深度学习中的正则化技术概述(附 Python+keras 实现代码)

本文原载于微信公众号「磐创AI」,由磐创AI技术团队的磐石编译,AI研习社获其授权转载。关注「磐创AI」公众号并发送关键字「正则化数据集」获取数据集下载指引,发送关键字「正则化代码」获取完整代码。
介绍
数据科学研究者们最常遇见的问题之一就是怎样避免过拟合。你也许在训练模型的时候也遇到过同样的问题--在训练数据上表现非同一般的好,却在测试集上表现很一般。或者是你曾在公开排行榜上名列前茅,却在最终的榜单排名中下降数百个名次这种情况。那这篇文章会很适合你。
避免过拟合可以提高我们模型的性能。
在本文中,我们将解释过拟合的概念以及正则化如何帮助克服过拟合问题。随后,我们将介绍几种不同的正则化技术,并且最后实战一个Python实例以进一步巩固这些概念。
目录
什么是正则化?
正则化如何帮助减少过拟合?
深度学习中的不同正则化技术
L2和L1正则化
Dropout
数据增强(Data Augmentation)
早停(Early stopping)
使用Keras处理MNIST数据案例研究

一. 什么是正则化?
深入探讨这个话题之前,请看一下这张图片:
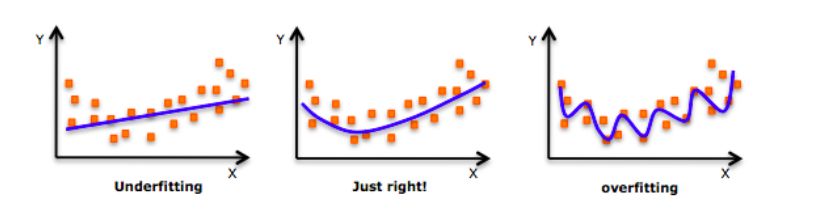
不知道你之前有么有看到过这张图片?当我们训练模型时,我们的模型甚至会试图学到训练数据中的噪声,最终导致在测试集上表现很差。
换句话说就是在模型学习过程中,虽然模型的复杂性增加、训练错误减少,但测试错误却一点也没有减少。这在下图中显示。
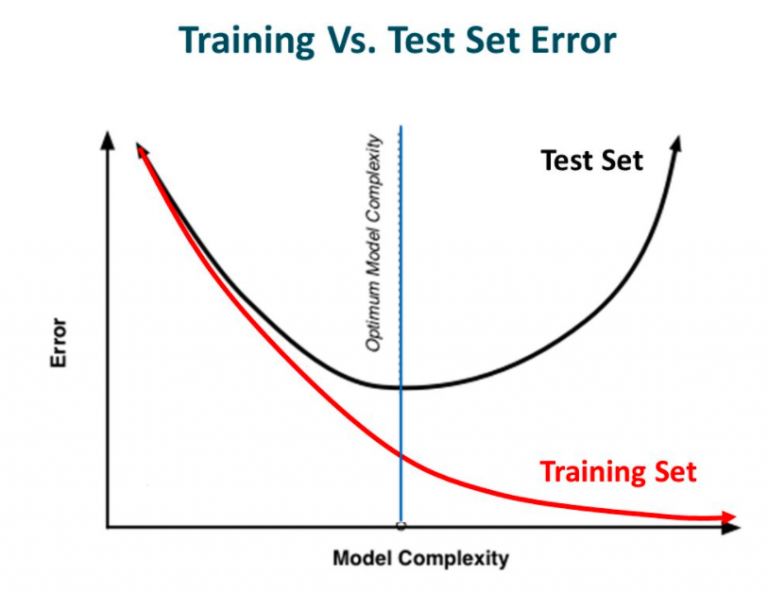
来源:Slideplayer
如果你有构建过神经网络的经验,你就知道它们是有多复杂。这使得更容易过拟合。

