让 NLU 工具助力新冠肺炎科学文献研究
文 / Google Research 自然语言理解团队研究员 Keith Hall

受新冠肺炎 (COVID-19) 影响,世界各地的科学家和研究人员都投入了大量精力,旨在更好地理解并战胜这种疾病。诚然,目前可观的研究数量非常振奋人心,但这同时也可能导致科学家和研究人员难以跟上新研究公布的快节奏。针对“我们已经有多少新冠肺炎确诊病例?”这类问题,传统搜索引擎在查找一般的实时信息时或许可圈可点,但可能会难以理解 研究型查询 背后的含义。此外,在使用基于关键字的传统方法搜索现有新冠肺炎科学文献语料库时,可能会难以准确找到复杂查询的结果。
为协助解决此问题,我们发布了 COVID-19 Research Explorer,这是基于新冠肺炎开放研究数据集 (CORD-19) 而构建的语义搜索接口,其中涵盖了 5 万多份期刊文章和预印本资料。我们希望这款工具可以帮助科学家和研究人员更高效地浏览文章,快速定位到新冠肺炎相关问题的答案或证据。
发布 COVID-19 Research Explorer
https://covid19-research-explorer.appspot.com/新冠肺炎开放研究数据集
https://pages.semanticscholar.org/coronavirus-research
语义搜索
助力打造此工具的一项关键技术是语义搜索。语义搜索不仅可以捕获查询和文档之间的术语匹配,还可理解语义是否与用户查询背后的真实意图存在关联。
假设我们想要查询:“调控 ACE2 表达的是什么?”这个问题看上去似乎很简单,但其中的某些短语会给仅依赖于文本匹配的搜索引擎带来混淆。例如,“调控 (Regulates)”一词可能涉及到生物学过程。传统的信息检索 (IR) 系统通过使用查询扩展等技术来减轻这种混淆,而语义搜索模型的目标是对这些关系进行隐式学习。
调控 ACE2 表达的是什么?
https://covid19-research-explorer.appspot.com/results?mq=What%2520regulates%2520ace2%2520expression%2520%253F
同样,语序也很重要。ACE2(Angiotensin Converting Enzyme-2,血管紧张素转化酶-2)本身能够调控某些生物学过程,但我们的问题其实在问是什么在调控 ACE2。如果只对术语进行匹配,就无法区分“调控 ACE2 的是什么”和“ACE2 调控了什么”。传统 IR 系统采用 n-gram 术语匹配等技巧,但语义搜索方法则主要致力于对语序和语义进行建模。
我们使用的语义搜索技术由 BERT 提供支持,近期已部署至 Google 搜索以提升检索质量。
近期已部署
https://www.blog.google/products/search/search-language-understanding-bert/
在开发 COVID-19 Research Explorer 时,我们面临的挑战是:生物医学文献所使用的语言与提交给 Google 的查询类型截然不同。为了训练 BERT 模型,我们需要监督,即查询示例及其相关文档和摘要。尽管我们依靠 BioASQ (http://bioasq.org/) 产生的优秀资源进行微调,但此类由人工整理的数据集往往规模不大。神经语义搜索模型需要大量训练数据。为了扩充由人工整理的小型数据集,我们利用查询生成的研究成果建立了生物医学领域问题和相关文档的大型综合语料库。
问题和相关文档的大型综合语料库
https://arxiv.org/pdf/2004.14503.pdf
具体来说,我们使用大量通用领域的问题-答案对来训练编码器-解码器模型(如下图中 a 部分所示)。这种神经架构通常用于机器翻译 (https://translate.google.com/) 之类的任务,这种任务要求对一段文本(例如一个英语句子)进行编码,然后生成另一段文本(例如一个法语句子)。在研究过程中,我们对模型进行训练,使其能够将答案段落转换为问题段落题(或查询)。接着,我们从集合的每个文档中提取段落(在本例中为新冠肺炎),然后生成相应的查询(b 部分)。随后,我们将这些合成的查询-段落对用作监督,以此来训练我们的神经检索模型(c 部分)。
编码器-解码器模型
https://towardsdatascience.com/understanding-encoder-decoder-sequence-to-sequence-model-679e04af4346
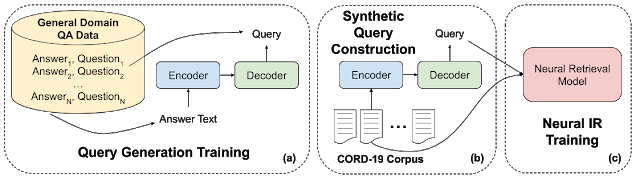
合成查询的构建过程
然而,在某些示例中,我们发现神经模型的性能不如基于关键字的模型。原因正是大多数人工智能和心理语言学领域所熟知的记忆-泛化连续特征。诸如 Term Frequency–Inverse Document Frequency (tf-idf) 等基于关键字的模型实质上就是记忆器。它们通过查询记忆术语,然后检索包含这些术语的文档。另一方面,神经检索模型学习有关概念和含义的泛化,并尝试根据泛化结果进行匹配。有时候,在对精度要求较高的查询中,这些模型也可能会过度泛化。例如,如果我查询“调控 ACE2 表达的是什么?”,则可能希望此模型对“调控”这个概念进行泛化,而不是对 ACE2 进行首字母缩略词扩展。
记忆-泛化连续特征
https://arxiv.org/pdf/2002.03206.pdf
术语-神经检索混合模型
为提升系统性能,我们构建了一个术语-神经检索混合模型。我们发现一个非常重要的结果,基于术语的模型和神经模型都可以转化为向量空间模型。换言之,我们可以在查询和文档同时进行编码,然后将查询处理为搜寻与查询矢量最相似的文档矢量,也称为 K 最近邻检索。要大规模开展此项工作,我们需要进行大量研究和工程设计,但这样就能通过简单的机制来组合多种不同的方法。最简单的方法是将向量与权衡参数进行组合。
研究和工程设计
https://towardsdatascience.com/comprehensive-guide-to-approximate-nearest-neighbors-algorithms-8b94f057d6b6
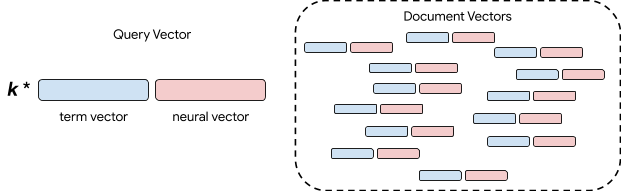
术语和神经检索的混合
如上图所示,蓝色方框是基于术语的向量,而红色方框是神经向量。我们通过连接这些向量来表达文档。同时,我们将两个向量连接后进行查询,但会控制匹配精确术语与神经语义的相对重要性。这一步通过权重参数 k 完成。尽管也可以使用更复杂的混合方案,但我们发现,这种简单的混合模型显著提升了生物医学文献检索基准测试的检索质量。
可用性和社区反馈
COVID-19 Research Explorer 的 Alpha 版现已免费提供给研究社区使用。在未来数月内,我们还将对此版本的易用性进行大量改进,请关注相关信息。欢迎您试用 COVID-19 Research Explorer (https://covid19-research-explorer.appspot.com/),也希望您通过网站上的反馈渠道与我们分享您的任何建议或意见。
致谢
这项成果离不开许多人的辛勤工作,包括但不限于以下人士(按姓氏字母排序):John Alex、Waleed Ammar、Greg Billock、Yale Cong、Ali Elkahky、Daniel Francisco、Stephen Greco、Stefan Hosein、Johanna Katz、Gyorgy Kiss、Margarita Kopniczky、Ivan Korotkov、Dominic Leung、Daphne Luong、Ji Ma、Ryan Mcdonald、Matt Pearson-Beck、Biao She、Jonathan Sheffi、Kester Tong、Ben Wedin
更多 AI 相关阅读:





