情感识别科技作为当前人工智能的一个重要研究领域,其发展迅速,已经在家庭陪伴、公共安全、心理咨询、教育、商务等多个领域中得到了诸多应用。但是情感识别的发展目前仍然面临各种问题。
2022年7月30日下午,由中国图象图形学学会(CSIG)主办,CSIG情感计算与理解专委会、北京大学计算机学院情感智能机器人实验室承办,浙江蓝景科技有限公司、北京计算机学会机器人情感计算专委会、北京大学信息技术高等研究院情感智能机器人实验室协办的“当前情感识别科技发展的究竟怎么样?”线上沙龙成功举办。
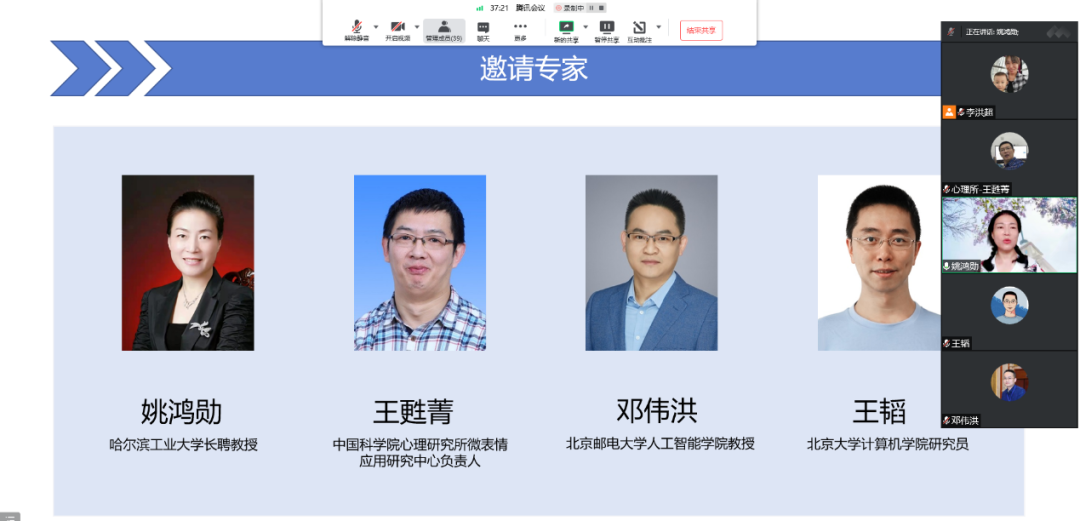
沙龙邀请了哈尔滨工业大学长聘教授姚鸿勋老师、中国科学院心理研究所微表情应用研究中心负责人王甦菁老师、北京邮电大学人工智能学院教授邓伟洪老师和北京大学计算机学院研究员王韬老师四位专家,与观众一起围绕情感识别科技相关话题进行了深入探讨。沙龙分为专家发言和自由讨论两个部分。
在专家发言环节,专家们针对以下几个问题发表了自己的观点:
问题一:情感计算现在发展的真正水平如何?是像某些宣传那样可以用在日常生活中?还需要哪些地方需要提高?
姚老师首先表示情感计算领域在大的研究框架下属于一个分支,需要其他领域的专家帮助进一步发展,总而言之还有很长的路要走。
王甦菁老师认为情感计算中微表情的应用可能距离现实生活比较遥远,但是在国家安全层面具有巨大的应用潜力。微表情的研究还需要较长时间的积累才能真正地走向应用层面。
邓老师认为情感计算不是仅仅依靠数据驱动就能解决的任务,而是需要交叉学科的研究。一旦情感计算走向广泛应用,将给人类带来很大的好处。
王韬老师最后表示情感识别热度越来越高,大家认为情感计算的研究越来越重要。现阶段的情感计算技术能够提取不同时刻的情感相关特征,但是,如果情感计算想要走向应用层面,应当具有在一段时间内综合获取特征信息进行推理内在情感的能力,实现这样的能力需要多领域的专家共同努力。
问题二:情感计算较其他人工智能方向,相对起步晚一些,我们还要遵循重复其他方向的一贯研究做法吗?还是另辟蹊径,从人类脑科学、神经科学的感知模型出发,研究全新的具有推理能力、可产生智能的人工智能?