正则化是一种对学习算法进行微调来增加模型鲁棒性的一种技术。这同时也意味着会改善了模型在未知的数据上的表现。
二. 正则化如何帮助减少过拟合?
让我们来分析一个在训练中过拟合的神经网络模型,如下图所示。
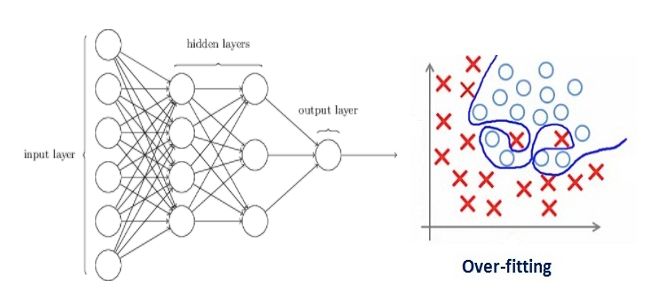
如果你了解过机器学习中正则化的概念,那你肯定了解正则项惩罚系数。在深度学习中,它实际上会惩罚节点的权重矩阵。
如果我们的正则项系数很高以至于一些权重矩阵几乎等于零。
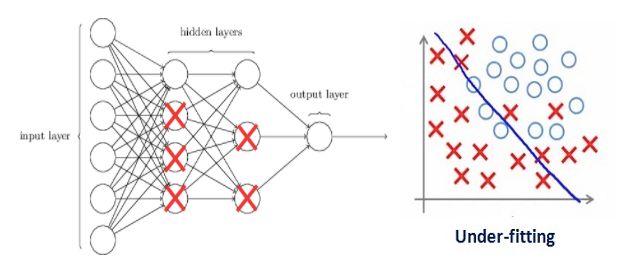
这将导致出现一个极其简单的线性网络结构和略微训练数据不足。
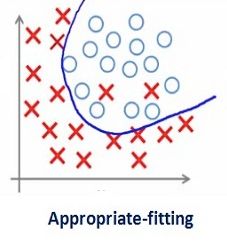
较大数值的正则项系数显然并不是那么有用。我们需要优化正则项系数的值。以便获得一个良好拟合的模型,如下图所示。
三. 深度学习中的不同正则化技术
现在我们已经理解正则化如何帮助减少过拟合,为了将正则化应用于深度学习,我们将学习一些不同的技巧。
1. L2和L1正则化
L1和L2是最常见的正则化手段。通过添加正则项来更新代价函数。
代价函数=损失(比如二元交叉熵)+正则项
由于添加了正则项,使得加权矩阵的值减小--得益于它假定具有更小权重矩阵的神经网络产生更简单的模型,故它也会在一定程度上减少过拟合。
这个正则项在L1和L2中是不同的。
在L2中,我们有:
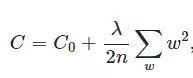
这里的lambda是正则项惩罚数。它是一个超参数。它的值可以被优化以获得更好的结果。L2正则化也称为权重衰减(weight decay),因为它使权重趋向零衰减(但不完全为零)。
在L1中,我们有:
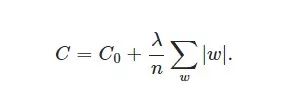
这里是惩罚权重的绝对值。与L2不同,这里的权重可以减少到零。因此,当我们试图压缩我们的模型时,它非常有用。其他的情况下,我们通常更喜欢L2。
在keras,我们可以对每一层进行正则化。
以下是将L2正则化应用于全连接层的示例代码。

