文本挖掘从小白到精通(十一)--- 不需设定聚类数的DBSCAN

写在前面:笔者最近在梳理自己的文本挖掘知识结构,借助gensim、sklearn、keras等库的文档做了些扩充,会陆陆续续介绍文本向量化、tfidf、主题模型、word2vec,既会涉及理论,也会有详细的代码和案例进行讲解,希望在梳理自身知识体系的同时也能对想学习文本挖掘的朋友有一点帮助,这是笔者写该系列的初衷。
特别推荐|【文本挖掘系列教程】:
文本挖掘从小白到精通(一)---语料、向量空间和模型的概念
文本挖掘从小白到精通(三)---主题模型和文本数据转换
文本挖掘从小白到精通(五)---主题模型的主题数确定和可视化
文本挖掘从小白到精通(六)---word2vec的训练、使用和可视化
文本挖掘从小白到精通(七)--- Word2vec的增量学习
文本挖掘从小白到精通(八)--- 从海量文章中挖掘主要观点
文本挖掘从小白到精通(九)--- 文本相似性度量
文本挖掘从小白到精通(十)--- 不需设定聚类数的Single-pass
【特辑】文本分类算法集锦,从小白到大牛,附代码注释和训练语料
-
Ε邻域: 给定对象半径为Ε内的区域称为该对象的Ε邻域; -
核心对象: 如果给定对象Ε邻域内的样本点数大于等于MinPts,则称该对象为核心对象; -
直接密度可达: 对于样本集合D,如果样本点q在p的Ε邻域内,并且p为核心对象,那么对象q从对象p直接密度可达。 -
密度可达: 对于样本集合D,给定一串样本点p1,p2….pn,p= p1,q= pn,假如对象pi从pi-1直接密度可达,那么对象q从对象p密度可达。 -
密度相连: 存在样本集合D中的一点o,如果对象o到对象p和对象q都是密度可达的,那么p和q密度相联。
可以发现,密度可达是直接密度可达的传递闭包,并且这种关系是非对称的。密度相连是对称关系。DBSCAN目的是找到密度相连对象的最大集合。
那么核心对象有p,m,o,s(q不是核心对象,因为它对应的E邻域中点数量等于2,小于MinPts=3);
点m从点p直接密度可达,因为m在p的E邻域内,并且p为核心对象;
点q从点p密度可达,因为点q从点m直接密度可达,并且点m从点p直接密度可达;
点q到点s密度相连,因为点q从点p密度可达,并且s从点p密度可达。
与K-means方法相比,DBSCAN不需要事先知道要形成的簇类的数量。
与K-means方法相比,DBSCAN可以发现任意形状的簇类。
DBSCAN能够识别出噪声点。
DBSCAN对于数据库中样本的顺序不敏感,即Pattern的输入顺序对结果的影响不大。这就缓解了Single-pass对时序文本数据敏感的问题
一、导入必要的库
from __future__ import print_functionfrom sklearn.decomposition import PCAfrom sklearn.decomposition import TruncatedSVDfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.preprocessing import Normalizerfrom sklearn import metricsfrom pprint import pprintimport loggingfrom time import timeimport numpy as npimport osfrom sklearn.cluster import DBSCAN
二、载入文本数据及文本预处理
import pandas as pdimport jiebadata = pd.read_excel('/home/gaochangkuan/虎嗅网.xlsx','Sheet1')
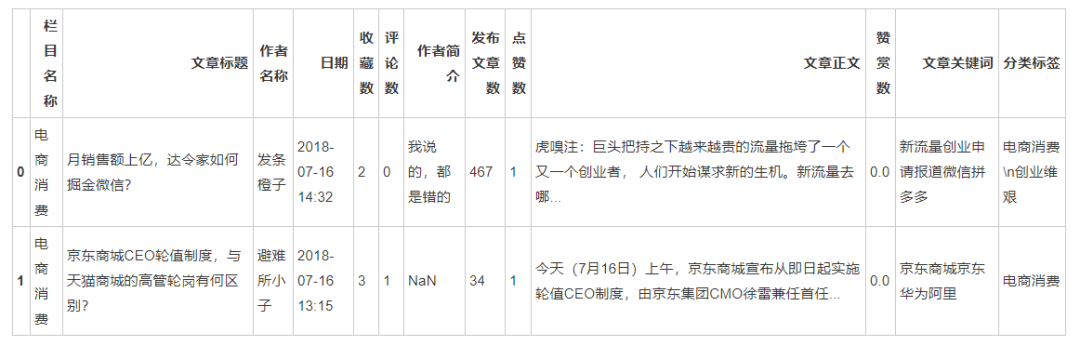
检视数据:
data.head(2)
去掉正文为空的行:
null = data['文章正文'].isnull()no_null = ~nulldata = data[no_null]
去掉正文重复的行:
data = data.drop_duplicates('文章正文')使用停用词表过滤无意义的词汇:
stwlist=[line.strip() for line in open('/home/kesci/input/stopwords7085/停用词汇总.txt','r',encoding='utf-8').readlines()]
对文章的正文数据进行分词处理:
jieba.enable_parallel(32) #开启32核并行分词模式data['正文切词'] = data['文章正文'].apply(lambda i:jieba.lcut(i) )
关键的一步,将分词形成的词汇列表转化为带空格间隔的字符串:
data['正文切词'] =[' '.join(i) for i in data['正文切词']]检视经过分词后的文本数据:
data['正文切词'] [:10]0 虎 嗅注 : 巨头 把持 之下 越来越 贵 的 流量 拖垮 了 一个 又 一个 创业者 , ...