姚老师认为一方面,我们愿意相信主要由统计学带来的,大数据支持下的第三波人工智能高潮,能实现很多、很强的功能。但另一方面,有些研究者担心,数据驱动的研究范式进行推理的效率比较低。总体来说,目前情感计算应用层面工作的效率很低,也谈不上智能。如果我们只有数据是没法给出答案的,需要推出全新的机制解释情绪的走向,要摆脱受限于大数据的框架。
王甦菁老师提出我们应当“近水楼台先得月”,引用心理学领域最新的研究成果到情感计算的领域中。但实际研究中遇到的问题是,心理学研究的目标和计算机学科的目标产生了一些矛盾,有时心理学研究范式下产生的结果无法应用到计算机算法中,反之,计算机领域的研究者也很难深刻地理解心理学的研究理论。
邓老师表示跨学科的研究范式听起来很美好,但是目前最成功的研究仍然基于数据驱动。考虑到科研的现实环境,我们需要渐进式的驱动,我们需要不断吸收脑科学等其他学科的观点来逐步发展情感计算的研究范式。
王韬老师认为长期的发展目标和短期的研究现实需要协同考虑。对于研究者来说,如果有时间,还需要对建模认真研究,而不是对相关领域的原理仅仅是一知半解就展开研究。
问题三:现在数据驱动的机器学习研究方法很热,情感计算可以用这种研究方法解决哪些方面的问题,不能解决哪些方面的问题?
姚老师提到情感计算可以从应用层面推进问题的解决,应用导向研究可能会开启一个新的范式,其作为牵引可以是一个更强有力的研究推动力。情感计算可以解决的问题可以提高到从情感层面对人类的满足(比如自闭症、孤独症的应用)。情感计算未来可以提出类似”元宇宙“的概念级服务,为整个领域带来全新的发展角度。
王甦菁老师表示,应用是对科技驱动最大的力量。举例来说,二战中由于应用的需要导致导弹、原子弹相关的学科飞速发展。另外的一个例子是情感计算在游戏级别的应用:玩家们在玩各种网络游戏的时候,能否让玩家打开摄像头,利用摄像头对玩家情感的分析,给其他玩家带来一些辅助。
邓老师认为如果数据可以准确标注,它将对应用带来较大作用。如果数据较难标注或无法准确标注,对应用的发挥将比较局限。学术界能接触到的数据量相对较少,尤其是多模态、多传感器的数据。情感计算的研究仅在数据层面上,距离无约束的情感识别应用还有一段距离。同时,数据共享问题和数据的采集流程在硬件领域等不同层面的实现都会给数据驱动的研究带来问题。
针对邓老师说到的数据共享和数据收集,王韬老师提到在实际研究中,有时候会遇到很多数据收集方面的问题,提出是否情感计算的研究者们可以共同建立一个数据平台?
邓老师认为较为小众的领域下的数据收集是一个问题,比如医院等场景内的罕见症状的数据由于隐私保护等问题很难公开。
王甦菁老师同时表示数据脱敏的关键在于去除身份信息。实践中采用的一个方案可以是用PCA提取信息,把人脸视频信息分为身份和微表情信息。因此,我们可以制定一个标准,让各个医院采集符合标准的数据,然后聚集到一起,最终可能就会整合成为比较大的数据集合。
问题四:目前研究者认为面部表情并不能真实反映内在情感,情感的表达涉及许多物理变化(如语音、视线、生理指标),那么哪些模态的信息对于获取内在情感状态是更为有效的呢?如何利用多种模态的信息有效识别情感?或者如何建立一个更有效的多模态识别情感算法?