同样,我们也可以使用L1正则化。在本文后面的案例研究中,我们将更详细地研究这一点。
2. Dropout
Dropout是最有趣正则化手段之一。它同样会产生较好的结果,也是深度学习领域中最常用的正则化技术。
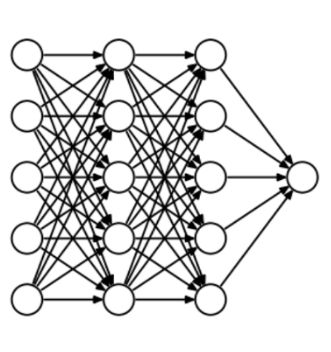
为了理解dropout,我们假设我们的神经网络结构类似于下面显示的那样:
那么dropout是怎么工作的呢?在每次迭代中,它随机选择一些节点,并将它们连同它们的所有传入和传出连接一起删除,如下图所示。
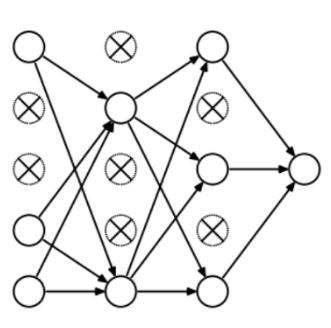
所以每次迭代都有一组不同的节点,这导致了一组不同的输出。它也可以被认为是机器学习中的集成技术(ensemble technique)。
集成模型通常比单一模型表现得更好,因为它们捕获更多的随机表达。类似地,dropout也比正常的神经网络模型表现得更好。
选择丢弃节点的比率是dropout函数中的超参数。如上图所示,dropout可以应用于隐藏层以及输入层。
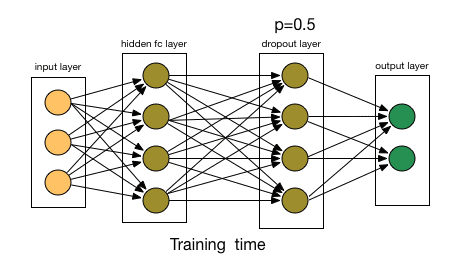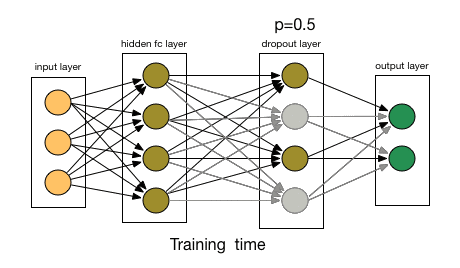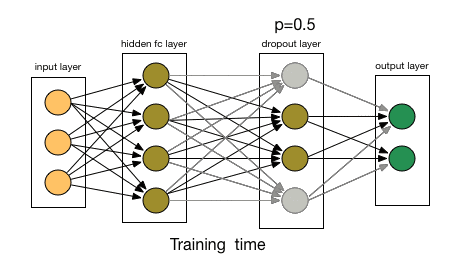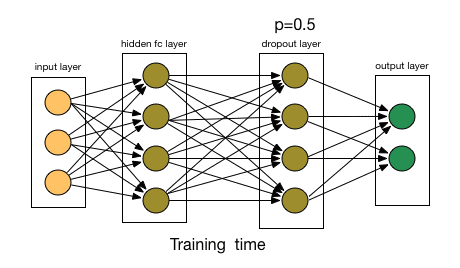
来源:chatbotslife
由于这些原因,当运用较大的神经网络结构时若想增加随机性,通常首选dropout。
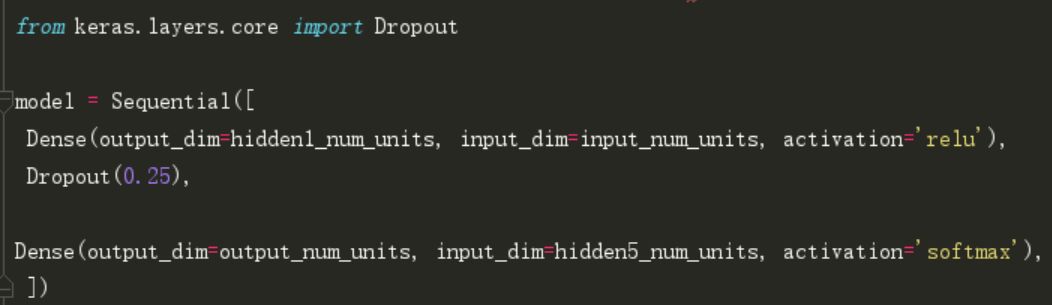
在keras中,我们可以使用keras常用层(core layers)实现dropout。如下:
3. 数据增强(Data Augmentation)
减少过拟合的最简单方法是增加训练数据的大小。在机器学习中,我们无法增加训练数据的大小,因为标记的数据成本太高。
但是,现在让我们考虑我们正在处理图像。在这种情况下,可以通过几种方法来增加训练数据的大小-旋转图像,翻转,缩放,移位等。下图是在手写数字数据集上进行的一些变换。

这种技术被称为数据增强。这通常会较大的提高模型的准确性。为了改进模型得的泛化能力,它可以被视为暴力技巧。
在keras中,我们可以使用ImageDataGenerator执行所有这些转换。它有一大堆你可以用来预处理训练数据的参数列表。
以下是实现它的示例代码。