1 今天 ( 7 月 16 日 ) 上午 , 京东 商城 宣布 从即日起 实施 轮值 CEO 制...
2 法国队 夺冠 了 。 你 脑海中 的 第一 反应 是 什么 ? 微博热 搜 已经 告诉 了 ...
3 虎 嗅注 : 在 霍华德 · 舒尔茨 的 带领 下 , 星巴克 逐渐 成长 为 一个 辐射 ...
4 早上好 。 又 一个 四年 结束 了 。 在 世界杯 巅峰 对决 中 , 法国队 似乎 拥有...
5 虎 嗅注 : 买 手店 , 是 消费品 尤其 是 时尚界 一个 独特 的 存在 。 买 手店...
6 随着 二手房 交易 火热 , 苏宁 , 京东 等 电商 平台 想 在 “ 链家们 ” 的 饭...
7 2018 年 7 月 11 日 , 瑞幸 咖啡 ( luckin coffee ) 宣布...
8 大家 晚上 好 ! 今天 是 周四 , 虎 嗅君 首先 带来 的 是 关于 中兴 的 消息 ...
9 可能 今天 是 什么 好日子 , 八家 公司 扎堆 登陆 港股 , 港交所 摆上 了 四面 ...
Name: 正文切词, dtype: object
三、文本特征提取环节 --- 提取稀疏的文本特征表示和降维
这里提取的是tf-idf特征,最大特征数为40000,也就是tf-idf值降序排列靠前的40000个词汇,但往往特征数会少于这个数,本文中的最终特征数是35718,也就是每个文本被转化为35718维的向量,可以想见,其中的0非常多,所以就显得“稀疏”。
注意,笔者在这里还做了另一个文本特征工程 --- 提取了每篇文章的2-gram特征,也就是说, 2-Gram将文本里面的内容按照字节进行大小为2的滑动窗口操作,形成了长度是2的字节片段序列,比如,比如 “上海 欢迎 你的 到来”,2-gram 切分就是 “上海欢迎 欢迎你的 你的到来”。由2-Gram抽取到的特征,更能代表文本的特性,可以对后续的文本聚类产生良好的推动作用。
print("%d 个文档" % len(data['正文切词']))print()print("使用稀疏向量(Sparse Vectorizer)从训练集中抽取特征")t0 = time()vectorizer = TfidfVectorizer(max_df=0.5,max_features=40000,min_df=5,stop_words=stwlist,ngram_range=(1, 2),use_idf=True)X = vectorizer.fit_transform(data['正文切词'])print("完成所耗费时间:%fs" % (time() - t0))print("样本数量: %d, 特征数量: %d" % X.shape)print()print('特征抽取完成!')##############################################################################
1676 个文档
使用稀疏向量(Sparse Vectorizer)从训练集中抽取特征
完成所耗费时间: 10.416094s
样本数量: 1676, 特征数量: 35718
特征抽取完成!
print("用LSA进行维度规约(降维)...")t0 = time()#Vectorizer的结果被归一化,这使得KMeans表现为球形k均值(Spherical K-means)以获得更好的结果。#由于LSA / SVD结果并未标准化,我们必须重做标准化。svd = TruncatedSVD(15)normalizer = Normalizer(copy=False)lsa = make_pipeline(svd, normalizer)X = lsa.fit_transform(X)print("完成所耗费时间:%fs" % (time() - t0))explained_variance = svd.explained_variance_ratio_.sum()print("SVD解释方差的step: {}%".format(int(explained_variance * 100)))print('PCA文本特征抽取完成!')
