【首发】阿里巴巴夺中文语法大赛全球冠军,iDST自然语言处理团队解读技术细节
点击上方“公众号”可以订阅哦!
【导读】11月24日消息,阿里巴巴iDST在中文语法错误自动诊断大赛三个level中全面夺得冠军。本文带来分析解读。
11月24日消息,阿里巴巴iDST在中文语法错误自动诊断大赛(Chinese Grammatical Error Diagnosis,以下简称 CGED)三个level中全面夺得冠军。即便是最难的level,核心指标F1(综合考虑准确率与召回率)依旧达到了 0.2693,比其他参赛机构高出一倍。
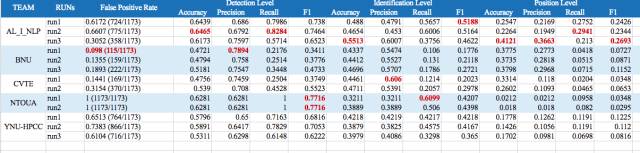
参赛机构比赛成绩公布
CGED是自然语言处理领域的权威赛事,由IJCNLP联办,今年已是第四届。比赛的背景是:学习中文的外国人数不断增加,由于中文的博大精深,外国友人在中文写作中会出现各式错误。主办方挑选了一些外国友人写的中文作文片段,希望参赛者用人工智能算法自动识别里面的语法语义错误。
因为语法纠错任务涉及到很多自然语言的基础技术,如分词、句法分析、词法分析、依存关系以及语义分析等,是对研究机构综合技术实力的全面考验。

CGED官网
阿里巴巴iDST自然语言处理首席科学家司罗介绍,中文语法诊断的挑战性在于,中文语言知识丰富、语法多样;人在判断一句话是否有错误的时候,会用到长期积累的知识体系(比如一句话是否通顺、两个词是否可以搭配、语义上是否成立等)。相比之下,比赛提供的训练数据非常有限,仅通过训练数据来识别错误是很困难的。
赛题中包含的错误分为四种类型:多词(Redundant)、缺词(Missing)、错词(Selection)和词序错误(Word Order)。系统性能的评估也由易到难分为3个level:detection level(识别句子有没有错误)、identification level(识别错误句子的具体错误类型)和position level(识别错误的位置和对应类型)

比如,“我要送給你一个庆祝礼物。要是两、三天晚了,请别生气”这句话,在第3个Level,AI需要明确指出“两、三天晚了”存在错误才能得分(正确用法应该是“晚了两、三天”)。
根据组委会公开的结果,司罗团队在所有的3个level的正确率都以较大优势位居第一,获取2017 CGED比赛的冠军。他们通过在深度学习中引入无监督的语法知识,同时结合了集成学习等方法。
技术细节上,IDST团队在bilstm-crf模型的基础上,结合了分词、词性、依存句法等特征,同时将language model等无监督的知识embedding到神经网络。依靠RNN结构以及词性、依存等特征,不光能识别短程的语法错误,比如“一头牛”好于“一只牛”;也能识别比较长程的语法错误,比如“虽然父母很辛苦,而且对孩子照顾得很好”中“虽然”和“而且“不搭配。此外,他们针对比赛的3个不同level,设计了不同的基于神经网络的snapshot emsembles方法。

具体请见论文:Alibaba at IJCNLP-2017 Task 1: Embedding Grammatical Features into LSTMs for Chinese Grammatical Error Diagnosis Task
透视司罗以及iDST自然语言处理团队:

司罗是全球权威机器智能学者,曾担任美国普渡大学计算机系终身教授,主持的20余个项目得到美国政府、工业界资助,先后获得美国国家科学基金会成就奖、雅虎、谷歌研究奖等。
在阿里巴巴,司罗领导了iDST自然语言处理团队,除了支持阿里巴巴大生态(新零售、金融、物流、娱乐、旅行等)的自然语言处理需求,也通过阿里云技术输出给开发者。
这场比赛中使用的分词、词性标注和句法分析等基础NLP工具都是由该团队自主研发的AliNLP 平台。这个平台支持阿里大生态的每天多达600亿次的自然语言处理需求。
司罗团队横跨中国(杭州,北京)和美国(硅谷,西雅图),普遍拥有10年以上自然语言处理研发经验,30%以上有博士学历(如CMU,伯克利,普林斯顿,清华,北大等)。 团队多次在国际自然语言技术竞赛中取得冠军成绩。

注:投稿请电邮至124239956@qq.com ,合作 或 加入未来产业促进会请加:www13923462501 微信号或者扫描下面二维码:

文章版权归原作者所有。如涉及作品版权问题,请与我们联系,我们将删除内容或协商版权问题!联系QQ:124239956





