论文浅尝 - JWS2020 | FEEL: 实体抽取和链接的集成框架
论文笔记整理,谭亦鸣,东南大学博士生。

来源:JWS 2020
链接:https://www.sciencedirect.com/science/article/pii/S157082682030010X?via%3Dihub
介绍
实体抽取和链接(Entity extraction and linking, EEL)是语义网的一个重要任务,它能够从文本中识别现实世界的对象,并关联到知识库中的相应资源上。因此,EEL任务的一个目标是从文本中抽取知识。近年来,一些EEL系统被提出,它们着眼于不同的领域,语言以及知识库。这种情况下,一些尝试结合不同EEL系统优势的集成系统被提出,以提供比单一系统更好的性能。但是,目前尚没有一个清晰的全局配置指导,用于帮助集成系统选择,配置EEL系统,以及结果的融合。这篇论文提出一个框架,通过对系统选择,输入参数配置,系统执行以及最终的答案融合提供建议(答案融合基于一个对实体出现及重叠的过滤策略建立),从而构建融合EEL系统。基于这个框架,作者使用现有EEL系统实现了一个集成系统,通过GERBIL框架的实验结果表明,在七个数据集上,相对于单一EEL系统,集成系统的微观/宏观精度与召回率均有提高。

动机
集成EEL系统能够利用不同EEL系统的优势,从而得到比单一系统更好的性能。集成系统的一般思路是将两个或更多的EEL系统的输出统一为一个候选结果集。此外,多系统的命名实体抽取结果合成,亦能够比单一系统识别出更多的实体。
但是,集成EEL涉及到不同阶段的系统选择,参数配置以及集成决策,从而实现具有同类结果的系统。首先,对于EEL系统的选择与执行,包括领域,资源需求以及实现环境等多个因素需要被考虑。第二,在参数配置方面,输入参数的选择显然会直接影响到输出结果。例如,置信度参数控制命名实体在提及与URIs之间的匹配程度。最后,不同EEL系统的组合可能产生重复/部分重叠的实体元组(不同命名实体共享了一个文本中的提及)。因此,为集成系统提供系统选择,配置及结果融合的建议是一个明确的发展需要。