用LSA进行维度规约(降维)...
完成所耗费时间: 0.528620s
SVD解释方差的step: 74.52%PCA文本特征抽取完成!
四、进行实质性的DBSCAN聚类
这里有两个参数值得注意,一个是eps,一个是min_samples。如果在保留样本点之间的局部结构的情况下,将样本映射到2维空间,则可将eps视为半径画圆,而min_samples是圆圈中点的最低数量。
所以,在进行实质性的DBSCAN聚类前,可以对(部分)样本进行可视化,选定合适的参数,这对最终的聚类效果来说是至关重要的。
经过笔者的观察,暂且将eps设为0.2,将 min_samples设为4:
db = DBSCAN(eps=0.2, min_samples=4).fit(X)core_samples_mask = np.zeros_like(db.labels_, dtype=bool)core_samples_mask[db.core_sample_indices_] = True
聚类完成后。看看参与聚类的文章(编号)是哪些:
db.core_sample_indices_array([ 14, 15, 23, 29, 30, 35, 40, 47, 50, 52, 56,
57, 62, 63, 65, 66, 84, 87, 107, 112, 119, 120,
122, 125, 126, 129, 131, 134, 142, 145, 154, 155, 160,
164, 170, 171, 174, 187, 193, 196, 201, 212, 214, 215,
217, 220, 222, 227, 230, 232, 235, 247, 249, 257, 258,
260, 267, 268, 269, 277, 279, 283, 290, 293, 298, 300,
305, 308, 312, 321, 324, 325, 326, 328, 334, 339, 346,
362, 363, 365, 368, 373, 397, 416, 419, 429, 434, 435,
438, 441, 446, 453, 468, 473, 475, 477, 478, 481, 493,
495, 497, 500, 503, 507, 508, 509, 511, 517, 518, 522,
524, 525, 529, 530, 531, 532, 543, 546, 551, 552, 555,
556, 565, 570, 574, 579, 580, 586, 596, 598, 612, 616,
618, 620, 622, 633, 635, 642, 655, 662, 663, 665, 672,
676, 691, 698, 699, 706, 726, 732, 743, 747, 748, 749,
752, 755, 756, 762, 766, 768, 771, 782, 785, 799, 813,
822, 825, 826, 830, 831, 832, 833, 834, 838, 842, 844,
845, 852, 853, 854, 855, 861, 867, 870, 871, 872, 873,
874, 875, 885, 886, 889, 891, 895, 897, 900, 902, 903,
905, 906, 907, 910, 913, 914, 920, 922, 923, 924, 925,
926, 928, 929, 930, 931, 932, 934, 936, 940, 943, 946,
953, 954, 964, 965, 966, 967, 968, 972, 976, 977, 981,
983, 985, 987, 994, 995, 998, 1000, 1003, 1010, 1012, 1016,
1018, 1022, 1026, 1036, 1045, 1048, 1058, 1064, 1067, 1068, 1069,
1070, 1072, 1073, 1074, 1076, 1077, 1078, 1079, 1080, 1081, 1083,
1084, 1086, 1089, 1090, 1095, 1096, 1097, 1098, 1104, 1108, 1109,
1111, 1114, 1118, 1120, 1128, 1130, 1131, 1134, 1138, 1139, 1142,
1147, 1149, 1150, 1153, 1154, 1155, 1158, 1159, 1161, 1165, 1166,
1167, 1168, 1169, 1170, 1172, 1173, 1178, 1180, 1183, 1184, 1186,
1187, 1200, 1206, 1209, 1210, 1213, 1218, 1221, 1223, 1224, 1225,
1229, 1235, 1237, 1238, 1239, 1242, 1243, 1245, 1248, 1249, 1255,