4. 早停(Early stopping)
早停是基于交叉验证策略--将一部分训练集作为验证集。一旦发现验证集的性能越来越差时,我们就立即停止对该模型的训练。这个过程被称为早停(Early stopping)。
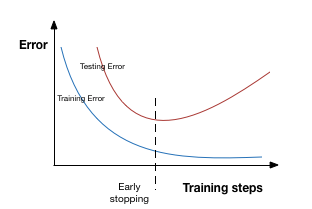
在上图中,我们将在虚线出停止训练,因为在此之后,我们的模型将在训练集上过拟合。
在keras中,我们可以使用回调函数(callback)实现早停。以下是它的示例代码。
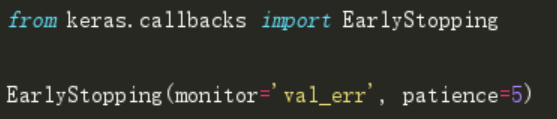
在这里,monitor表示需要监视的数量,'val_err'表示验证错误。
Patience表示当early stopping被激活(如发现loss相比上一个epoch训练没有下降),则经过 patience 个epoch后停止训练。 为了更好地理解,让我们再看看上面的图片。在虚线之后每经历一个epoch都会导致更高的验证集错误率。因此,虚线后5个epoch(因为我们的patience等于5)后我们的模型将停止训练--由于不再进一步的提升。
注意:在5个epochs(这是为patience一般定义的值)之后,模型可能会再次开始改善,并且验证错误也开始减少。因此,我们需要在调整超参数时多加小心。
四. 使用Keras处理MNIST数据集案例研究(A case study on MINIST data with keras)
到这里,你应该对不同的正则化技术有了一定的理论基础。我们现在将这些技术手段应用于我们的深度学习实践问题--手写体数字识别中(https://datahack.analyticsvidhya.com/contest/practice-problem-identify-the-digits/)。下载了数据集后,就可以开始下面的实践之旅了。首先,导入一些基本库。
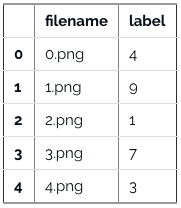
数据集可视化显示图片。

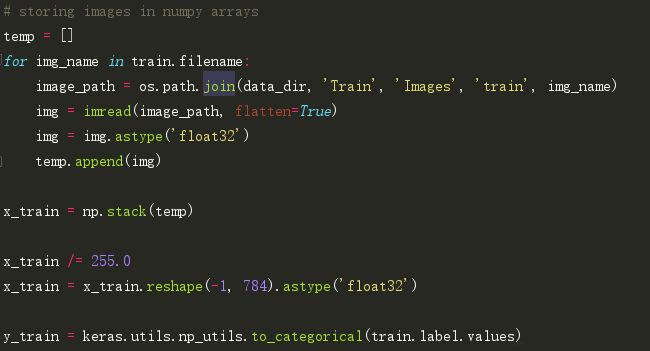
创建验证集(val),优化我们的模型以获得更好的表现。我们将用70:30的训练和验证数据比率。

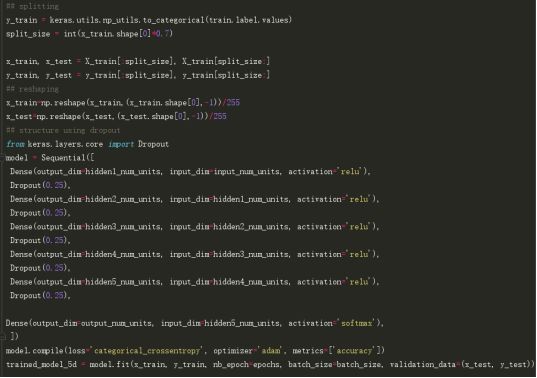
第一步,构建一个带有5个隐藏层的简单神经网络,每个层都有500个节点。
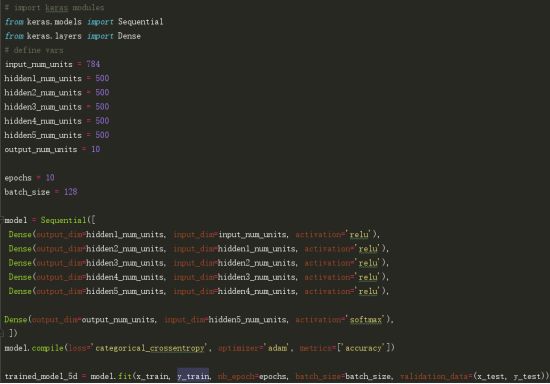
请注意,运行10个epoch。让我们看看它的实际表现。


然后,让我们尝试使用L2正则化方法,并对比它是否比简单的神经网络模型有更好的结果。
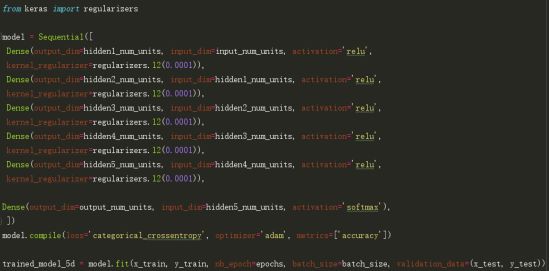
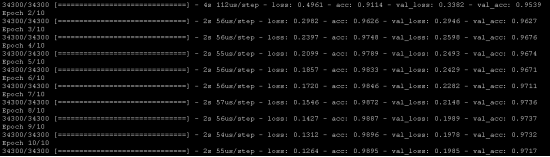
注意lambda的值等于0.0001。Cool,获得了比我们以前的NN模型更高的精度。
现在,我们来使用下L1正则化技术。
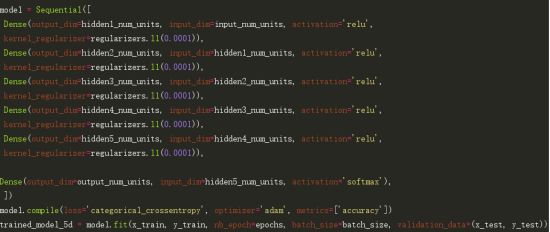
这对比之前未经过处理的神经网络结构来说没有任何改进,接下来试一下dropout技术。
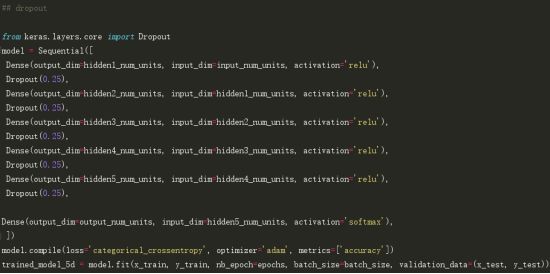
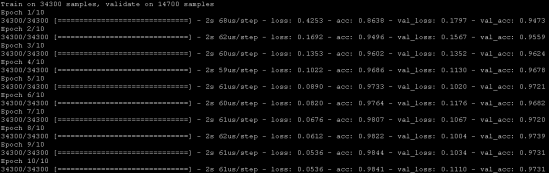
不错。dropout使我们对比原来未处理的NN模型有了一些改进。
现在,我们尝试数据增强(data augmentation)。
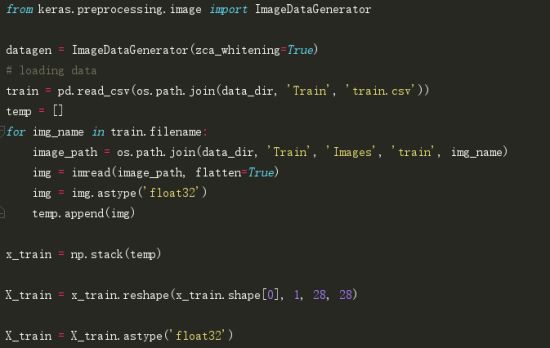
现在,为了增加训练数据:
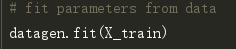
在这里,我使用了zca_whitening作为参数,它突出了每个数字的轮廓,如下图所示。
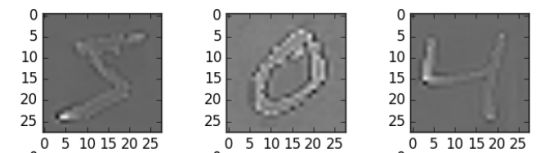

哇。这次准确率有了较大的提升。这种优化方式适用范围广,我们只需根据数据集中的图像特点选择适当的参数。
最后,让我们尝试最后一个正则化方法-早停(early stopping)。

你可以看到,模型训练仅在5次迭代后就停止了--由于验证集准确率不再提高。如果设置更大的epoch运行,它也许不会有较好的结果。你可以说这是一种优化epoch数量的技术。
结语
希望现在你对正则化技术以及怎样在深度学习模型中实现它有了一定的了解。强烈建议在深度学习任务中应用它,它将可能会帮助提升你对模型的理解与认知。
是否觉得这篇文章会有帮助?欢迎下面的评论部分分享你的想法。
(编译自:https://www.analyticsvidhya.com/blog/2018/04/fundamentals-deep-learning-regularization-techniques/)

NLP 工程师入门实践班
三大模块,五大应用,知识点全覆盖;
海外博士讲师,丰富项目分享经验;
理论+实践,带你实战典型行业应用;
专业答疑社群,讨论得出新知。

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据资料】
嘀~正则表达式快速上手指南(上篇)
▼▼▼