方法
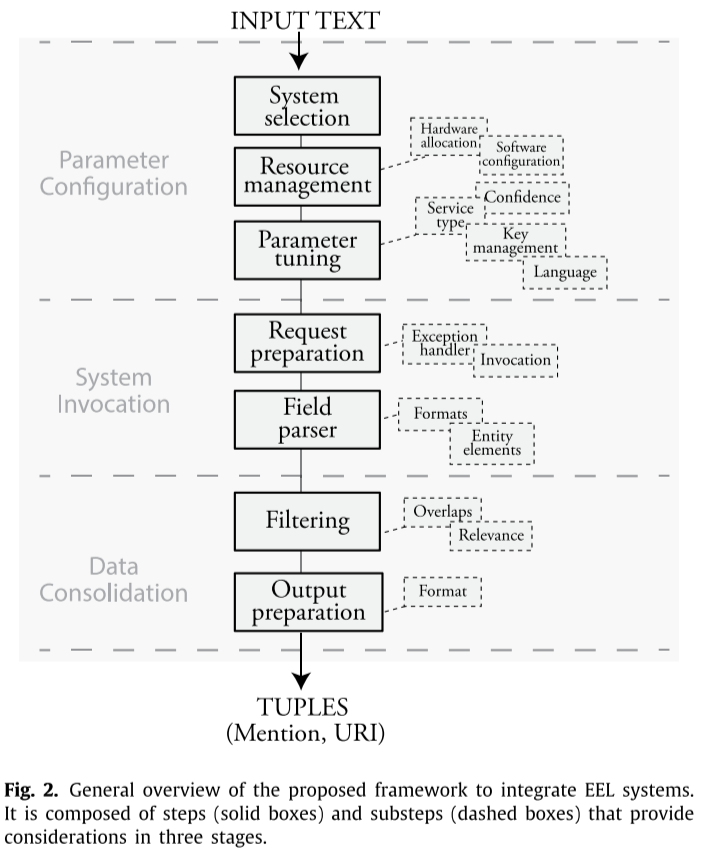
本文提出FEEL(Frameworkfor the integration of Entity Extraction and Linking systems),旨在为集成EEL系统提供一个具有整体设定的推荐,概念以及任务的结构。图2中描述了该框架的三个主要阶段:
1.参数配置:
a)系统选择,以开放域数据场景为例,四个EEL系统被用于集成系统的实现(TagMe, DBpedia Spotlight, Babelfy, WAT),系统的选择遵循(i) 系统的研究报告中具备精准度和召回率之间的平衡。 (ii) 系统能够处理多个领域/包含不同特征的数据集。(iii) (免费)可用。
b)资源管理,针对EEL系统所需的软硬件资源的管理
c)参数调试,一般而言,EEL系统具有一些输入参数,例如置信度,输入文本,语言,输出格式,token-key等。这一步涉及对最常见输入参数(尤其置信度)的描述和配置。
i.置信度:置信度作为一个阈值,控制了从文本中抽取命名实体的数量,一般一个更高的置信度代表(获取实体的)高精度,但一定程度上损失召回。相对于使用基于经验的参数配置,FEEL选择基于GERBIL框架,通过在一个确定数量的数据集上对不同系统进行测试,从而确定参数配置,主要策略包括:
1.数据集选择,领域相关性
2.使用EEL系统在所选数据集上进行(多次)实验,获取micro-F1结果
3.获取产生F1结果较好的置信度区间
4.获取置信度区间的中间值
5.视情况对置信度配置值向上可选
ii.提取类型。EEL可选的提取类型包括:仅从文本中做实体抽取(而不链接),或仅将抽取出的实体标注为特定类别而非具体实例。
iii.输入文本:一般就是纯文本
