超越谷歌MobileNet!华为提出端侧神经网络架构GhostNet|已开源
乾明 编辑整理
量子位 报道 | 公众号 QbitAI
同样精度,速度和计算量均少于此前SOTA算法。这就是华为诺亚方舟实验室提出的新型端侧神经网络架构GhostNet。
GhostNet的核心是Ghost模块,与普通卷积神经网络相比,在不更改输出特征图大小的情况下,其所需的参数总数和计算复杂度均已降低,而且即插即用。
在ImageNet分类任务中,GhostNet在各种计算复杂度级别上始终优于其他竞争对手,比如谷歌的MobileNet系列、旷视的ShuffleNet系列、IGCV3、ProxylessNAS、FBNet、MnasNet等等。
关于GhostNet的论文已经被CVPR 2020收录,模型与代码也已经在GitHub上开源。华为诺亚方舟实验室是如何做到的?我们根据作者团队的解读,一一看来。
核心理念:用更少的参数来生成更多特征图
通常情况下,为了保证模型对输入数据有全面的理解,训练好的深度神经网络中,会包含丰富甚至冗余的特征图。
如下图所示,ResNet-50中,将经过第一个残差块处理后的特征图,会有出现很多相似的“特征图对”——它们用相同颜色的框注释。
这样操作,虽然能实现较好的性能,但要更多的计算资源驱动大量的卷积层,来处理这些特征图。

在将深度神经网络应用到移动设备的浪潮中,怎么保证性能不减,且计算量变得更少,成为研究的重点之一。
谷歌的MobileNet团队,以及旷视的ShuffleNet团队,最近想了不少办法来构建低计算量的深度神经网络。但他们采取的深度卷积或混洗操作,依旧是在卷积上下功夫——用较小的卷积核(浮点运算)。
华为诺亚实验室的团队没有沿着这条路前进,而是另辟蹊径:
“特征图对”中的一个特征图,可以通过廉价操作(上图中的扳手)将另一特征图变换而获得,则可以认为其中一个特征图是另一个的“幻影”。
这是不是意味着,并非所有特征图都要用卷积操作来得到?“幻影”特征图,也可以用更廉价的操作来生成?
于是就有GhostNet的基础——Ghost模块,用更少的参数,生成与普通卷积层相同数量的特征图,其需要的算力资源,要比普通卷积层要低,集成到现有设计好的神经网络结构中,则能够降低计算成本。
具体的操作在这里就不详细叙述了,如果你有兴趣,可以去看下论文(地址在文末)。
构建新型端侧神经网络架构GhostNet
利用Ghost模块的优势,研究团队提出了一个专门为小型CNN设计的Ghost bottleneck(G-bneck)。其架构如下图所示,与ResNet中的基本残差块(Basic Residual Block)类似,集成了多个卷积层和shortcut。
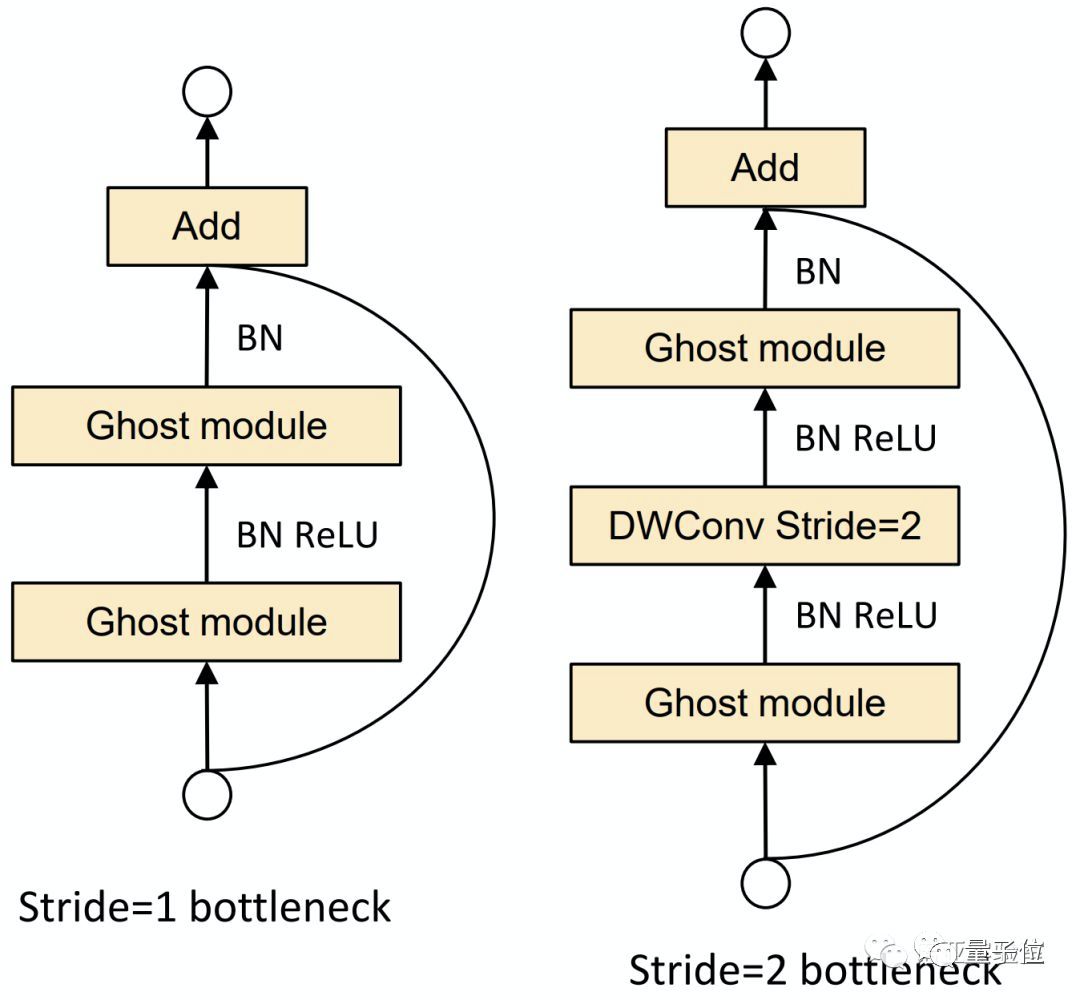
Ghost bottleneck主要由两个堆叠的Ghost模块组成。第一个用作扩展层,增加了通道数。第二个用于减少通道数,以与shortcut路径匹配。然后,使用shortcut连接这两个Ghost模块的输入和输出。
研究团队表示,这里借鉴了MobileNetV2中的思路:第二个Ghost模块之后不使用ReLU,其他层在每层之后都应用了批量归一化(BN)和ReLU非线性激活。
这里说的Ghost bottleneck,适用于上图Stride= 1情况。对于Stride = 2的情况,shortcut路径由下采样层和Stride = 2的深度卷积(Depthwise Convolution)来实现。
此外,而且出于效率考虑,Ghost模块中的初始卷积是点卷积(Pointwise Convolution)。
在Ghost bottleneck的基础上,研究团队提出了GhostNet——遵循MobileNetV3的基本体系结构的优势,用Ghost bottleneck替换MobileNetV3中的bottleneck。
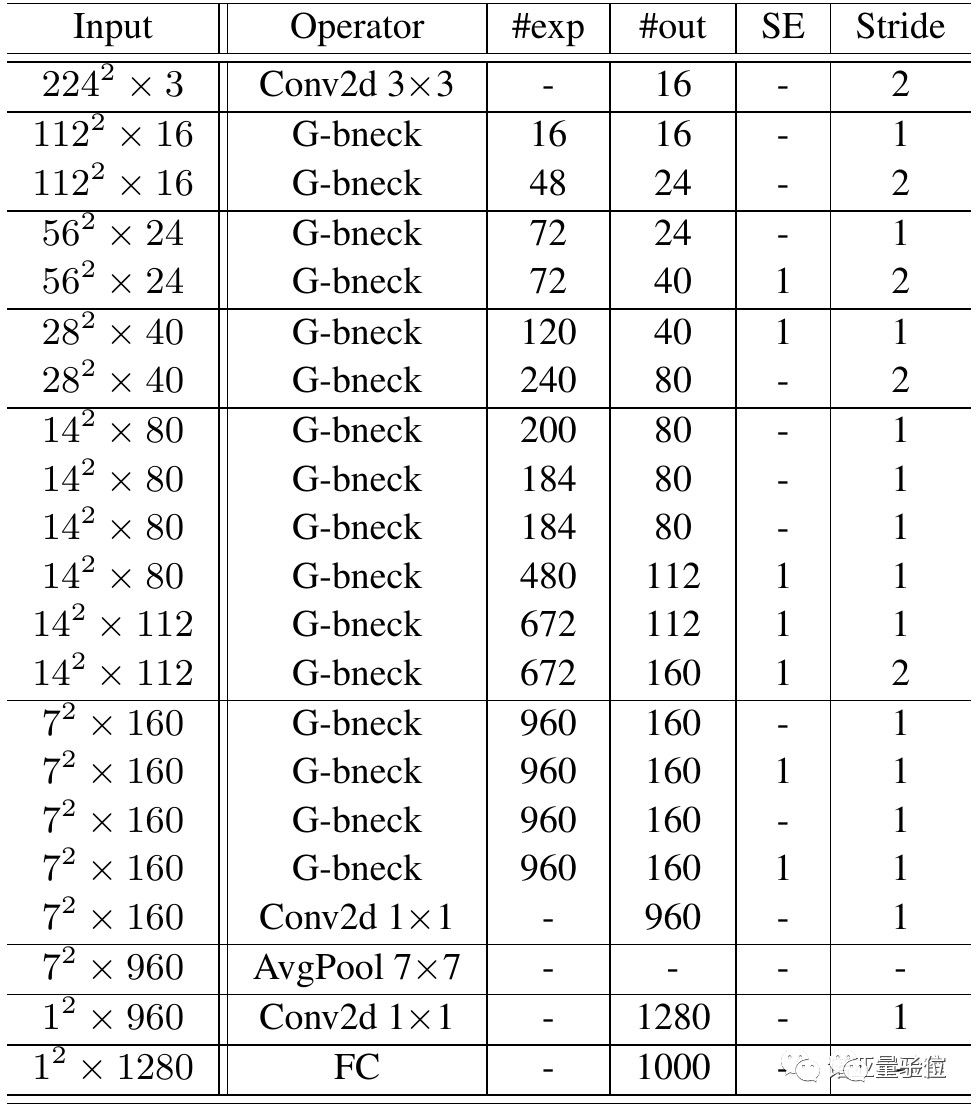
第一层是具有16个卷积核的标准卷积层,然后是一系列Ghost bottleneck,通道逐渐增加。
Ghost bottleneck根据输入特征图的大小分为不同的阶段,除了每个阶段的最后一个Ghost bottleneck是Stride = 2,其他所有Ghost bottleneck都以Stride = 1进行应用。
最后,会利用全局平均池和卷积层将特征图转换为1280维特征向量以进行最终分类。SE模块也用在了某些Ghost bottleneck中的残留层。与MobileNetV3相比,这里用ReLU换掉了Hard-swish激活函数。
研究团队表示,这里的架构只是一个基本的设计参考,进一步的超参数调整或基于自动架构搜索的Ghost模块将进一步提高性能。
ImageNet分类任务超过谷歌MobileNet
如此思路设计出来的神经网络架构,性能到底如何?研究团队从各个方面验证。
首先,在CIFAR-10数据集上,他们将Ghost模块用在VGG-16和ResNet-56架构中,与几个代表性的最新模型进行了比较。
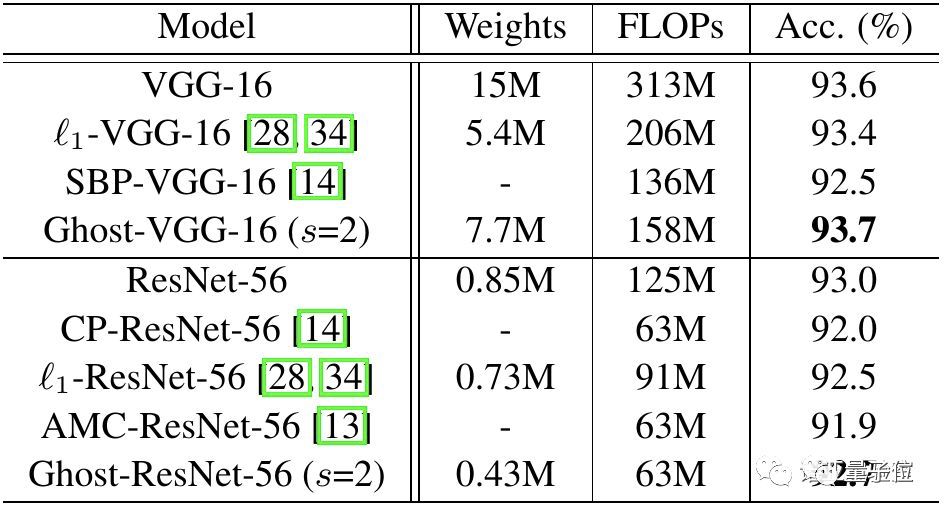
Ghost-VGG-16 ( s=2)以最高的性能(93.7%)胜过竞争对手,但算力消耗(FLOPs)明显减少。在比VGG-16小得多的ResNet-56上,基于Ghost模块的模型,将计算量降低一半,还能获得可比的精度。
在论文中,他们提供了Ghost模块生成的特征图。下图展示了Ghost-VGG-16的第二层特征,左上方的图像是输入,左红色框中的特征图来自初始卷积,而右绿色框中的特征图是经过廉价深度变换后的幻影特征图。

研究团队表示,尽管生成的特征图来自原始特征图,但它们之间确实存在显着差异,这意味着生成的特征足够灵活,可以满足特定任务的需求。
其次,在ImageNet数据集的分类任务上,他们测试了整个神经网络架构的性能,衡量的指标,是ImageNet验证集上single crop的top-1的性能。
下图展示了GhostNet与现有最优秀的几种小型网络结构的对比,参赛选手包括MobileNet系列、ShuffleNet系列、ProxylessNAS、FBNet、MnasNet等。
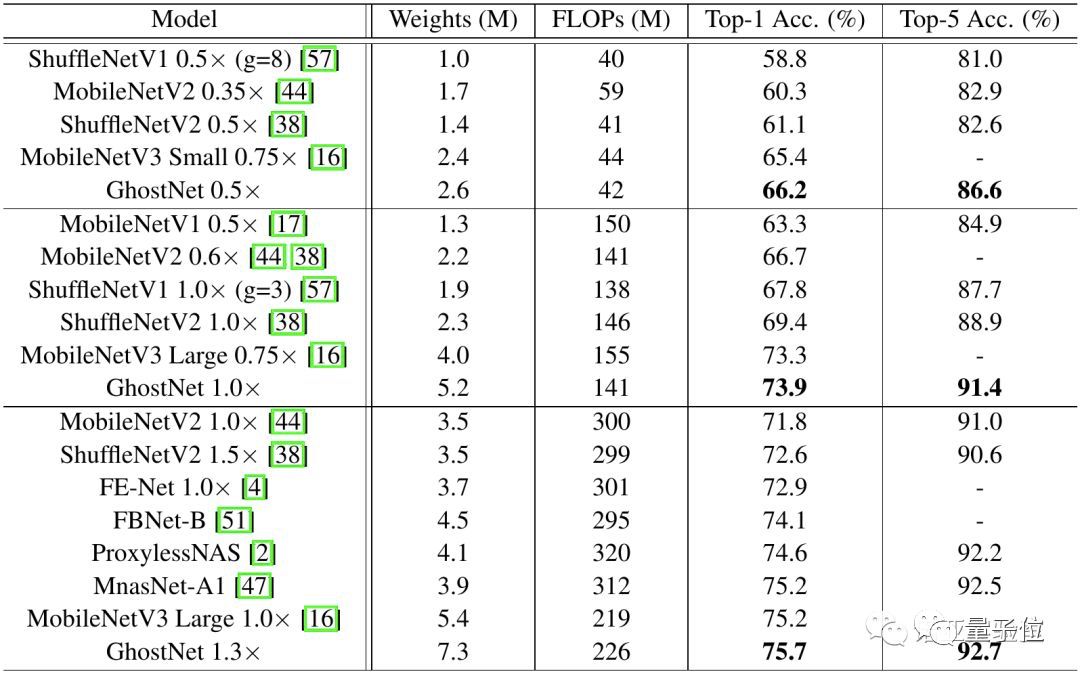
模型分为3个级别的计算复杂性,即~50,~150和200-300MFLOPs。通常FLOPs较大,这些小型网络的准确性会更高——表明了它们的有效性。
GhostNet在各种计算复杂度级别上始终优于其他竞争对手。研究团队解释称,这主要是因为GhostNet在利用计算资源生成特征图方面效率更高。
由于GhostNet是为移动设备设计,他们还使用TFLite工具,遵循MobileNet中的常用设置,使用Batch size为1的单线程模式,在基于ARM的手机(华为P30 Pro)上进一步测量GhostNet的实际推理速度,并与其他模型进行比较。
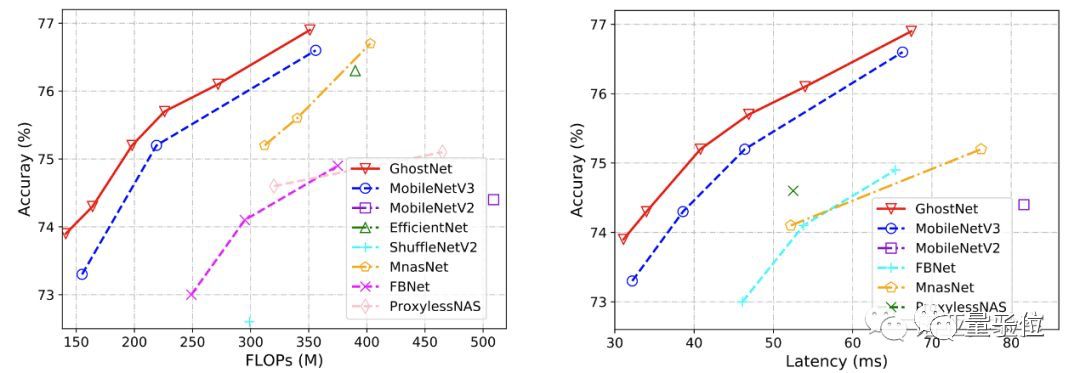
如上图所示,与具有相同延迟的MobileNetV3相比,GhostNet大约提高了0.5%的top-1的准确性,另一方面GhostNet需要更少的运行时间来达到相同的精度。
例如,精度为75.0%的GhostNet仅具有40毫秒的延迟,而精度类似的MobileNetV3大约需要46毫秒来处理一张图像。
因此,研究团队表示,GhostNet总体上胜过其他最新模型,例如谷歌MobileNet系列,ProxylessNAS,FBNet和MnasNet等等。
华为诺亚方舟实验室研究成果
这一研究的核心作者,主要来自于华为诺亚实验室。
第一作者是韩凯,此前研究机构为北京大学。第二作者是王云鹤,同样毕业于北京大学。第三位作者是田奇,诺亚方舟实验室首席计算机视觉科学家,也是这篇稿件的通讯作者。
这篇论文,是华为计算机视觉方向的最新研究成果之一。
此前在CVPR 2020年放榜时,王云鹤就曾在知乎上透露,其团队一共有7篇论文被收录。
他说,这些是他们小组辛辛苦苦攒了大半年的工作。emmm…
如果你对这一研究感兴趣,可以收好下面的传送门:
论文地址:
https://arxiv.org/abs/1911.11907
项目开源地址:
https://github.com/huawei-noah/ghostnet
— 完 —
疫情防控期间,家里的小朋友有点无聊?
推荐给7-12岁的小朋友,一个好玩又有趣的事情:在家学习编程。这是一个绝佳的逻辑思维、数理思维、计算思维的提升方式。
柯基少儿编程入门课限时优惠招生,一共七个课时,现在只需48元,而且学完课程学费全返!
欢迎爸爸妈妈们扫码查看、报名:
在家学编程 | 柯基编程双师互动课

AI内参 | 关注趋势,把握机遇
内参新升级!拓展优质人脉,获取最新AI资讯&论文教程,欢迎加入AI内参社群一起学习~


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !

