数据工程师的没落

大数据文摘作品
作者:Maxime Beauchemin
编译:阮雪妮,笪洁琼,Aileen
本文是几个月前大数据文摘推送的一篇文章《数据工程师的崛起》的后续 。那是最近一篇尝试定义数据工程和描述数据工程师这一新职位与数据科学领域以往和现在的职位之间的联系的文章。如果对数据工程师这个职位不了解的读者,可以参考这篇文章《数据科学行业的8个关键角色:职责与技能》了解数据科学行业职责分类。
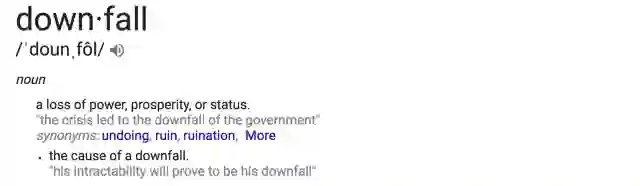
在这篇文章中我打算揭露使数据工程师寸步难行的挑战和风险,并列举这一领域在经历其“青春期”时所面临的阻力。The downfall of data engineer.

尽管这篇文章的标题有点标题党,内容很悲观,但请牢记,我对数据工程非常有信心——我只是需要一个和我之前的文章对比强烈的标题。理解并揭露这一职位正面临的逆境是寻找解决方案的第一步。
同时提请读者注意的是这里陈述的所有观点都是我个人的,并且是基于我在与很多来自硅谷的数据科学团队的人们交流时所做的了解。这些观点并不是我老板的想法,与我现在的职位也没有之间的联系。
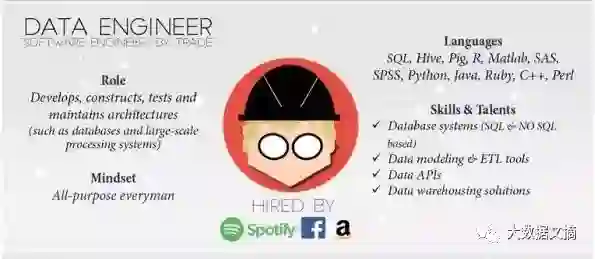
工作内容无聊 & 项目之间内容切换
编写和维护数据抽取、转换和加载(Extract Transform and Load,ETL)真的很无聊。绝大多数ETL工作需要花很长时间来执行,而错误和问题更容易在运行时出现,或是运行后才可以认定。由于开发时间对执行时间的比率较低,要做到高效就要同时周旋于多重管线之间,同时,这也就意味着需要进行大量的内容切换。在你的五个正在运行的“大数据项目”的其中之一完成之前,你不得不恢复到数小时前的大脑状态并设计下一个循环。这些取决于你有多依赖于咖啡因,距离上一个循环已经过了多久,以及你能做有多细致周到,你也许不能成功地在你的短时记忆中恢复全部的上下文语境。这将导致出现愚蠢的系统性错误,又要浪费数小时去纠正。
如果迭代周期之间的空闲时间以小时计算时,你会觉得夜以继日地工作更有效果 :晚上11点半花上5-10分钟的额外工作能够为你明天节约2- 4小时。这就可能会导致工作与生活之间的不平衡,很不健康。
寻求共识
不论你是否认为老派的数据仓库概念正在消逝,达成一致的维度和指标的追求依旧像以往一样具有重要意义。我们中的大部分人依旧能时不时地听到人们说“单一数据源”。数据仓库需要反映商业,而商业应该明确它认为这些分析怎么样。冲突的命名方式和不同命名空间或“数据集市Data Mart”中不一致的数据是有问题的。如果你想在决策支持上建立信任,你至少需要一致性以及准确性。在分析过程中的数据生成方包含数百人的现代大组织中,寻求共识在当下不是完全不可能,不过也是具有挑战性的。
过去人们用贬义词“数据孤岛”来指代与分散在平台上或引用不兼容的异质性分析相关的问题。数据孤岛在项目开始时便自然而然地大量产生,随着收购的进行,团队也不可避免地流动。使用如主数据管理(MDM)、数据集成(data integration)和厉害的数据仓库项目等增强共识的方法来解决这些问题是商业智能(现为数据工程)团队的职责。现如今,在现代快节奏的公司里,孤岛问题疯狂地不成比例增长。在这里你可以用“暗物质”这个词来描述正在发生的混乱的扩张后果。随着大量不那么合格的人们参与进来,管道网将很快变得混乱、不一致,并成为一种浪费。如果数据工程师是“数据仓库的图书管理员”,他们可能会觉得他们的工作就像在一个巨大的回收厂里分类出版物。
在仪表盘的生命周期以周计算的世界里,共识成为了几乎赶不上商业焦点的改变和切换速度的后台进程。传统主义者建议创立一个数据管理制和所有制的项目,但在特定的规模和速度下,这些努力只是一种微薄的力量,并不能与正在发生的扩张相匹配。

变革管理
由于有用的数据集被广泛使用,并且是通过会导致庞大复杂的有向非循环图(DAGs)的方法获得的,变化的逻辑或源数据可能会打破下游结构,和/或使其变得无效。下游结点比如派生数据集、报告、仪表盘、服务项目和机器学习模型便可能需要被改变来反映上游的变化。通常来说,数据传输线附近的元数据是不完整的或被掩藏在代码中,只有极少数人有能力耐心阅读。上游的变化将不可避免地以错综复杂的方式打破下游实体或使其无效。取决于你的机构如何权衡稳定性与精确性,这种变化可能是十分可怕的,并可能导致管道堵塞。如果数据工程师的工作目标是稳定性,他们很快就会认识到不打破任何东西的最好方法就是不改变任何东西。
由于管道通常是巨大且昂贵的,适当的单元测试或集成测试应当在某种程度上达到均衡。问题在于:利用抽样数据和试运行,你能确认的只有这么多。如果你认为一个单一环境的混乱程度已经超出了你能处理的范畴,那么在使用到了不同的复杂代码和数据的开发和生产环境时,请努力保持理智。凭我个人的经验,在大数据的世界里,很难找到体面地开发或测试环境。在很多情况下,你能找到的最好的就是一些人们用来支持任何他们认为合适但还未公开的进程的空间“沙盒(Sandbox)”。
数据工程已经错过了“devops运动”这只大船。devops是一种重视“软件开发人员(Dev)”和“IT运维技术人员(Ops)”之间沟通合作的文化、运动或惯例。 并且现代工程师很少受益于devops运动带来的理智和安心。他们没登上这艘大船不是因为他们没出现,而是因为船票对于他们的货物来说太昂贵了。
整个团队中最不利的角色
现代团队发展得很快,不管你的机构是工程驱动、项目管理驱动或是设计驱动,也不管它是否把自己想成是数据驱动的,数据工程师并不会起太大的驱动作用。你得把数据工程想成是基础设施的角色,是一种人们认为理所当然的东西。只有当它坏了或者是没有达到人们的预期时,它才会受到人们的关注。
如果团队人员中有数据工程师,他的工作可能是帮助数据科学家和分析师收集他们需要的数据。如果需要的数据不能在数据仓库的结构化部分得到,分析师可能会查找一些原始数据来做出短期的解决方案。此时数据工程师就需要适当地处理数据并最终把这些数据加入仓库中。很多情况下答案必须及时给出,因而当新的维度和指标被填充到数据仓库中时,它们早已是过时的新闻了,所有人都已经忘了这件事儿了。数据分析师会因其洞察力而获得荣誉,而其他所有人都可能会质疑把这一部分新信息并入数据仓库这一缓慢的后台进程是否还有必要。
虽然“冲击/影响力(impact)”——这暗示着速度与改变——是员工在其业绩评估中最希望看到的词,数据工程却被谴责为几乎没有短期影响的缓慢的后台进程。数据工程师离那些能产生积极影响的形象还有些距离。

维护蔓延
维护蔓延(Operational Creep)对那些需要维持他们自己搭建的系统的职业来说是一个残酷的事实。质量监控团队在很大程度上被“你建立的系统你自己维护”的格言取代了,并且这个领域的大部分人都支持这个观点。这被认为是一种能够适当地使工程师意识到累积的技术债务并对其负责的方法。
由于数据工程通常伴随着相当高的维护负担,维护蔓延缓慢这现象出现得很快,并且它整垮工程师的速度比你的招募速度还要快。确实,现代工具使人们变得更高效,但这无疑只是指机器帮助管道建造者能在同时使更多的“飞碟”能旋转起来而已。
此外,维护蔓延蔓延会导致更高的员工流动率,而这最终会导致低质量、不一致且不可维护的混乱。
是否是真正的软件工程师?
这个领域的人们应该听到过关于数据工程师是否是“真正的软件工程师”,或是某种不同类别的工程师的争论。在某些机构中这一职位是不同的,并且可能有不同(更低)的工资级别。随机观测的结果显示,数据工程师中拥有计算机科学学位的比率显著低于整个软件工程领域中拥有计算机科学学位的工程师的比率。
由于本文所述的原因,这一职位的名声可能在恶性循环的传播中变坏。
别急——希望还是有的!
别着急退出。各公司一致认为数据是核心竞争优势,并且他们在数据分析上的投入也比以往更多。“数据成熟度”以一个可预见的曲线形式增长并最终使人们意识到数据工程的极端重要性。在你阅读这篇的文章的同时,成百上千的公司正在他们的长期数据策略上加倍投入并投资于数据工程。这个职位很有活力,且正在发展,并有着美好前景。
随着许多公司在他们的数据的投资回报率(ROI)上停滞不前,同时感受到了“数据运算高峰”的挫败感,创新必然会出现以解决本文所描述的痛点,并最终开创数据工程的新纪元。
也许有人会说未来可能的方向是"去专门化"。如果合适的工具出现,也许简单的任务可交付给信息工作者。也许和品质监控(Q/A)团队经历的一样,软件工程职能将是更复杂的工作任务。同时随着持续输送技术和方法的不断出现,工程师们也会被解放出来。
无论如何,适当的工具和方法能够决定一个职位未来的道路。我有信心它们能够解决。这是这篇文章所表达的担忧的大部分根源。
本文作者正在构思下一篇名为“下一代,数据感知ETL”的博文。在这篇文章中他将提出一个以可达性和可维护性为核心的新框架的构思。这个尚未建造的框架有一系列很强的限制条件,但反过来它也会为达成最好的实现提供很强的保障。敬请期待!
原文链接:https://medium.com/@maximebeauchemin/the-downfall-of-the-data-engineer-5bfb701e5d6b
秋招优质课程推荐
大数据+人工智能《国庆七天集训营》
一线互联网面试官亲授
7天线下集训
6个月持续辅导
十一火热开启 限额20人
详情见海报


志愿者介绍
回复“志愿者”加入我们



往期精彩文章
点击图片阅读
忽悠神经网络指南:教你如何把深度学习模型骗得七荤八素