iv.语言:EEL系统能识别和覆盖不同的语言(若系统未检测到输入文本的语言,则必须指定该项)
v.输出格式,系统需支持输出实体的不同格式(如基于LinkData的格式)
vi.Token-key,这个主要是为了限制(每日的)用户请求,用于成本控制
2.系统调用:系统调用的目标是对于给定的输入文本获取一组命名实体元组,主要包含两个部分:
a) Request preparation:这里主要考虑系统的调用和异常处理,假定某个EEL系统的执行出现故障,集成系统应该能够继续执行剩余EEL以获得尽可能多的结果
b) Field parser:这一步主要涉及单个EEL系统检索得到的命名实体,指的是不同输出的实体标识,其中必须包含实体元组元素
3.数据合并:由EEL获得的结果里往往存在重叠情况,这种情况需要被过滤以得到统一的结果,在过滤方面有四个因素需要被考虑:
a)实体频率,低于某个频率阈值的实体需要被移除。
b)重复的提及,当两个或更多的实体对应了相同的文本提及时,需要通过排序选择最可能一个。这里作者采用了频率排序的方式进行过滤。
c)重复元组的去重。
d)局部实体重叠,这里指命名实体之间的提及存在局部重叠的情况,FEEL选择保留提及长度最长的部分。
过滤过程见算法1:

实验
数据集
用于调参的数据集的统计信息如下表
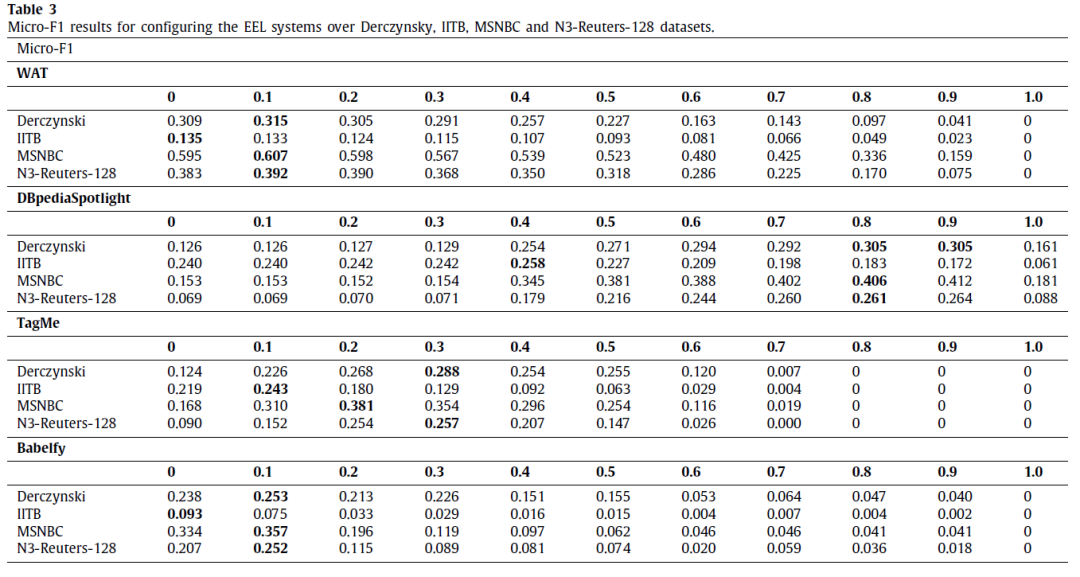
单一EEL系统在各数据集上的F1结果,用于参数配置
强弱匹配情况下,各独立EEL的实验结果
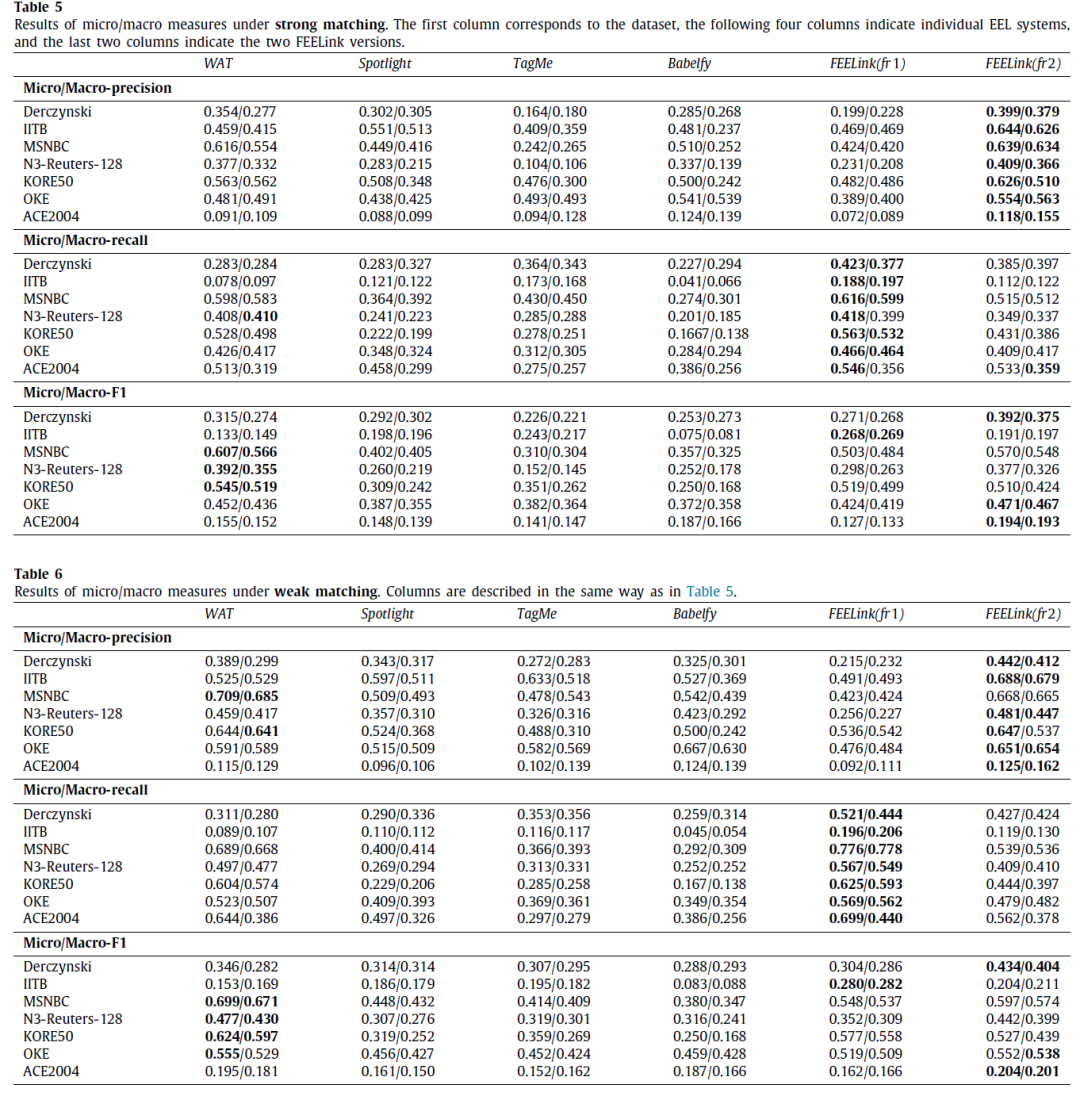
最好的单一系统与FEEL集成系统的实验结果对比
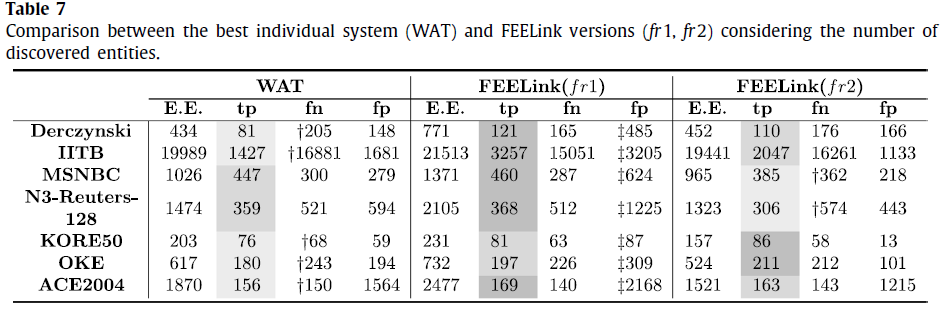
其他实验细节结果请见论文原文。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。




