学习二值编码只为高效的时尚套装推荐

题目: Learning Binary Code for Personalized Fashion Recommendation
会议: CVPR2019
论文: https://paperswithcode.com/paper/learning-binary-code-for-personalized-fashion
论文代码: https://github.com/lzcn/Fashion-Hash-Net
1 Motivation
随着以时尚为中心的社交网络和在线购物的兴起,数以百万计的用户共享并发布与时尚相关的日常活动。社区中的用户每天创造大量的时尚套装,因此从这些海量数据集中挖掘理想的服装非常具有挑战性,但对于这些在线时尚社区的发展至关重要。与此同时,每种服装类别中的衣服数量均随项目数量呈指数增长。存储和检索效率对于如今的时尚推荐系统也是至关重要的。基于这两项挑战:推荐性能和推荐效率,作者提出了一个集效率和性能为一体的个性化时尚推荐模型。
2 Model
下图为论文所提模型的整体框架图,其中有三个重要模块:1)用来提取特征的特征网络(Feature network)2)学习哈希码的类型依赖的哈希模块(Hashing modules)3)预测偏好分数的打分模块(The matching block)。
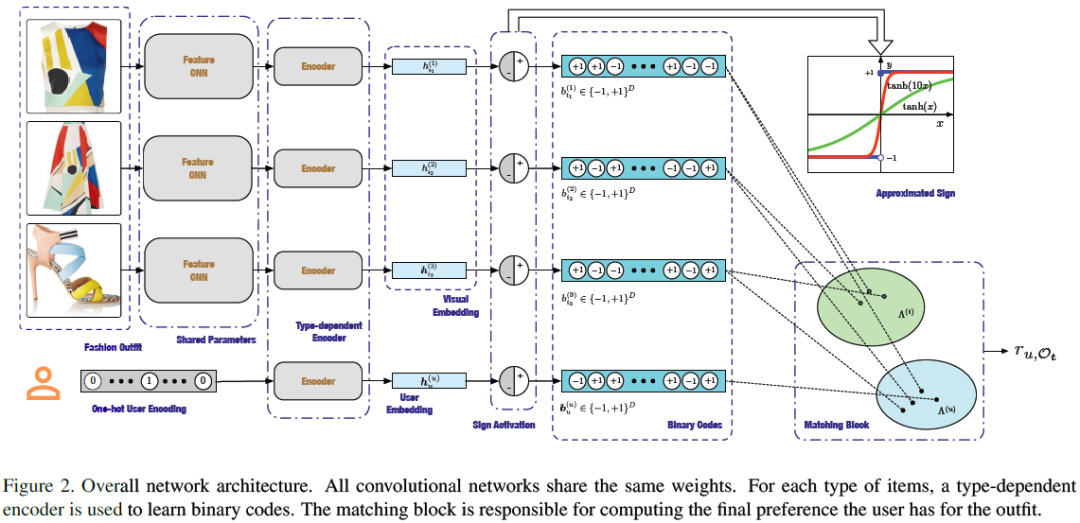
模型的输入为用户的one-hot编码和图片特征,图片特征通过卷积神经网络来提取;哈希模块是两层全连层后加了一个符号函数;用户的编码器是一层全连层。
2.1 Matching block
由于推荐场景为时尚套装推荐,因此进行推荐时,不仅需要考虑一个时尚套装内物品的兼容性(比如推荐时,在一个套装内包含两件上衣就很不合理)同时还要考虑用户对物品的偏好。因此,基于这一直觉,用户
对套装
预测分数为: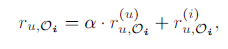
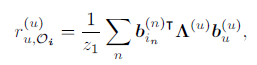
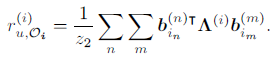
2.2 Learning to Hash
由于离散限制,直接优化哈希码较为困难,因此,我们将上述公式改写为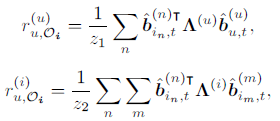
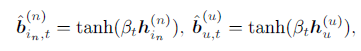
2.3 Objective Function
除了图片之外,提供语义信息的文本描述对于兼容性建模也是非常有用的,作者使用和图片同样的方式将文本信息转换为二进制码,并得到预测分数。文中用
和
分别表示来自不同模块的二进制码,其中
表示视觉信息,
表示文本信息。因此,模型最终预测用户
对套装
的偏好分数为: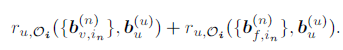
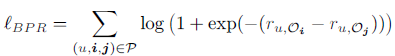
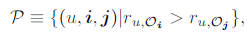
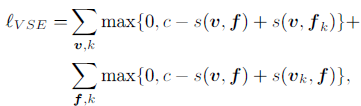
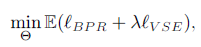
3 Experiments
3.1 Datasets
由于现有的数据集要么太小,要么缺少用户信息,都不适用于个性化时尚推荐场景,因此作者从Polyvore网站上收集了一个新数据集,数据集信息如表1所示: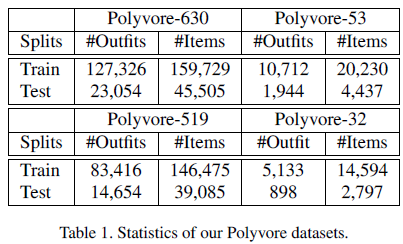
3.2 Experimental Results
通过实验对比发现,论文提出的方法相比其他方法在AUC上有6.6%-12.1%的提升,NDCG有了19.56%-26.56%的提升。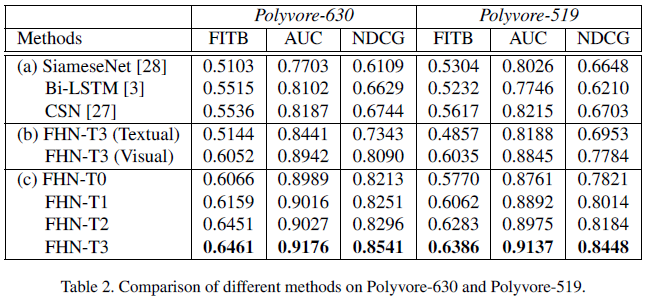

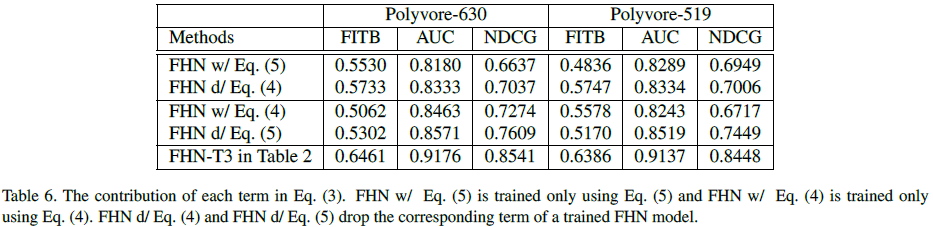
(更多细节可参考原文)
小结
在这项工作中,作者提出了如何利用哈希技术来进行高效的个性化时尚套装的推荐。通过大量的实验,展示了论文所提模型的性能,即使是利用了简单的框架并且用户和物品的特征均为哈希码。
推荐阅读