王甦菁老师表明微表情的识别研究有数据量特别小的特点,因此我们会同时采多个模态提高数据量和识别率。最近,我们提出了深度微表情学习的数据库,已经将其发表。由此,我们更进一步地想到,我们能否对表情进行自动标注,以及还有没有其他模态可以用于辅助识别?现在我们在做的是采用脸部肌肉电信号估计肌肉的运动状态,从而提供微表情的多模态信号。我们知道,内在的情绪和情感的外部表达往往是不一致的(笑里藏刀),而人的微表情往往能真正体现真正的情感。尽管这么说,但是微表情和内在情绪的直接相关性还是一个假说,需要进一步的研究。
邓老师阐述了表情本身是高度个性化的东西。如果元宇宙在应用中需要情感识别,也需要多模态的输入。目前,多模态学习已经成为各个研究领域的大趋势。对于情感识别,我们需要的模态或许更多更复杂,并且其中没有一个是完全有主导性的。在实际应用场景,真正的主导模态不是固定的,而是需要根据场景来判断。在多模态情感计算的研究中,我们可以借鉴多模态大模型的研究,或许可以为情感计算带来新的机遇。同时,还有一个比较大的挑战在于多模态数据的采集和标注。
王韬老师认为多模态的研究要求对单模态研究的精通,如果对单模态的理解不够深入的话,多模态的研究将浮于表面,变为若干单模态的线性组合。
姚老师指出面部的表情不能完全反映人的真实情感,情感识别不等于表情识别。多模态是可以解决问题的一个好方法。另一个角度来说,多模态识别的研究对研究者来说比较容易出文章,从而激发更多的新的idea,推进学术界的研究。
问题五:在现实生活中人的情感表达往往无法用某个词汇概括,在某一时刻表达出的情感是复杂而多样的。有研究者认为情感并不存在多个类别的理想定义,多样性而非一致性才是情感的特点,对于情感识别来说,哪些情感是易于概括并识别的,能够做到尽可能覆盖人类所有可能情感吗?
邓老师介绍说,五六年前我们做过一个实验:邀请四十个学生用六类基本表情标注网络上找到的复杂表情图片,结果表明,对于同一张图片不同人标注的表情不完全相同,表明了心理学中的复合表情现象。仅仅是表情这种表面化的表达形式,都出现了复杂的表现形式,因此我们认为很多时候情感应当用一个连续的而不是离散的空间表达。但是,实际中使用离散空间标注的情形是为了标注的准确度,如果采用连续的空间标注将带来更大的不一致性。
王韬老师认为离散的标注不尽准确,而连续的隐空间表示又给标注带来了困难。
姚老师说在研究中,我们可以在标注时对于某个画面允许多类别的同时标注存在。多样性而非一致性确实是情感的特点。因而,多模态是对情感认知的自然解决方案。
王甦菁老师介绍,“喜极而泣”:高兴的情绪到了极端的时候,会表现出来悲伤的表情,这体现了表情和内心的情绪不一致的问题。脑瘫患者的肌肉张力比正常人高得多,这导致脑瘫患者和一般人在同样表情的表达上有很大的差距。同时,环境因素也会影响情感的表达,比如,我(脑瘫患者)在本届冬残奥会上举火炬的时候由于吃力影响了喜悦心情的表情表达。
问题六:假设目前的技术能够比较准确地识别人的外在表达形式(如笑和哭),但不同的个体表达情感的方式是存在差异的(有的人表达情感比较含蓄,有的人有与众不同的表达习惯),我们应当如何更准确地识别不同个体的想要表达的真正情感呢?
王韬老师认为人对情感表达的判断的流程首先存在一个通用的模型,在人与人交往中会不断调整,针对不同的人形成个性化模型。因此,我们或许可以参考强化学习的范式,在研究中进行个性化的学习。
姚老师表示,从训练模型的角度考虑,当样本有差异的时候,我们会考虑添加更多的补充样本,可以通过生成等技术对特异性样本的识别率进行提升。
王甦菁老师则表示同意个性化学习和强化学习的发展路线。学生们和我(脑瘫患者)交流的时候,最开始听不懂我的表达,当交流的时间变长了,他们会认为我的讲话越来越清楚。
邓老师认为让机器具有自适应学习的能力(迁移学习、增量学习)是我们未来的研究方向。
在自由讨论环节,观众提出问题:有标准的AU数据标注中如何处理个体的差异?
王韬老师表达了在标注过程中,我们首先应该建立通用的推理模型。对于特异性的个体标注过程中,如果只有一个样本,我们直接采用通用模型进行标注(实际上,人类对于陌生人也无法快速建立个性化的识别效果)。在标注样本增加的过程中,我们可以引入反馈对不同个体建立个性化的模型。
邓老师认为从数据驱动的角度考虑,只要数据量足够,可以有用于表达个体差异的维度存在,从而处理个体差异。
王甦菁老师指出如果我们不能对每个人进行个性化的学习,或许也可以对一类人进行个性化模型建立,首先判断每个个体属于哪种类型的“人格”,再进行进一步推理。
姚老师表示认同各位老师的观点,同时我们也可以通过应用导向来牵引对个体差异的研究。
最后,姚老师对本次沙龙做了总结,并表示希望下次能有更多的机会与观众一起探讨问题,在思想上碰撞出更多的火花。希望通过本次沙龙讨论,为情感识别科技未来的发展提供指导方向。
![]()