深度学习中Attention机制的“前世今生”

极市导读
随着注意力在机器学习中的普及,包含注意力机制的神经结构也在逐渐发展。但是大多数人似乎只知道Transformer中的Self-Attention。在文本中,我们来介绍一下Attention机制的“前世今生 ”(即Attention机制的发展)。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
写在前面
随着注意力在机器学习中的普及,包含注意力机制的神经结构也在逐渐发展。但是大多数人似乎只知道Transformer中的Self-Attention。在文本中,我们来介绍一下Attention机制的“前世今生 ”(即Attention机制的发展),Attention的发展主要经历了四个阶段:
(1)The Encoder-Decoder Architecture (编-解码器结构)
(2)The Transformer
(3)Graph Neural Networks (图神经网络)
(4)Memory-Augmented Neural Networks (增强记忆神经网络)
对啦,关于各种Attention的核心代码复现,我也给大家准备好了,保证深度学习的小白也能看懂,请大家放心食用:
https://github.com/xmu-xiaoma666/External-Attention-pytorch
1. 编-解码器结构
编解码器结构被广泛应用于语言处理中的序列到序列(seq2seq)任务。在语言处理领域,这类任务的例子包括机器翻译和图像字幕。最早使用注意力是作为基于 RNN 的编码器框架的一部分来编码长输入句子。因此,注意力在这个架构中得到了最广泛的应用。
在机器翻译的上下文中,这样一个 seq2seq 任务将涉及到将一个输入序列 i = { a,b,c,< eos > }转换成一个不同长度的输出序列 o = { w,x,y,z,< eos > }。对于一个未经Attention的基于 RNN 的编解码器架构,展开每个 RNN 将产生以下图形:
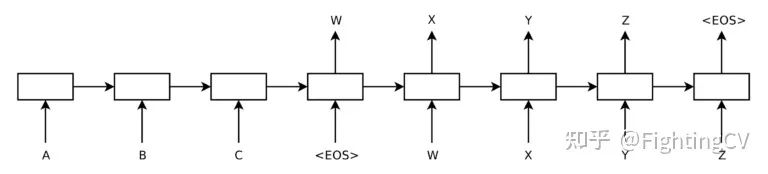
在这里,编码器一次读取一个单词的输入序列,每次更新其内部状态。当它遇到 < eos > 符号时停止,这表示序列的结束已经到达。由编码器生成的隐藏状态实质上包含输入序列的向量表示,然后由解码器处理。
解码器一次生成一个单词的输出序列,将前一时间步骤(t-1)处的单词作为输入,生成输出序列中的下一个单词。一个 < eos > 符号在解码端信号表示解码过程已经结束。
当不同长度和复杂度的序列用固定长度的矢量表示时,编解码器结构的问题就出现了,这可能导致解码器丢失重要信息。
为了解决这个问题,一种基于注意力的体系结构在编码器和解码器之间引入了一种注意机制。
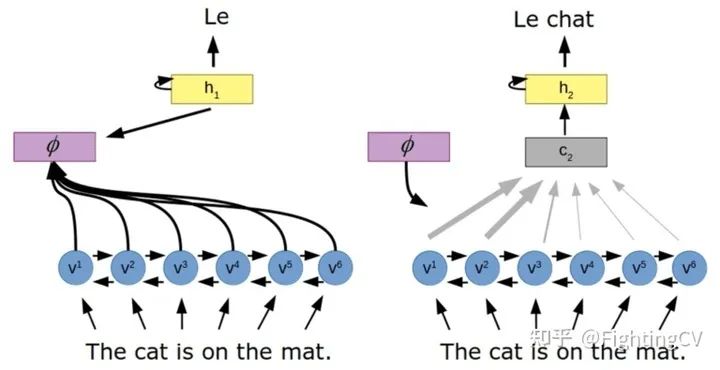
在这里,注意机制(φ)学习一组注意力权重,捕获编码向量(v)和解码器的隐藏状态(h)之间的关系,通过编码器所有隐藏状态的加权和生成上下文向量(c)。这样,解码器就可以访问整个输入序列,从而attend与生成输出最相关的输入信息。
2. The Transformer
Transformer的体系结构也实现了编码器和解码器,然而,与我们上面讨论的体系结构相反,它不依赖于循环神经网络的使用。Transformer架构不需要任何“循环”,而是完全依赖于自注意机制。在计算复杂度方面,当序列长度 n 小于表征维数 d 时,自注意层比递归层快。
自注意机制依赖于查询、键和值的使用,这些查询、键和值是通过用不同的权重矩阵乘以编码器对同一输入序列的表示而生成的。Transformer使用点积(或乘法)注意力,在生成注意力权重的过程中,每个查询都通过点积操作与键数据库匹配。然后将这些权重乘以这些值得到最终的注意力向量。
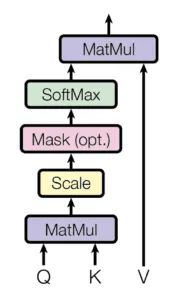
直观地说,由于所有查询、键和值都来自相同的输入序列,因此自我注意机制捕获同一序列中不同元素之间的关系,突出显示那些最相关的元素。
由于Transformer不依赖RNN,通过增加编码器对每个元素的表示,可以保存序列中每个元素的位置信息。这意味着Transformer结构也可以应用于计算机视觉任务的图像分类,分割或图像字幕。
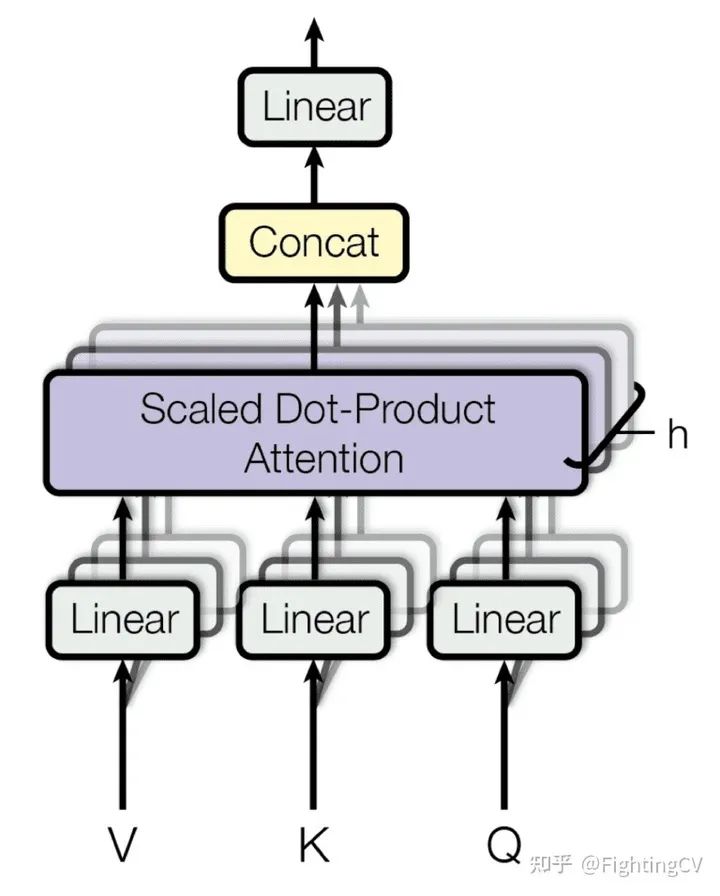
此外,几个注意力层可以并行地堆叠在一起,这被称为多头注意力。每个头在同一个输入的不同线性变换下平行工作,然后将头的输出concat起来产生最终的注意结果。拥有多头模型的好处是每个头可以关注序列的不同元素。
3. 图神经网络
图可以定义为通过连接(或边)链接的一组节点(或顶点)。图是一种通用的数据结构,非常适合在许多现实场景中组织数据的方式。例如,在一个社交网络中,用户可以用图中的节点来表示,他们与朋友的关系可以用边来表示。或者一个分子,其中的节点是原子,边代表它们之间的化学键。对于计算机视觉,我们可以把一幅图像想象成一个图形,其中每个像素都是一个节点,直接连接到它的邻近像素。
目前流行的图注意网络(Graph Attention Networks,GAT) ,它在图卷积网络(GCN)中采用一种自注意机制,后者通过在图形节点上执行卷积来更新状态向量。通过加权滤波器对中心节点和相邻节点进行卷积运算,更新中心节点的表示。GCN 中的滤波器权值可以是固定的或可学习的。
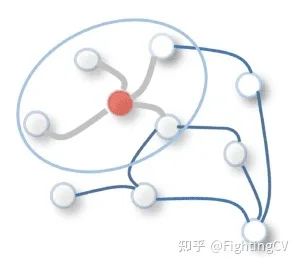
相比之下,GAT 使用注意力分数来给相邻节点赋权。这些注意力得分的计算过程与前面讨论的 seq2seq 任务的计算过程相似: 首先计算两个相邻节点的特征向量之间的对齐得分,然后通过应用 softmax 操作计算注意力得分,最后通过对所有相邻节点的特征向量进行加权组合计算每个节点的输出特征向量(相当于 seq2seq 任务中的上下文向量)。
一旦生成了最终的输出,就可以将其用作后续任务特定层的输入。可以通过图解决的任务可以是不同群体之间单个节点的分类(例如,预测一个人将决定加入几个俱乐部中的哪一个) ; 或者是单个边的分类,以确定两个节点之间是否存在边(例如,预测一个社交网络中的两个人是否可能是朋友) ; 或者甚至是完整图表的分类(例如,预测一个分子是否有毒)。
4. 增强记忆神经网络
在我们已经回顾过的基于注意力的编码器-解码器结构中,编码输入序列的向量集可以看作是外部存储器,编码器写入它,解码器读取它。但是,由于编码器只能写入这个存储器,而解码器只能读取,因此会出现一个限制。
记忆增强神经网络(Memory-Augmented Neural Networks,MANNs)就是针对这一缺陷而提出的新算法。神经图灵机(NTM)是一种类型的 MANN。它由一个神经网络控制器组成,该控制器接受输入产生输出,并对存储器执行读写操作。
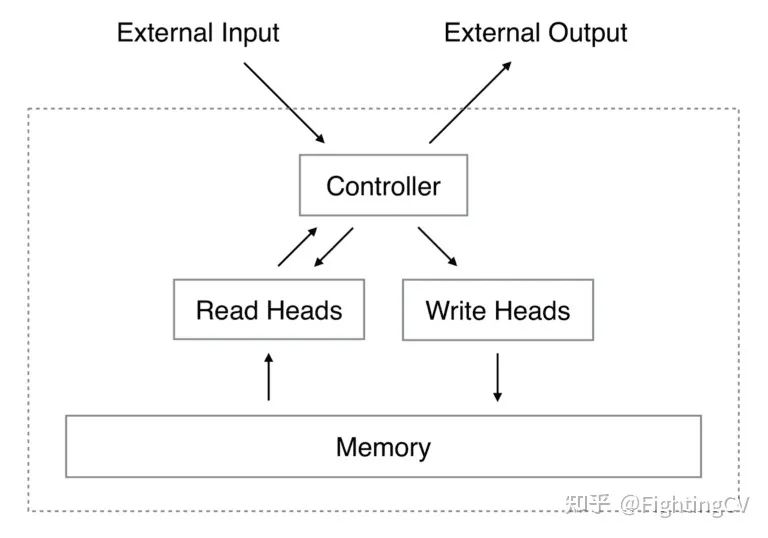
读取头(Read Head)执行的操作类似于用于 seq2seq 任务的注意机制,其中注意力权重表示所考虑的向量在形成输出中的重要性。读取头总是读取完整的内存矩阵,但它是通过注意不同强度的不同内存向量来完成的。
然后,读取操作的输出由内存向量的加权和定义。写头(Write Head)根据注意力和擦除向量中的值擦除内存位置,并通过添加向量写入信息。
人工神经网络应用的例子包括问答和聊天机器人,其中外部存储器存储了大量序列(或事实)数据库,神经网络利用这些数据。注意力机制的作用在从数据库中选择与手头任务相关性更强的事实方面是至关重要的。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~


# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~






