MIT提出TbD网络,让视觉问答模型更易于解释同时保持高性能
编者按:论智曾系统地介绍过视觉问答技术,而在本文中,MIT的研究人员研发了一种新型神经网络,称为Transparency by Design,既有出色的性能,还易于解释。以下是论智对论文的大致编译。
视觉问题回答(VQA)需要对图像进行高阶推理,这是机器系统执行复杂指令的基本能力。最近,模块化网络已被证明是执行视觉推理任务的有效框架。虽然模块化网络最初设计时具备一定的模型透明度,但当用于复杂的视觉推理任务时,表现却不那么完美。即使是目前最先进的方法也没有理解推理过程的有效机制。在本文,我们消除了可解释模型和最先进的视觉推理方法之间的性能差距,提出了一套视觉推理原型,它可以作为一个模型,以明确可解释的方式执行复杂的推理任务。而原型输出的准确性和可解释性能让人轻易地判断模型的优点和缺点。重要的是,我们证明原型的性能出色,在CLEVR数据集上的最高精确度达99.1%。另外,当面对含有新数据的少量样本时,模型仍然能有效地学习。利用CoGenT泛化任务,我们证明该模型比现有技术水平提高了20个百分点。
一个VQA模型必须具备推理图片中复杂场景的能力,例如,要回答“大金属球右边的正方体是什么颜色?”这个问题,模型必须先判断哪个球体是最大的,而且还是金属的,然后理解“右边”是什么意思,最后把这一概念应用到图片中。在这一新兴领域中,模型必须找到正方体,然后辨别它的颜色。这种行为需要综合能力才能应对任意推理过程。
Transparency by Design
将一个复杂的推理过程分解成一连串小问题,每个问题都能被独立解决再组合,这种推理方法非常强大且有效。这种类型的模块化结构同样允许在推理的每个步骤对网络输出进行检查。受此启发,我们开发了一种神经模块网络,能够在图像空间中建立一个注意力机制模型,我们称之为Transparency by Design network(TbD-net),重点突出透明度是此次设计的亮点。
下表是TbD-net中用到的模块汇总。“Attention”和“Encoding”分别表示从上一模块中输出的单一维度和高维度。“Stem”表示训练过的神经网络生成的图像特征。变量x和y表示场景中的目标物体,[property]表示物体的颜色、形状、大小或是材料的其中一个特点。
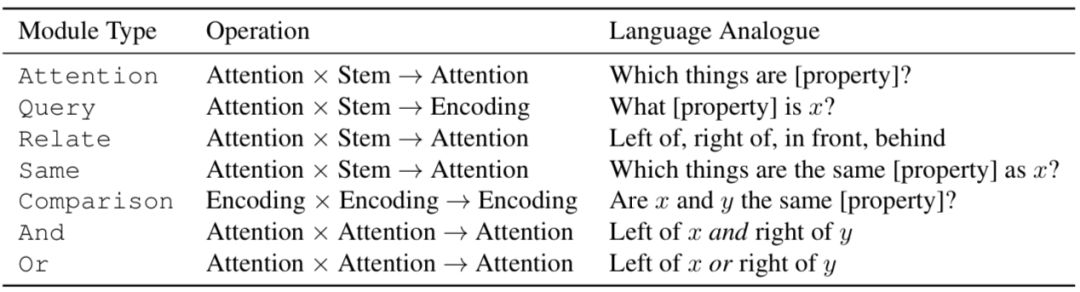
Attention模块负责能体现目标物体特征的图像区域,例如如果图像中有红色目标,模块就会被使用。在Attention模块中输入图像特征,然后进行微调。之后输出一张关于维度的热图1×H×W。
And或Or逻辑模块分别在交集和并集中组合两个注意力掩码,这些操作不需要学习,因为它们已经经过微调并且可以用手工实现。
Relate模块表示一个区域与另一个区域有某种空间关系;Same模块负责从区域中提取某种相关特征,然后与图像中的其他模块分享这种特征。例如,当回答“哪个物体的颜色和小正方体一样?”这种问题时,网络需要利用Attention模块锁定小正方体,然后利用Same模块判断它的颜色,然后输出一个注意力掩码,定位出所有与其有相同特征的物体。
Query模块需要从图片中某个位置提取出特征。例如,这些模块要判断某个对象的颜色是什么。每个Query模块就会输入特征和注意力掩码,然后产生带有相关特点的特征映射。
Compare模块可以比较两个Query模块输出的属性,并生成一个特征映射,该映射对特征是否相同进行了编码。
下图是TbD网络在解决复杂VQA问题时,在推理过程中注意力变化的过程:
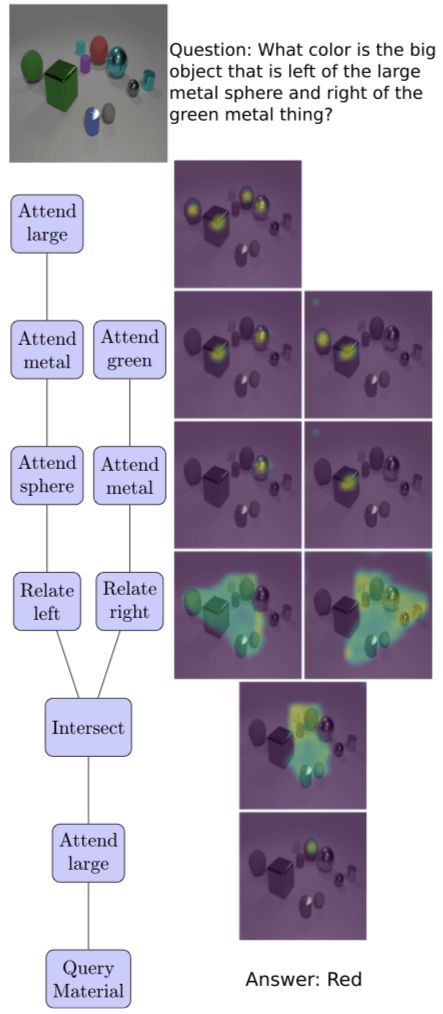
注意,模块在使用注意力时并不用学习,而是利用经过它们的注意力,生成精确的注意力映射。所有的注意力掩码都是由感官上一致的颜色映射生成的。
实验过程
为了评估模型性能,研究人员使用了两个数据集:CLEVR和CLEVR-CoGenT。CLEVR是一个含有7万张训练图像和70万个训练问题的VQA数据集,同时还有15000张图像和150000个问题作为测试和对照集。
CLEVR
最初在CLEVR数据集上测试时,模型的精确度为98.7%,远远优于其他神经模块化网络。在这之后研究人员检查了模型产生的注意力掩码,发现背景有噪音。虽然不影响模型的性能,但这些杂乱的区域可能会误导用户。于是,研究人员对其进行了泛化处理,对比结果如下图所示:

没有经过泛化,模块在背景区域产生了少量的注意力,目标物体处的注意力较多,而其他物体上的注意力为零。当加上泛化后,背景中杂乱的注意力消失,注意力精准地落在目标物体上。
除此之外,最初的模型将14×14的特征映射作为每个模块的输入,但是这对于解决密集物体图片却很困难。于是将特征映射的分辨率调整为28×28之后,这个问题就解决了。如下图所示:

当要求观察蓝色橡胶物体后面和青色大圆柱前面的空间时,左边是输入的图像,中间是分辨率为14×14的映射,右边是28×28的映射。
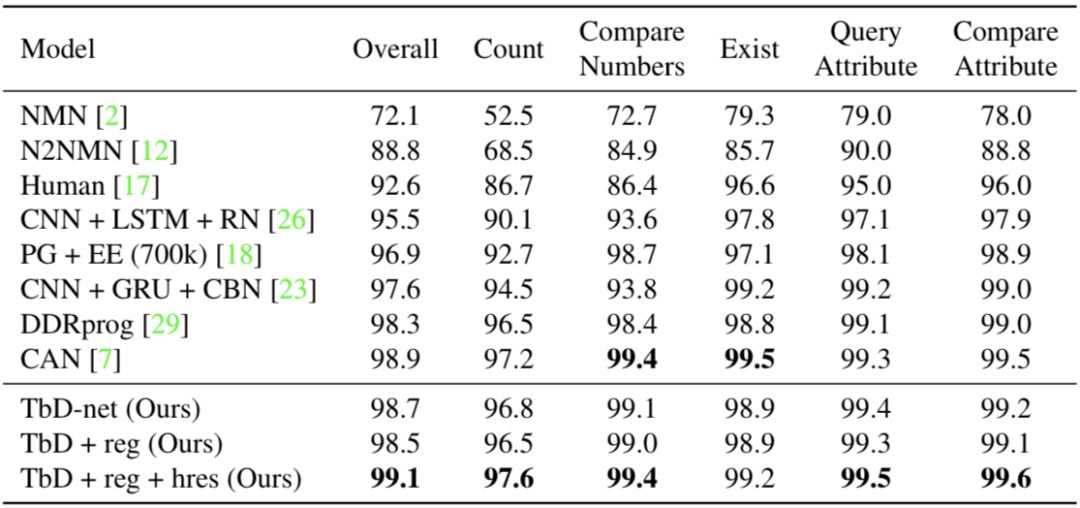
经过上述两方面的改进,模型在CLEVR上的性能由原先的98.7%升至99.1%,模型与其他方法的对比可以在下表中看到,其中TbD-net是最初的模型,“+reg”表示增加了泛化,“+reg+hres”表示在泛化的基础上提高了特征映射的分辨率:
透明度
下面研究人员还对透明度就行了量化分析,接着还检查了几个模块的输出,证明了在没有任何光滑处理的前提下,模型的每一步都可以直接解读出来。
如果模块能明显的标记出正确的目标物体,那么他的注意力就是可解释的。下图展示了一个Attention模块的输出,它将注意力放在所有金属物体上。

然而,在更复杂的操作中,例如Same和Relate模块仍然能产生直接的注意力掩码。在下图中这些模块仍然容易理解。
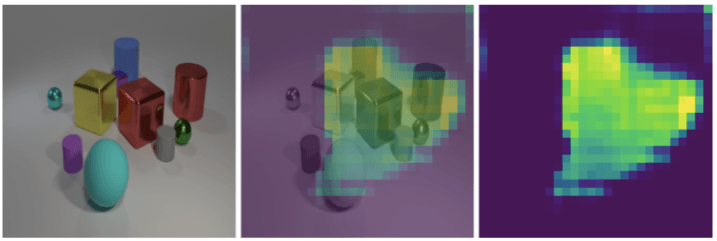
左图是输入的图像,右图是Relate模块生成的注意力掩码,它接收到要注意紫色的圆柱体。中间的图表示注意力掩码与输入的图相重叠。很明显,注意力落在了紫色圆柱体右边的所有区域。

左图是输入的图像,右图是Same模块输出的掩码,它被要求注意蓝色的球体。中间的图表示输入图像与掩码重叠。最终说明它成功地完成了任务:首先确定球体的颜色,然后确定这一颜色的所有对象,最后找到有该颜色的目标物体。
CLEVR-CoGenT
CLEVR-CoGenT对于泛化测试是一个好选择,它在形式上与CLEVR相同,但只有两个特殊条件。A,所有的立方体必须是灰色、蓝色、棕色或黄色其中的一种,所有的圆柱体必须是红色、绿色、紫色或青色的一种;B,颜色被互换。
结果表明,当只用A情况的数据进行训练时,模型的性能在A下的表现优于B。下图说明了模型在两种情况下的性能:
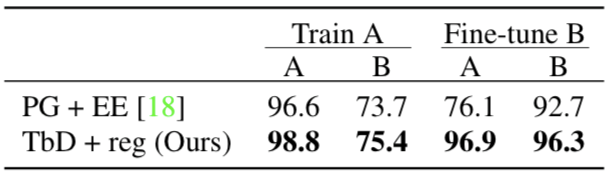
接着,研究人员用B中的数据对模型进行微调,模型的准确率由75.4%升至96.3%。
结语
本文中,研究人员提出了Transparency by Design网络,这些网络组成可视基元,利用外部注意力机制执行复杂的推理操作。与此前的方法不同,由此产生的神经模块网络既具有高性能,有方便解释。
论文地址:arxiv.org/pdf/1803.05268v1.pdf




