高并发下的保障体系
“以道驭术,术必成。离道之术,术必衰。”我们所有的架构优化与升级最终目的是为了保障促销高峰的稳定性。
拼购系统高并发场景下的保障之道,是以合理的容量规划为基础,全面覆盖的监控体系为支撑,形成的完善的限流+降级+防控策略。
全链路压测与容量规划
根据业务预估量,生产环境针对苏宁拼购全链路场景的压测,才能做出合理的容量规划。
目前,我们的压测系统,可以支持引流压测,即将线上真实流量复制下来,生成脚本,进行压测。最大程度保证了压测和真实情况的一致性,从而使容量规划更精确。
端到端覆盖的监控体系
目前苏宁拼购的监控体系能够做到端到端的覆盖,包括客户端->网络->服务端的监控。
其中,客户端监控依赖于覆盖 PC + WAP + App 的终端日志。网络监控主要是 CDN 日志和拨测数据。
服务端监控手段最为丰富,包括:
服务器系统状态监控:CPU、内存使用率、网卡流量、磁盘 IO 等。
Web 服务器监控:实时展现 Web 服务器的 Http 连接数、响应时间、Http 异常、状态码等指标。
应用服务器异常监控:实时汇总应用异常堆栈信息。
JVM 状态监控:实时展现JVM的内存、线程、GC 和 Class 的使用状况。
NoSQL 监控:Redis 每分钟命令数、大对象、连通性等的监控。
数据库监控:数据库层面各项指标监控。
调用链监控:实时展现应用间调用关系,反馈链路系统健康状况。
这些监控系统通过 traceId 相串联,与基础运维平台打通,最终通过决策分析平台聚合,实现智能告警。
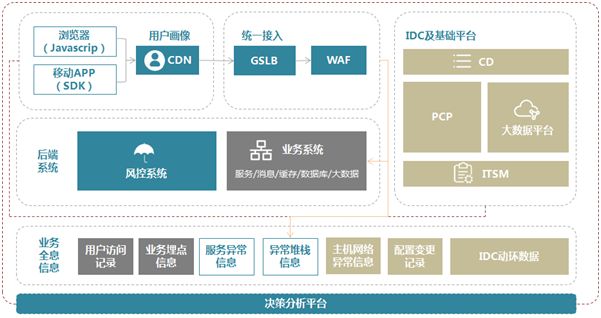
图 4:端到端监控体系与告警决策平台
流量控制与风险控制
流量控制是针对 88 拼购日零点峰值疯狂流量超出预期,所设置的限流,以保护好自身应用,否则出现雪崩式连锁反应。
目前拼购的流控系统可以支持多个维度的流控策略。包括最基础的 JVM 活跃线程数流控,针对用户 IP、UA 和会员编号的限流,针对核心接口的限流策略,针对爆款商品的限流策略等等。
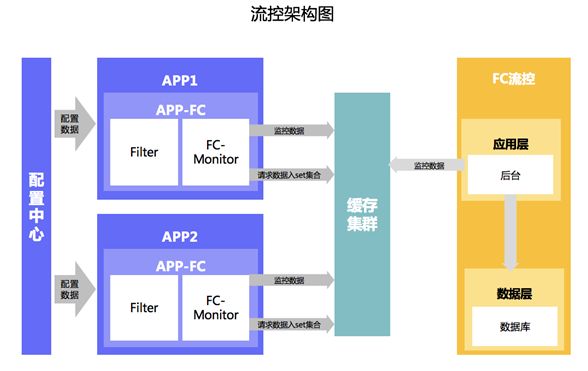
图 5:拼购流控系统架构
风险控制是针对 88 拼购日爆款商品被黄牛刷单风险的防控策略。除了传统的黄牛库名单,拼购的风控策略包括对用户、地址、事件行为、设备指纹等的判断。
区别于非黑即白的防控,拼购采用打分的方式对用户进行画像,对潜在的风险用户采取短信验证、滑动验证、人脸识别等一些列挑战模式。
大促准备与应急预案
大促准备工作是指结合业务的促销节奏,梳理的一系列大促准备工作,包括非核心定时任务的提前降级、生产操作权限的回收等。
应急预案是针对大促可能发生的突发性事件梳理的预案,应急预案是建立在降级手段的基础上的。
比如关键时候对部分功能的降级关闭操作,弃车保帅,保障购物流程的正常;再比如针对服务器性能瓶颈的降温手段,只有在准备好应对一切突发情况的前提下,才能保证每次大促的顺利完成。
结束语
路漫漫其修远兮,今年的 88 苏宁拼购日已经告一段落。未来向我们提出了更多的挑战与机遇。
如何进一步突破系统性能瓶颈,如何给用户提供个性化的推荐与服务,如何将拼购做成一个开放的社交化电商平台,苏宁拼购技术团队要做的工作仍然有很多。
我们将继续前行,势不可挡,并为大家带来持续的技术分享与更新。
作者:朱羿全、任章雄、张涛、龚召忠
简介:朱羿全,南京航空航天大学硕士研究生毕业,苏宁易购消费者研发中心高级技术经理,主要负责易购各系统架构优化与大促保障工作。先后参与了易购整站 Https 改造、苏宁拼购架构改造、先知业务监控平台建设等工作。专注于打造高可靠、高性能、高并发服务系统的技术研究。
编辑:陶家龙、孙淑娟
投稿:有投稿、寻求报道意向技术人请联络 editor@51cto.com

精彩文章推荐: