史上最严苛隐私数据保护法5月生效!

而再早一点的 Facebook泄漏用户数据的事件发酵到今天,已然成了社交媒体史上最大的丑闻,将互联网时代让用户深深忧心但不敢轻易揭开的事实——数据隐私安全的漏洞完全暴露出来。这些都为数据安全工作领域敲响了警钟:此类事件不是第一次发生,也不会止于这一次,应该怎么做才能尽量避免它再次发生呢?
据悉,欧盟已经抢先采取行动,对 GDPR(General Data Protection Regulation,欧盟通用数据保护条例)做了号称史上最严格的一次修订,将于今年 5月 25日正式生效。AI前线关心的是,GDPR做了哪些改动?到底会对大数据、AI科技公司和开发人员带来什么影响?普通民众的个人隐私将得以保全吗?为此,AI前线对这一法案进行了深入研究,我们发现,虽然条例中仍存在许多不确定因素,但它将影响的可不只是欧盟成员国人士。
更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
经过四年的准备和辩论之后,GDPR 终于在 2016 年 4 月 14 日获得了欧盟议会的批准,取代了 1995 年的数据保护指令 95/46/EC,旨在调整整个欧洲的数据隐私法律,保护和赋权所有欧盟公民的数据隐私,并重塑整个地区组织处理隐私数据的方式。该条例对隐私保护条例做出了 20 年来最大的改动,从 2018 年 5 月 25 日起生效,届时违规组织可能面临重罚。
官网链款:https://www.eugdpr.org/key-changes.html
GDPR 的目标是在大数据时代保护所有欧盟公民免受隐私和数据泄露的侵害。该条例的数据隐私关键原则仍符合此前的 1995 年指令,但监管政策有了诸多改变。以下是 GDPR 关键变化,以及它对商业影响的详细说明。
不管公司在不在欧盟,不管数据物理地址在哪里,只要从事涉及欧盟公民个人数据处理业务的企业和机构,包括跨国公司(如 BAT 等所有互联网企业)都得遵守 GDPR。
可以说,GDPR 的最大改动是地域适用性扩大,该修订法案生效后将适用于所有涉及欧盟个人数据处理业务的公司(不管公司所处位置)。此前,该指令的地域适用性并不明确,而 GDPR 使之变得非常明确——适用于所有在欧盟的个人数据服务商和处理主体,无论数据处理过程是否在欧盟进行。GDPR 还将适用于未在欧盟设立公司的服务商或个人数据处理公司,只要其活动涉及:向欧盟公民提供商品或服务(不论是否需要付款),以及监测在欧盟内发生的活动。此外,处理欧盟公民数据的非欧盟企业也必须在欧盟设立代表处(人)。
违反 GDPR 的组织可能会面临最高全球年营业额 4%或 2000 万欧元(或更高)的罚款,包括“云”业务。
根据 GDPR,违反 GDPR 的组织可能会面临最高全球年营业额 4%或 2000 万欧元(或更高)的罚款。如果没有获得客户同意就处理该用户数据,或未在设计阶段实践保护隐私(Privacy by Design )的核心概念,公司将被处以最高罚款。另外,罚款是分等级的:例如因记录不清晰,不通知监管当局和数据主体违约或不进行影响评估,违法公司会被罚款 2%(第 28 条)。值得注意的是,这些规则也适用于服务商和处理器——这意味着“云”业务也将包含在 GDPR 的监管范围之内。
使用数据前必须征得的用户同意,用户可以撤回同意,而且还要让用户看得懂条款和条件、知道怎么撤回同意。
新法规强调用户同意的重要性,公司不允许在用户同意条款中使用难以理解的条款和条件,而必须以易于理解和访问的语言和形式提供,同意条款必须清晰明确,并与其他事项区分开来。另外,撤回同意也应与授权同意程序的操作难度一致。
根据 GDPR,在数据泄露可能“导致个人权利和自由风险”的所有成员国,如果违反规定必须通知用户成为强制性要求。违规公司必须在第一次意识到违规之后 72 小时内完成通知工作,同时要求数据处理器在第一次意识到数据泄露之后“通知他们的客户和服务商”,不得“无故拖延”。
GDPR 下,数据主体的部分扩展权利包括数据主体有权从数据管理员处确认是否正在处理与其有关的个人数据,用途以及使用地点。此外,服务商应以电子格式免费提供个人资料的副本。这一变化是数据透明度化和数据主体授权的一个巨大变化。
也称为数据擦除,被遗忘权使数据主体有权让数据服务商擦除他 / 她的个人数据,停止进一步传播数据,并可以要求第三方停止处理数据。根据第 17 条规定,删除数据的条件包括数据已与原始处理目的不再相关,或者数据主体撤回同意。还应该注意的是,这项权利要求管理者在考虑这些请求时将主体的权利与“公众对数据可用性的兴趣”进行比较。
GDPR 新增了数据的可迁移性——数据主体有权接收关于他们的个人数据,这些数据以前曾以“通用和机器可读的格式”提供,届时,数据主体将有权将数据迁移到其他服务商。
隐私设计作为一个概念已经存在多年,但它只是成为 GDPR 的一部分。隐私设计的核心在于要求系统在设计阶段就应包含数据保护的考虑,而不是之后增加。更具体地说,“控制人应当...... 以有效的方式采取适当的技术和组织措施...... 以满足本法规的要求并保护数据主体的权利”。第 23 条要求管制人员只保留和处理完成其职责绝对必要的数据(数据最小化),并将个人数据的访问限于需要处理数据的人员。
目前,服务商需要向当地数据处理局(Data Processing Agency)告知其数据处理活动,这对于跨国公司来说可能是一个官僚主义的噩梦,因为大多数成员国都有不同的通知要求。根据 GDPR,他们不需要向每个当地的 DPA 提交数据处理活动的通知 / 注册,也不需要根据示范合同条款(MCC)通知 / 获得转让批准。相反地,如下所述,他们应当保存内部记录,并且仅对核心活动处理操作的服务商和处理器进行资料保护长 Data protection officer(DPO)强制任命,这些处理操作需要对数据主体进行大规模,或与刑事定罪和犯罪有关的特定数据类别进行长期和系统的监控。重要的是,这些 DPO:
必须具有专业素质,特别是精通关于数据保护法律和惯例的专业知识
可以是工作人员或外部人员
必须向相关 DPA 提供联系方式
必须获得适当的资源来执行他们的任务并更新专业知识
必须直接向最高级别的管理层报告
不得执行可能导致利益冲突的任何其他任务
除了上述地域上的影响,即所有在欧盟开办业务的涉及数据处理的企业(包括跨国企业)都将纳入 GDPR 监管范围之内,大数据、AI 开发人员和公司还会受到其他的影响。
不久前,人工智能研究领域大牛——华盛顿大学的 Pedro Domingos 教授,用他的推文掀起了一场风暴。

“从 25 日起,欧盟将要求算法解释输出的原理,届时深度学习将变得非法。”
——Pedro Domingos
事实上,GDPR 真的要求解释机器学习算法原理吗?关于这一点其实还是有一些争议的。
据专家分析,GDPR 将对机器学习领域产生重大影响的规定可能是“算法解释的权利”(right to explanation),即数据主体有权要求数据服务商解释机器学习进行自主决策的算法原理。
虽然现在已经有一些算法,如 LIME:Local Interpretable Model-Agnostic Explanations,可以解释机器学习分类器的预测原理,但它并不是万能的,解释算法原理仍然是一项极具挑战的事。
一位欧盟律师,同时是牛津大学大数据、AI& 机器人学院的研究员 SandraWachter5 对 GDPR 条款做了一些分析。
她说道,GDPR 要求数据公司采取适当的措施来保护数据主体的权利自由和合法利益。这些措施应该包括数据主体有权获得人为干预、表达观点和对对决策提出异议的权利。
她的观点是,GDPR 第 15 条意味着一种更加泛化的监督形式,而不是一项要求系统对某一决策原理进行解释的权利。因此,GDPR 中关于解释的权利不具有法律约束力,但公司可以自愿提供。在她的文章中提到,“数据服务商可以各种方式提供解释,目前至少有两种可能的算法解释:“系统功能”的解释和关于单独决策“基本原理”的解释。解释用于评估信誉度或设定利率(系统功能)的算法方法,与解释某个特定比率的依据或拒绝信用卡申请的“原因”不同。
她说道,她与图灵研究人员 Brent Mittelstadt 博士和 Luciano Floridi 教授一起研究了这一说法。“不幸的是,与我们所希望的相反,研究表明,GDPR 可能仅要求向个人告知有关自动决策机制和“系统功能”的存在,但没有关于要求解释决策基本原理的规定。事实上,在整个 GDPR 中,“解释权”在规定中只提到过一次,71 条缺乏构成独立权利的法律效力(这条法令旨在解释监管框架的运作部分不清晰时提供指导)。”
立法人员将“解释权”放在 71 条中,而且欧洲议会提出的使这项权利具有法律约束力的建议未获通过,这表明欧洲立法者不希望让这一想法与 GDPR 第 22 条具有相等的法律约束力。当然,这并不意味着数据公司不能自愿提供解释,或者未来在这条法令之上增加这样的内容。
对于这种情况,她认为一种可行的解决办法是反设事实(Counterfactuals):比如你因收入为 30000 欧元而贷款被拒,但当你的收入为 45000 欧元时就会被接受。
在论文 Counterfactual Explanations Without Opening the Black Box: Automated Decisions and the GDPR 中,作者 Sandra Wachter,Brent Mittelstadt 和 Chris Russell 解释了在使用高度复杂的系统时,我们如何给人们提供有意义的解释,而无需了解算法的内部逻辑。而且,使用反设事实也不太可能侵犯商业秘密。
然而,并不是所有人都同意她的说法。例如 Andrew D. Selbst 和 Julia Powles 在 Meaningful information and the right to explanation 一文中说道:“尽管 GDPR 没有关于“解释权利”的明确条款,但并不是无中生有。第 13-15 条规定数据主体拥有知悉自动化决策“有关所涉逻辑的有意义信息”的权利。无论是否使用该词语,这都是一种解释权。”
看来,围绕“解释的权利”还大有讨价还价的空间存在,律师们可有的忙了。
根据新规中新增加的数据转移权规定,用户可随时将个人数据迁移至新的服务商,这样一来,谷歌、Facebook、Twitter 等严重依赖用户数据进行创新服务的公司将是巨大的打击;被遗忘权规定,用户有权要求数据服务商删除个人数据,且不能过分延长数据保存时间,像依赖 cookie 数据收集、广告投放的技术公司将受损失;算法解释权规定,用户有权要求服务商解释算法自动决策的原理,并有权在对解释不满意时退出。
新规规定,数据服务商必须以简单易懂的语言列明用户同意条款,使用用户数据需经过用户同意。另外也有人认为,即使没有明确规定“解释权”,但 13-15 条里有关用户“有权获得自动决策相关逻辑有用信息”的条文实际上就是一种“解释权”,这是产生矛盾的地方。从这个角度解读,GDPR 对 AI 企业可开发人员的影响就不可小觑了,与 SandraWachter 所说的 GDPR 中并没有明确规定的说法相悖,这可能意味着,AI 公司在处理诸如 AI 黑箱问题时需征求用户同意,相关 AI 应用可能也不再合法。
其次,AI 公司还面临 AI 黑箱(black-box problem)的问题。目前,大多数 AI 公司严重依赖大数据,通过人工智能或深度学习的方法获利,而当前业界普遍认为神经网络存在黑箱问题,科技公司需要花费巨大的成本解决解释网络的工作原理。
更进一步说,人工智能目前火热的发展势头,可能都会因 GDPR 而遭受打击。
不久前,Facebook 抓取 5000 万用户隐私信息的事件已经演变成一个巨大的丑闻,事发后不仅 Facebook 股价大跌,CEO 马克•扎克伯格 (Mark Zuckerberg) 都亲自发文出面为这家超级社交网络公司挽尊。最新消息透露,如果美国联邦贸易委员会(FTC)最终裁决 Facebook 违反协议,Facebook 可能将会面临巨额罚款,每泄露一个用户的信息,就要罚款 4 万美元。按照 5000 万用户的基数算的话,Facebook 可能要面临 2 万亿美元的巨额罚款。3 月 21 日,扎克伯格在接受美国有线新闻网 (CNN) 采访时表示,针对最近媒体对剑桥分析 (Cambridge Analytica) 收集逾 5000 万个 Facebook 账户的数据的报道,他愿意就美国政府的任何相关调查作证,他不反对他的社交媒体公司受到监管。但是在拿出是行动之前,用户的怒火是无法平息的。
在国内,今日头条使用麦克风窃取用户隐私的事件热度仍然不减,虽然今日头条声称实现“麦克风窃取用户隐私的技术还有些遥远“,但已经有声纹处理专家和生物识别专家站出来指证,“类似的功能,十年前的技术就能实现,CIA、NSA 早就在使用了”。
在大数据时代,我们的信息早已暴露在互联网中,一款软件就可以将你的个人信息传递到世界的各个角落。面对严峻的个人隐私信息泄漏现状,我们可以从技术和法律监督层面上做出更多努力。得益于即将生效的 GDPR,目前十分流行的第三方支付工具 PayPal,在 2018 年 1 月公开了可以分享该软件用户个人数据的第三方公司和机构名单,为用户数据用途公开透明化开了个好头。
这份长长的名单着实让人震惊,第三方包括支付处理方、审计方、客户服务外包商、信用和防欺诈机构、金融产品公司、商业合作伙伴等不下数千家公司,是真正的“客户不出门,数据天下传”。当你在这款软件上登记注册下你的个人信息时,远在天边的各种公司和机构的电脑、云端中已经存下了你的档案,包括你的姓名、出生日期、地址、电子邮件、账户信息、信用状况等,而没有人能保证,这些信息还会流转到其他人手上,相信经常收到陌生推销电话和信息的朋友们都深有体会。
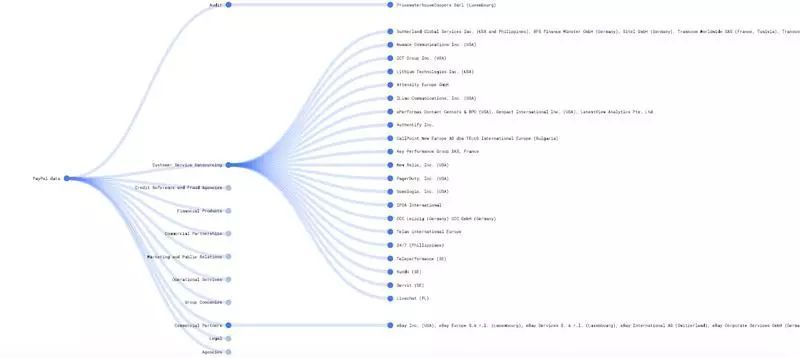
想了解 PayPal 如何使用用户数据、分享给哪些第三方,可以点击下面的链接查看数据可视化效果:
https://rebecca-ricks.com/paypal-data/
PayPal 公布共享用户信息的第三方完整名单链接:
https://www.paypal.com/ie/webapps/mpp/ua/third-parties-list
当然,这对于用户来说是个好消息,但对公司和开发人员来说却是一个巨大的负担。
除了技术手段,法律监管也是解决用户数据隐私的方法之一。然而,法律有时会撒下一张过大的网,难免会造成打击面过广的尴尬境地。
例如,从 2016 年就已经存在,近日在法律程序上有所进展的欧盟版权方针(EU Copyright Directive)。该提案要求托管内容的所有平台检查所有上传的内容有无侵犯版权。欧盟的这一项版权提案旨在防止媒体盗版,用意是好的,但可能会因为撒网过大,给使用代码仓库 GitHub 等服务的广大开发者带来严重影响,因为按照新法律 GitHub 将被迫过滤代码,导致软件的成本更高昂。此外,新法规还要求代码共享平台删除没有许可证的代码。
该提案的第 13 条专门涉及自动内容过滤器的实施,这也是让 GitHub 及其他欧洲程序员们深为担忧的部分。
第 13 条规定:“如果提供商存储用户上传的大量作品或其他主题,并允许公众访问这些内容”,须与版权所有者合作,实施措施以防止内容被非法共享。 “那些措施(比如使用有效的内容识别技术)应该是适当的、相称的,”该提案表示。第 13 条进一步提到了内容识别技术是发现版权侵犯行为的最佳实践的一部分,因此过滤器很可能成为新版权法最终条文的一部分。然而,哪些类型的内容要过滤却没有明确规定。
如果新法规实施,代码共享平台就需要招聘众多的人员帮助做好版权合规工作,通过使用 Git 及其他软件工具而共享的大量内容需要 GitHub 等面向开发的平台公司实施自动化过滤机制,确定什么内容可以共享、什么不可以共享。
GitHub 认为,对于软件开发者而言,由于应用程序常常牵涉许多不同的贡献者和不同层的代码(这些代码也许采用不同的许可证),可能出现误报或漏报这个问题显得尤为突出。
正如 GitHub 指出的那样,自动过滤代码对于独立程序员和大企业程序员来说都是毁灭性的,他们面临的问题可能包括:误报 / 漏报、丢失依赖项、许可证混淆以及不必要的负担会阻碍创新。
目前该版权提案仍在讨论中,已经有人开始竭力阻止实施。如自由软件基金会欧洲分会和开放论坛欧洲共同发起了 Save Code Share,这场请愿活动旨在阻止第 13 条实施,呼吁欧盟的政策制定者重新考虑或摈弃第 13 条。他们认为,对于处理代码、文档、音频和视频的开发者来说,版权合规检查完全实现自动化是不可行的。
大数据时代,个人隐私保护涉及我们每个人的切身利益,数据产业如何在保护消费者隐私的前提下快速发展,也是众人应该思考的问题,立法成了解决这个问题的“最后一根稻草”。但是,打击面过广又会造成用户和商业利益之间的冲突和不必要的损失,如何把握好立法的合理度成为一项挑战,用户隐私保护仍然任重而道远。但无论怎样,如果能用技术实现个人隐私保护与信息利用之间的平衡,相信对任何一方都是最令人期望的 Happy Ending。
参考资料:
https://www.kdnuggets.com/2018/03/gdpr-machine-learning-illegal.html
https://www.paypal.com/ie/webapps/mpp/ua/third-parties-list
https://rebecca-ricks.com/paypal-data/

今日荐文
点击下方图片即可阅读

李彦宏也来搅局视频智能音箱,这张“亲情牌”打得响吗?
ArchSummit 深圳站除准备了上百场前沿架构案例之外,此次还邀请了 Facebook 商业机器学习负责人、阿里高级技术专家前来开展 内部深度培训,手把手帮你搭建主流机器学习平台及实时流计算架构。其中 Facebook 培训大纲如下:
机器学习、特征工程实践问题及步骤解析
监督学习:分类、回归、深度学习、模型性能
无监督 /半监督学习
其他机器学习应用(备份、个性化、预测)
工业机器学习应用
Facebook、Microsoft、Amazon 的机器学习应用实践
PS:上述实践使用 R 和 Python 语言
目前 ArchSummit 会议及培训限时报名,席位有限,详细内容欢迎识别下方二维码或点击阅读原文,如需帮助可直接联系票务经理(微信:aschina666)



如果喜欢我们的文章,欢迎大家在阅读后随手点赞,以示鼓励。原创是一种信仰,专注是一种态度。



