无标注数据是鸡肋还是宝藏?阿里工程师这样用它

阿里妹导读:针对业务场景中标注数据不足、大量的无标注数据又难以有效利用的问题,我们提出了一种面向行为序列数据的深度学习风控算法 Auto Risk,提出通过代理任务从无标注数据中学习通用的特征表示。这种思想与目前 NLP 领域前沿的 Bert 等预训练模型不谋而合,但是由于行为序列数据和业务的特点显著区别于 NLP,模型的设计和实现又有很大区别。最终,模型在真实场景中落地并取得了显著的增益;实验验证具有较好的多场景泛化能力;相比纯粹的监督学习,在小样本情况下提升明显。

一、背景
行为序列数据,如淘宝购物,支付宝风控事件等,在内部场景十分常见,也是推荐、风控等问题的源头级输入之一。给定一个用户的交易序列,要求预测他接下来会买什么;给定风控事件序列,要求预测是好人还是黑产,都依赖于将行为序列表示成特征向量,进而实现序列分类的基础能力。
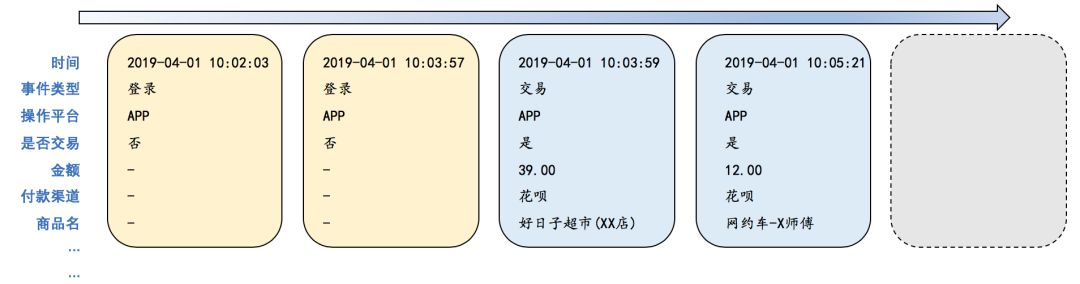
行为序列示意图
传统方法是依据人工经验设计大量的触发、累积等特征,在此基础上训练 GBDT 等分类器。近年来,一个较为成功的方向是使用 RNN、CNN、Attention 等神经网络,直接以原始行为序列作为输入,输出分类结果或者特征向量。这种方法充分发挥 Everything-to-Vector 的思想,避免了繁琐的人工特征工程。例如,我们团队提出的 Detail Risk 框架,将一个用户的行为序列经过离散字段 embedding、文本卷积、多字段融合、事件卷积、Attention 等多层网络,最终转化为分类向量,在等多个场景落地,大量减少了人工工作,同时提高了模型效果。
Detail Risk 框架示意图
美中不足的是,这类方法大多是监督学习,label 样本不足的阴影始终挥之不去:少量样本无法真正发挥神经网络模型容量大的优势;引入 multi task label 辅助又要仔细权衡各个 task 之间的迁移能力,容易按下葫芦起了瓢。
而在另一方面,我们的业务中积累了堪称海量的未标注数据,如果能利用这些未标注数据训练模型,学习通用的高层特征,而将有限的 label 留给下游场景训练一个简单的分类器,将会极大地提高数据的使用率;另外,这些无监督产生的特征向量和人工设计的特征完全不同,融合后更容易取得效果提升。
二、预训练
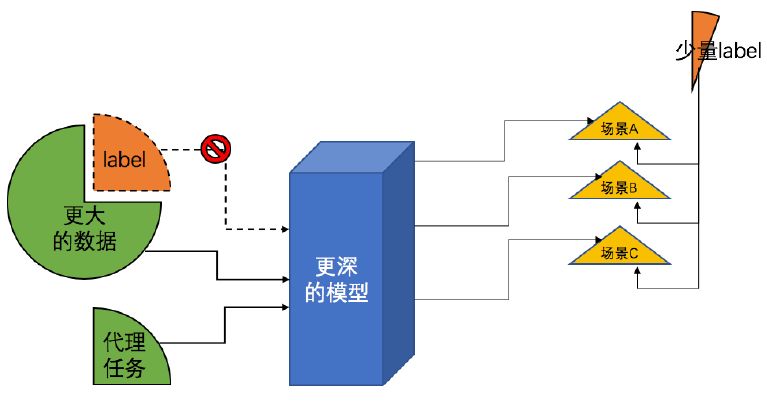
相同的问题并非只发生在内部业务中,更加本源性的 NLP 研究从去年开始揭示了一条解决之道:Pretrain (预训练)技术——利用随手可得、但是蕴含知识的代理任务+大量的未标注数据+更深的网络,让模型自动学到有效的高层特征,在下游任务中稍加 finetune 即可取得很好的效果。进入2018年之后,ELMo、GPT、BERT、GPT2、 ERNIE 等预训练模型一遍又一遍地刷新了 NLP 各个基础问题的 SOTA,大有长江后浪推前浪之势。其中 BERT 更是一举刷新11项记录,同时也刷爆了算法工程师的朋友圈。
与训练原理示意图
在 CV 领域,使用 imagenet 预训练的大型网络可以追溯到深度学习的寒武纪时代——2014年;在 NLP 领域,使用 word2vec 或者 glove 预训练的词向量也是常规做法。但是,预训练一个像 Bert 这样大型的、能够显著提高下游任务效果的、还不使用 label样本的模型,却直到最近才爆发。作者认为是4个前置条件的达成解锁了这个科技。
代理任务的积累:代理任务并非随便选择,从简单的 Cbow 和 SkipGram,最终到 Masked-LM、NSP,代理任务越来越难,也越来越能抓住高层抽象知识,这是 Pretrain 的关键。
深层网络:越是深层的、大容量的网络,越能抽取高层的特征、存储更丰富的知识。ResNet、各种 Norm 技术、乃至 SBBB(ShortCut、BottleNeck、Branches、BatchNorm)这类构造模式的出现让深层网络的搭建和训练变得简单。
Attention:把 Attention 单独拎出来提并不过分。可以说它为神经网络提供了专门的 memory,以及各种基于 memory access 的功能:对齐、组合、远程依赖、全局视野等,极大丰富了模型的表示能力。这一点在我们关心的序列数据上尤为明显。
CNN 流崛起:相比 RNN,CNN 原本并非为序列数据设计,但是它天生易并行,对工业应用友好;易堆叠,适合做深层模型;欠缺的全局视野留给 Attention 去完成。本质上,Transformer 也属于 CNN 流:宽度为1的卷积核加上 Self-Attention。最近两年来,ConvS2S,ByteNet,WaveNet,SliceNet,Transfomer 等各种 CNN 流的工业级框架,正在逐步占领曾经属于 RNN 的天下。
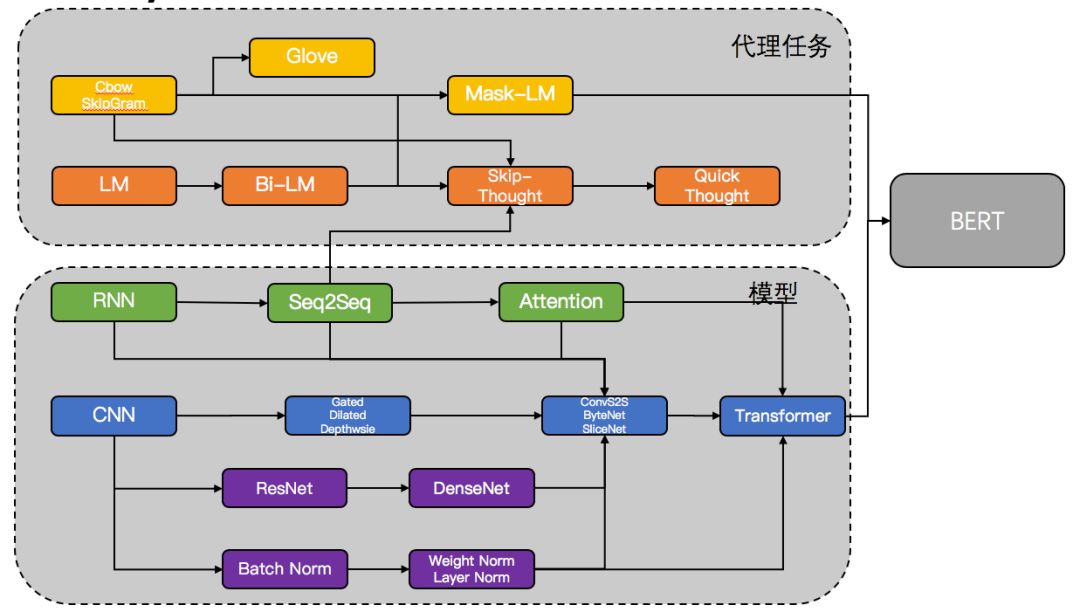
预训练模型 Bert 所依赖的科技树
三、问题分析
目前,内部一些 NLP 产品已经率先用上了 BERT,但是在 NLP 之外的领域目前还未见获益。究其原因主要有:
1. 数据形式不同。风控、推荐等场景里的数据不是文本,而是行为序列。这不仅导致了谷歌提供的预训练参数不可用,更要求我们的模型去适配以下的数据特点:在每个时刻T 都有着多个输入字段、字段之间模态不同、序列长度巨大,没有天然存在的句子分隔,等等。
2. 训练开销巨大。这些专为 NLP 问题设计的模型,走的都是重型武器的路子:单层1600万参数的 Transformer,先来个十几二十层,整体参数2亿起;显存杀手 Self-Attention,在输入序列长度超过1000时单层就会导致 OOM(Out-Of-Memory);即便显存烧得起,收敛速度也很慢,8台最新的 GPU,训练时间也要以月计。为了解决自然语言中复杂的 parsing 和 composing 问题这样做是值得的,但是对行为序列数据来说,显得有些浪费。
因此,要享受预训练的好处,我们还需要另起炉灶,根据数据和业务特点,设计并实现自己的 Pretrain 模型。本文正是基于这种背景,设计并实现了一套行为序列无监督 Pretrain 框架,同时在实际业务落地中验证了其有效性。由于我们的业务场景是风控,因此将其称作 Auto Risk 模型。
四、模型设计
4.1 代理任务
预训练模型不需要任何实际任务的 label,但是需要随手可得的代理任务来驱动训练。代理任务的设计完全决定了模型会挖掘什么样的知识。我们将行为序列数据和文本进行类比,将每个时刻t看成一个词,每个连续序列1:T看成一个文档,那么类似于 BERT,我们也设计了两类代理任务:
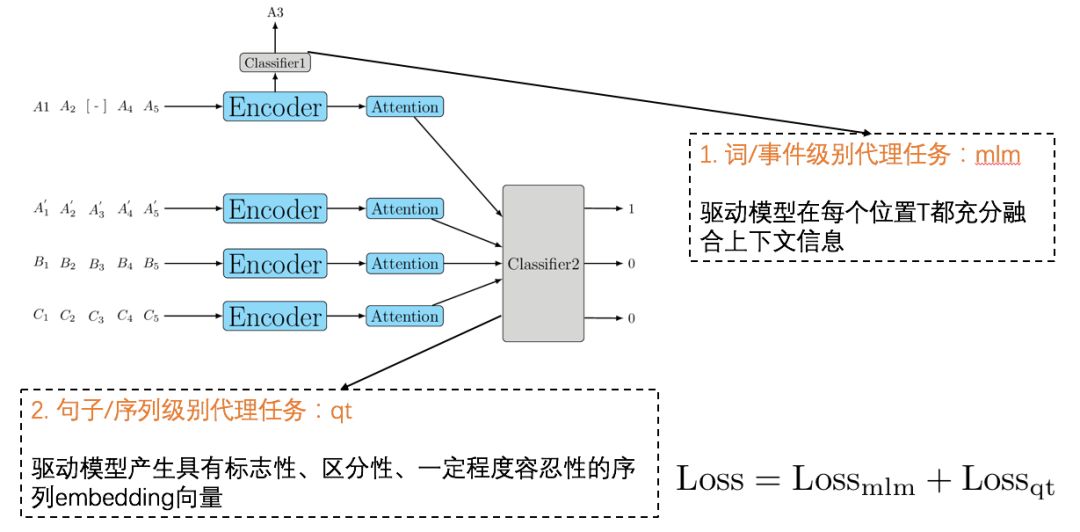
两类代理任务
词/事件级别的代理任务 Masked Language Model。我们掩盖输入序列在某个时刻 t 处的值,要求模型在t处输出的词级别向量能预测被掩盖的值。显然这个任务会驱动模型去挖掘序列前后的关联,将行为放到上下文中考察。
句子/序列级别的代理任务 Quick Thought。我们通过采样把每个序列都分割成前后两个子序列,使用孪生网络对两个子序列分别编码为一个向量,再把 batch 内的子序列们两两随机组合,要求模型预测组合后的 pair 是否同源。这个方法最早来自 Skip Gram 的句子级别泛化——Skip Thought,而后将其中运行较慢的Encoder-Decoder 换成速度更快的孪生网络,因此称作 Quick Thought。显然,qt 任务会驱动网络去挖掘序列的标志性特点。
4.2 网络结构
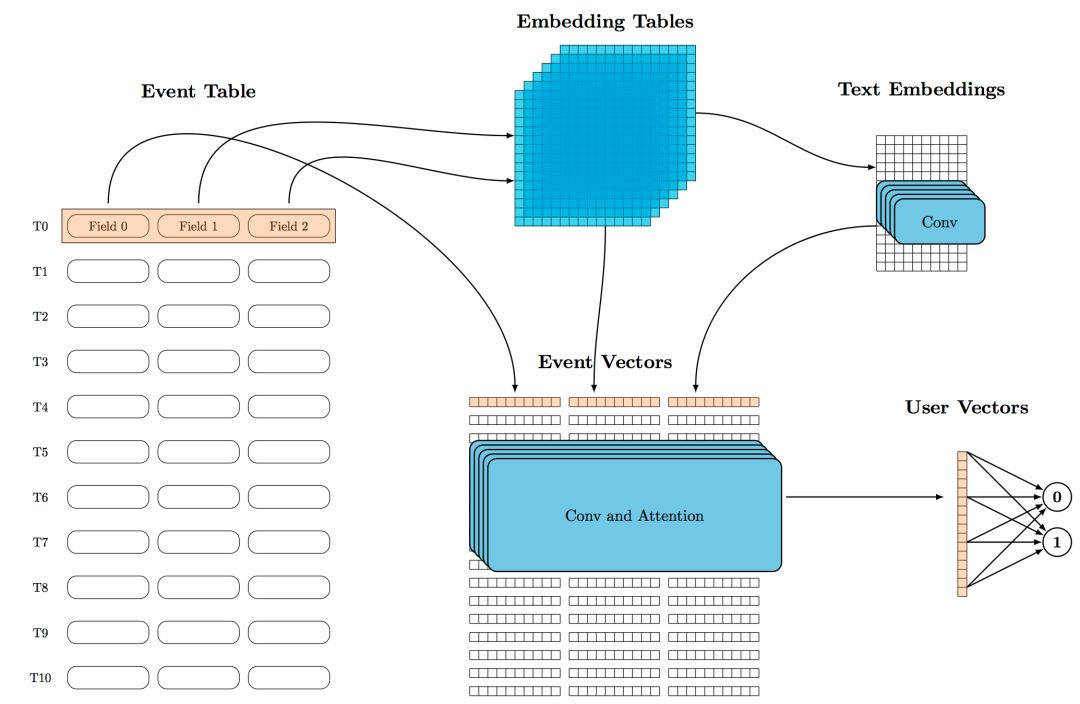
代理任务提供了随手可得的 label,具体模型结构的核心则是 Encoder 网络。根据笔者在第二、三章的分析,像 BERT、GPT 那样直接使用重型武器 Transformer 是非常低效的。我们提出了一个更加高效的基于卷积和注意力的 Encoder 结构:
Embedding 层,用于把输入字段向量化,例如事件类型、时间、金额、付款渠道、商品名等不同字段,统统 embedding 表示,然后通过 Add 或者 Concat 融合;其中文本字段是 List 形式,不仅要 Embedding,还要通过卷积或者 Average 等方式汇总成单个向量。
Convolution 层,负责抓取局部上下文,我们假设这是行为序列的主要特征(在风控场景中),要做得准确、高效;
Attention 层,负责抓取全局上下文,我们假设这是行为序列的次要特征(在风控场景中),重要的是提供额外的视野和能力;
一个 Convolution 层和一个 Attention 层组成一个 Block,使用 ResNet 的形式叠加多个这样的 Block 形成一个 Encoder,就如同叠加多个 Transformer 形成一个 BERT 一样,能够帮我们实现信息的抽象、整合。
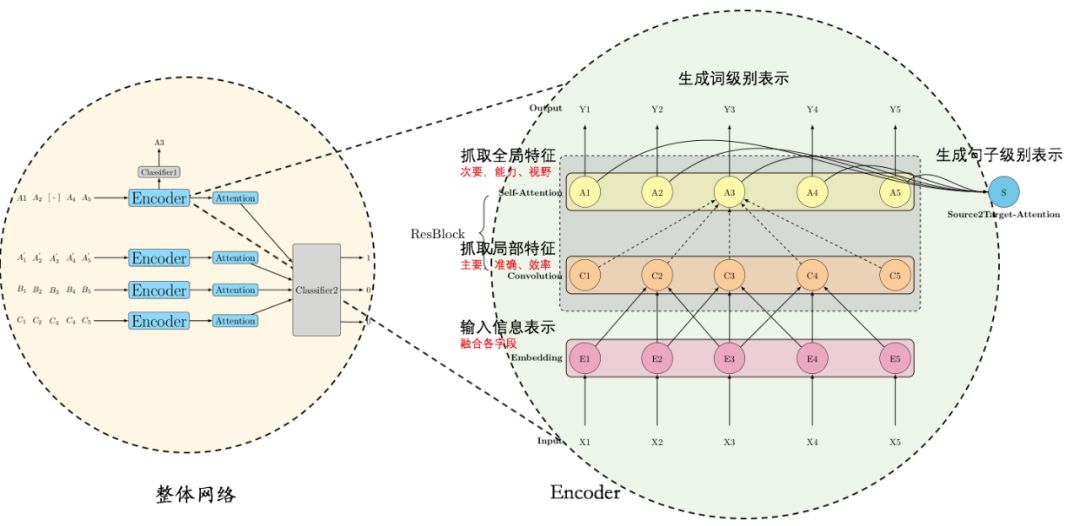
Auto Risk 模型结构示意图
■ 4.2.1 Convolution 层改进
Convolution 用于序列时,需要叠加多层以增大视野,这就带来了两个副作用:1.梯度弥散,优化变难,2.参数和计算量巨增。为了解决这两个问题,我们结合两类特殊的卷积以替代一般卷积:Gated Conv 和 Depthwise Separable Conv。首先使用与 LSTM 类似的门机制来抑制梯度弥散问题,可以叠更多的层数;再将一次卷积分解成depthwise 和 pointwise 两步,使得参数量和计算量都从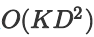
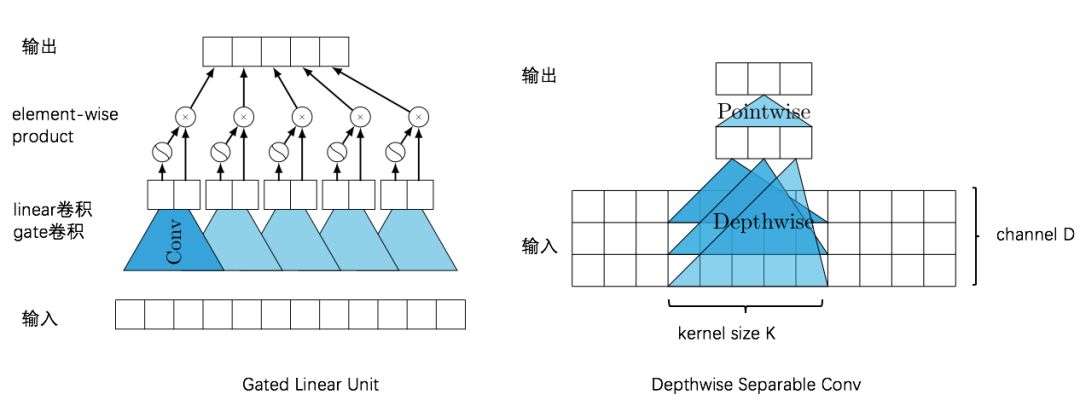
卷积改进
■ 4.2.2 Attention 层改进
Attention 带来了优秀的视野和能力,但代价是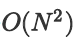
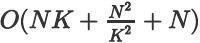
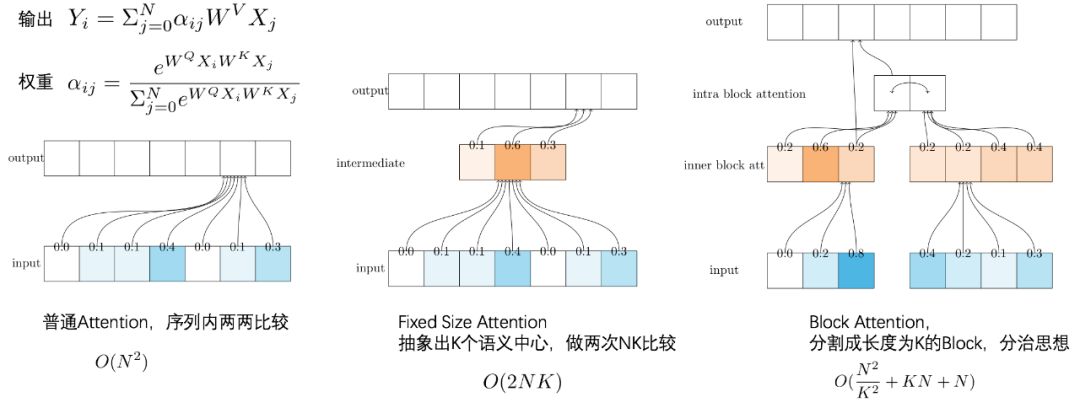
注意力改进
要训练一个这样的大型网络,还有很多 trick 要用到,本篇不再赘述,后续由系列文章分享。
4.3 训练
经过以上一系列优化,我们最终仅用一张显卡实现:
在长度4000的序列上训练3层 Encoder 叠加的网络,而基于 Transformer 的 Bert 模型最多只能在1000以内的序列上训练一层网络。
2~3倍于 Transformer 的 batch 训练速度(序列越长越显著)和更少的收敛步数,一天之内就可以完成千万级别数据的训练。
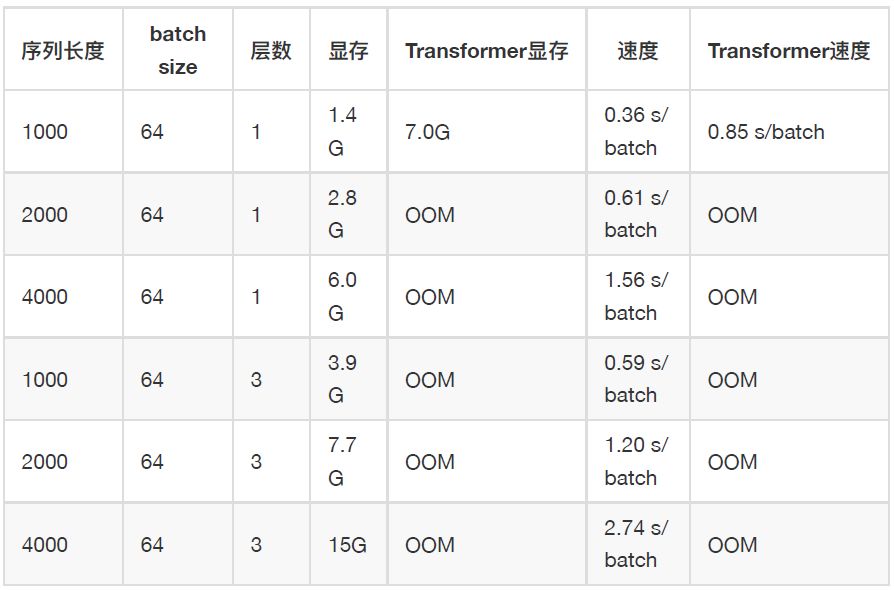
下面这张图对比了使用不同 Encoder 结构的训练过程,可以发现:
使用卷积+注意力 Encoder 比仅使用卷积 Encoder 或注意力 Encoder 都要好;
卷积对 Loss 的贡献更大,发挥主要作用,注意力发挥次要作用;
叠加多层 Block 效果更好。
五、应用效果
5.1 业务增益
首先,我们评估 Auto Risk 模型对业务的增益。我们使用的风控行为序列包括登录、改密、交易等重点风控行为。我们从全体用户中随机采样了部分作为训练集,训练了一个三层、hidden=128的网络,然后对其他用户,推断其向量。最后将这些向量加入到特征池子中,比较 AUC 效果提升。参与比较的有:
人工特征 SOTA:人工特征的 state-of-the-art,如资产能力、信贷信用等,这些都是在消费金融、信贷、先享后付等场景久经考验的特征。
+ AutoRisk pretrain:在人工特征 SOTA 的基础上,加上原始的 Auto Risk 向量。
+ AutoRisk finetune:在人工特征 SOTA 的基础上,加上场景 finetune 之后的 Auto Risk 向量。
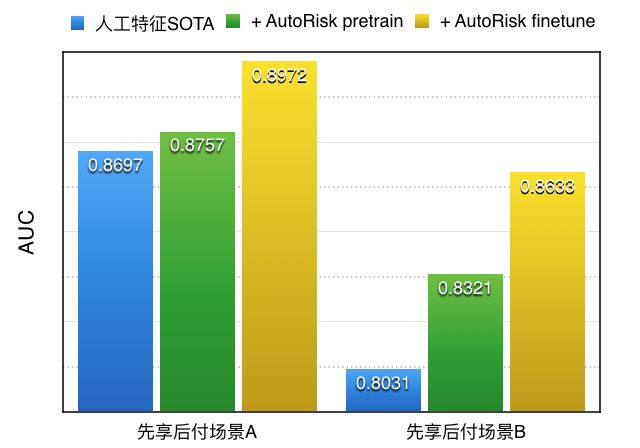
可见,加入 Auto Risk 向量之后,AUC 取得3~6个点的显著提升,说明无监督的 Auto Risk 能够从行为序列中提取到有用的特征;在具体场景中 finetune 一下网络参数会比不做 finetune 更好,这一点与 Bert 等也是相同的。为了简化对比,这张图只展示了使用风控事件作为序列数据的效果。
5.2 多场景效果
由于 pretrain 模型的训练过程没有用到任何具体的场景 label,因此学到的知识比较通用。我们尝试了不同场景,包括一些看似无关的预测性别和年龄的问题,既不加任何人工特征,也不做 finetune,只用最简单的 LR 分类器,分别做 train-test,结果比较惊喜,有的甚至 AUC 达到0.9。一个潜在的业务价值是,也许可以用超低的代价,实现对各个业务的通用补充特征。

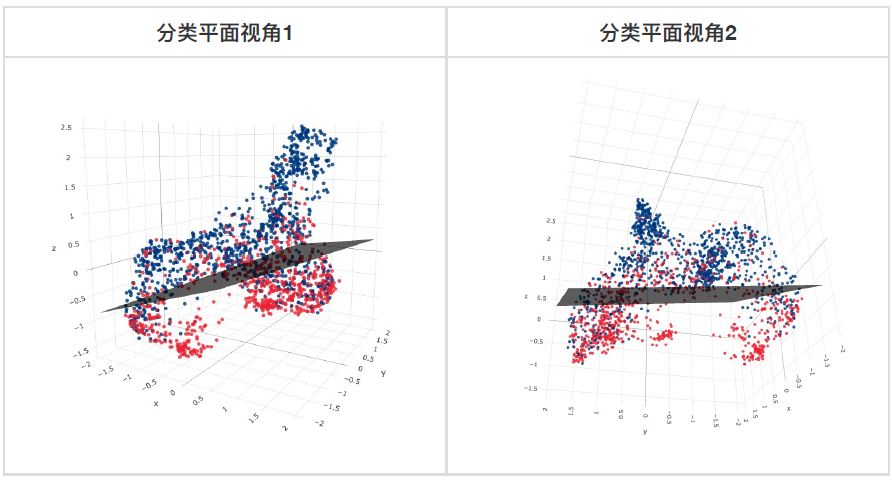
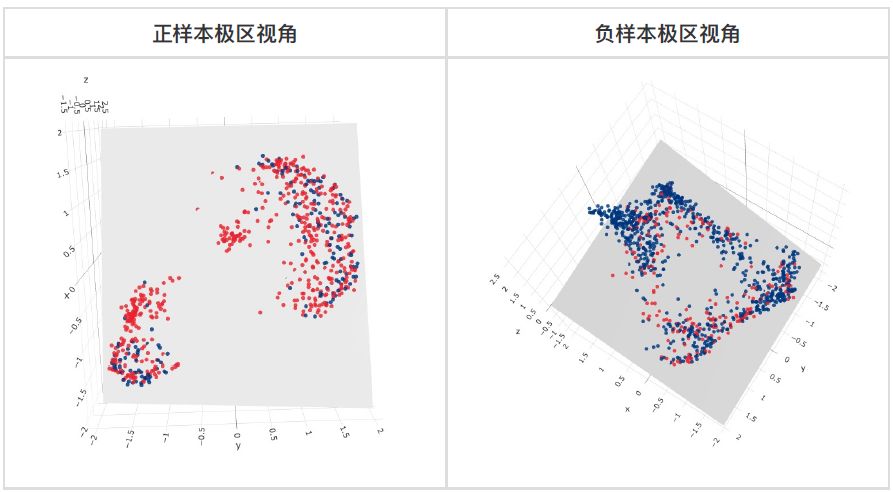
为何仅用 LR 就可以取得这样的效果?可以这样理解:Auto Risk 将行为序列的信息比较完整地保留到一个性质较好的 Embedding 空间中,对不同的任务可以找到各自适合的线性分类界面。下图展示了消费金融套现场景的测试集样本和分类平面,由于使用了降维算法(Umap)将128维的向量降到3维,分类性能损失了大约6个点的 AUC,但是依然可以清晰地看到:
1.套现和非套现商户具有明显的分类平面;
2.空间具有明显的流形结构,具体每个簇代表什么含义我们还没有去分析,但是可以肯定的是簇中的点具有相似的行为模式。
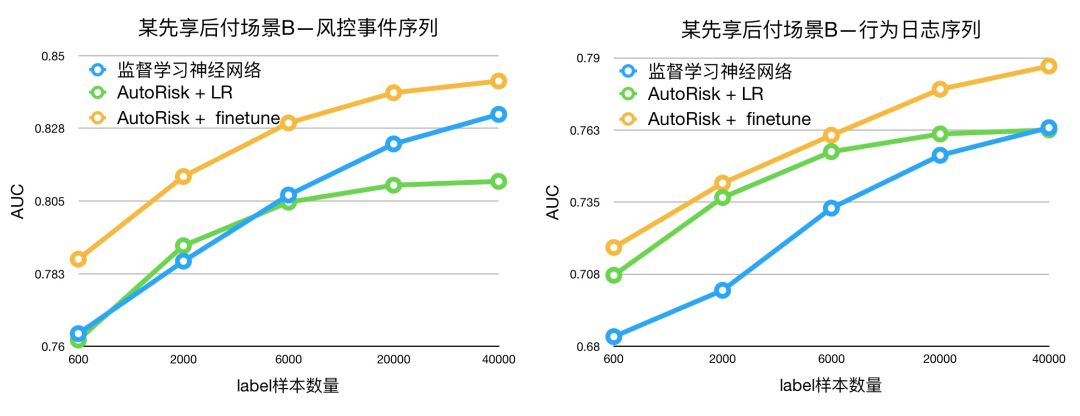
5.3 小样本学习
Pretrain 带来的另一个优势是小样本福音。深度学习模型因为参数众多,一般在 label样本较少时效果不佳,而 Pretrain 模型已经通过无监督代理任务学会了大部分知识,因此少量label样本就可以取得更好的结果,更适合冷启动或者 label 昂贵的业务。我们在先享后付场景 B 上对两类不同的行为序列数据分别进行了实验,结果都表明 Auto Risk 会比从零开始训练一个监督学习的神经网络要好的多;在行为日志数据上,甚至都不用 finetune,仅用 Auto Risk+LR,就比监督学习更好。训练集的 label 样本数量已经达到4万(正负样本各2万),监督学习还没有能够追上 Auto Risk+finetune。
5.4 序列 Analogy
Analogy,即单词类比,是 Word Embedding 的一个有趣特性。在 Embedding 空间里,国王(King)-男人(Man)=王后(Queen)-女人(Women),中国(China)-北京(Beijing)=法国(France)-巴黎(Paris),类似的等式从侧面证明了 Embedding 空间确实抓住了高层语义。那么,我们的 Auto Risk 空间中的序列有没有这种特性呢?我们同样进行了一个 A-B=C-D的实验,对100万个样本构成的集合,选定 A、B 和 D,通过与A-B+D 向量的余弦相似度召回 C。为了看得更清楚,我们将不同的字段分开展示,但训练过程还是多字段一起的。
事件类型:A(淘宝花呗付款) - B(淘宝余额付款) = C(站外花呗付款) - D(站外余额付款)。A-B 得到的淘宝付款方式的差异向量,加到站外付款用户 D 上,同样会把他的付款方式从余额变成花呗,说明模型学到的 Embedding 空间中,有一些方向是专门记录付款方式的。
A=[创建交易-淘宝实物担保,花呗付款-淘宝实物担保,创建交易-淘宝实物担保,花呗付款-淘宝实物担保,创建交易-淘宝实物担保,花呗付款-淘宝实物担保,创建交易-淘宝实物担保,花呗付款-淘宝实物担保,创建交易-淘宝实物担保]B=[创建交易-淘宝实物担保,余额付款-淘宝实物担保,创建交易-淘宝实物担保,余额付款-淘宝实物担保,创建交易-淘宝实物担保,余额付款-淘宝实物担保,创建交易-淘宝实物担保,余额付款-淘宝实物担保,创建交易-淘宝实物担保]C=[花呗付款-站外即时到账,花呗付款-站外即时到账,花呗付款-站外即时到账,pc端-创建交易,login_登录_app_其他_,花呗付款-站外即时到账,pc端-创建交易]D=[app端-登录,余额付款-站外即时到账,余额付款-站外即时到账,余额付款-站外即时到账,余额付款-站外即时到账,余额付款-站外即时到账]
金额:A(大金额用户) - B(小金额用户) = C(大金额用户) - D(小金额用户)。召回的 C 也刚好和A一样是8000和10000,看来模型对数字分档的记忆力还是不错的。
A=[\\N,\\N,10000.0,10000.0,10000.0,8000.0,8000.0,8000.0,\\N,8000.0,\\N,\\N,8000.0,\\N,8000.0]B=[\\N,\\N,10.0,10.0,10.0,10.0,10.0,10.0,\\N,10.0,\\N,\\N,10.0]C=[\\N,\\N,\\N,8000.0,\\N,\\N,8000.0,\\N,\\N,\\N,\\N,\\N,\\N,10000.0,\\N,10000.0]D=[\\N,1.0,\\N,1.0,\\N,1.0,1.0,\\N,1.0,\\N,1.0,1.0,\\N,1.0,\\N,\\N]
商品名称:A(打车高频用户) - B(充币高频用户) = C(打车高频用户) - D(充币高频用户)。注意商品名与其他字段不同,需要经过一个 CNN 或 Average 的子网络处理成向量,还能有这样的特性,而且召回了一些与"滴滴快车"相似但不同的"汽车票"、"乘车时间"等,说明网络对文本描述具有一定的泛化能力。
A=["滴滴快车-周师傅","滴滴快车-周师傅",...,"滴滴快车-邵师傅","滴滴快车-邵师傅",...]B=["腾讯Q币100元qq","腾讯Q币100元qq",...,"腾讯Q币100元qq","腾讯Q币100元qq",...]C=["滴滴快车-冯师傅","滴滴快车-冯师傅","汽车票**汽车总站(南区","","汽车票**汽车总站(南区)","","联通话费10元快充","","","滴滴快车-亓师傅","滴滴快车-亓师傅","","","0000****-车牌【00*****】乘车时间:2019-04-1914:53:02"]D=["腾讯1000QQ币1","腾讯QQ币/Q币卡/",...,"腾讯QQ币/Q币卡/","腾讯QQ币/Q币卡/",...]
六、总结
我们提出了一种行为序列深度学习算法 Auto Risk,不需要具体 label 训练,而是基于类似于 Bert 的代理任务预训练思想,从大量的未标注数据中,挖掘上下文关联和标志性特点,生成有用的高层特征,解决了 label 样本不足而 unlabel 样本又难以利用的问题。我们特别针对数据和业务特点设计模型结构,以方便快速训练部署。该方法在我们的实际业务中落地,取得了明显的效果提升;由于训练过程不需要 label,模型结果对其他场景的泛化能力较强;另外,对小样本场景提升明显;序列 Analogy 的实验侧面印证了 Auto Risk 向量空间能够捕捉高层语义。后续,我们将持续这部分工作,扩展到更多类型的数据源和应用场景,并检验其他的代理任务,包括历史积累的多场景 label 作为代理任务等。
项目组成员 | 羿之、晗枫、丰缘、形参、北远
阿里巴巴在 AI 路上
有哪些重大突破?
关注“阿里机器智能”,
了解 AI 大事,
扫我 ↓。

你可能还喜欢

你可能还喜欢
点击下方图片即可阅读

阿里高级技术专家方法论:如何写复杂业务代码?

淘宝如何打造承载亿级流量的首页?

如何用Flutter设计一个100%准确的埋点框架?

关注「阿里技术」
把握前沿技术脉搏