1257, 1259, 1265, 1267, 1272, 1274, 1279, 1283, 1284, 1286, 1289,
1291, 1294, 1297, 1298, 1300, 1301, 1303, 1304, 1306, 1311, 1313,
1314, 1315, 1316, 1317, 1320, 1321, 1325, 1327, 1330, 1339, 1340,
1345, 1346, 1348, 1349, 1350, 1352, 1356, 1365, 1380, 1383, 1387,
1393, 1395, 1399, 1405, 1416, 1418, 1425, 1426, 1428, 1434, 1435,
1440, 1442, 1443, 1445, 1448, 1452, 1455, 1456, 1458, 1459, 1461,
1462, 1463, 1466, 1467, 1469, 1470, 1473, 1475, 1477, 1481, 1482,
1485, 1486, 1487, 1491, 1494, 1496, 1498, 1500, 1501, 1504, 1507,
1508, 1509, 1513, 1520, 1524, 1525, 1528, 1529, 1530, 1533, 1534,
1538, 1539, 1541, 1543, 1545, 1546, 1549, 1552, 1555, 1558, 1561,
1562, 1567, 1568, 1569, 1571, 1572, 1577, 1578, 1581, 1584, 1587,
1588, 1596, 1597, 1600, 1602, 1605, 1606, 1608, 1610, 1612, 1615,1621, 1623, 1625, 1627, 1645, 1656, 1661, 1662, 1669])
以及各个文本的标签:
labels = db.labels_labels
array([-1, -1, -1, ..., -1, -1, -1])
clusterTitles = db.labels_dbscandf = datadbscandf['cluster'] = clusterTitles
看看簇群序号为0的文章的标题有哪些,发现该类主要是奢侈品方面的报道:
dbscandf[dbscandf['cluster'] == 0]['文章标题'].head(20) # 簇群tag为0的title名称5 中国式买手诞生记
14 “抄抄抄”的Zara终于玩砸了
23 3亿美元签约费德勒,优衣库嗅到了什么?
27 “鹅”来了
30 爱马仕的“中年危机”
52 潮牌:成也小众,败也小众
62 香奈儿们的虚拟竞争力之战
63 LV的两难
66 奢侈的球鞋
98 为什么95后男生更爱化妆了?
120 你的化妆品有多少是由网红“带货”的
125 奶茶生意越做越大,为何我们总是戒不掉它?
132 饮料“小时代”:小品牌、小品类、小情绪的机会
142 现任LV女装创意总监继续当家,Gucci怕了吗?
148 我们挖了挖Gucci新店设计背后的理念
164 LVMH是怎样打造世界第一奢侈品帝国的?
170 Burberry能复制Gucci的翻身神话吗?
187 85后到底爱不爱奢侈品?
193 当复星穿上“最薄丝袜”
211 “重男轻女”的Nike还有救吗?
Name: 文章标题, dtype: object
看看簇群序号为20的文章的标题有哪些,发现该类是电影,尤其是漫威方面的报道。
dbscandf[dbscandf['cluster'] == 20]['文章标题'].head(20) # 簇群tag为20的title名称926 4分钟看懂漫威80年进化史
1134 《复联3》票房破19亿,它能超越《速8》吗?
1154 漫威十年,好莱坞的转型焦虑
1158 漫威越闪耀,好莱坞就越逊色
1159 从千万票房到3天12亿,漫威如何拍出最有号召力的“粉丝电影”
1163 灭霸响指一打,《复联3》内地票房过了10亿元
1164 前18部漫威电影没看全,怎么样才能(假装)看懂了《复联3》?
1171 漫威拯救世界的十年
1172 漫威英雄的复印者联盟
1174 超级英雄里到底谁最“能死”?
1175 从《钢铁侠》到《复联3》,漫威是如何做到10年160亿票房的
1177 漫威超级英雄的集体焦虑
1178 《复联3》上映:欢迎来到只有漫威才能拯救的世界
1226 布局十年的《复联3》上映了,漫威为什么能把IP玩得这么溜?
1468 漫威近七年评分最低的《黑豹》,总票房破8亿怕是有点难
1479 别骂黑豹:你们想看的基萌酷炫爆米花,漫威真的拍腻了
1482 《黑豹》已预订明年奥斯卡?现在的奥斯卡怎么了?
1520 《黑豹》配得上“漫威最佳”吗?
Name: 文章标题, dtype: object
聚类数及噪点计算:
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)n_noise_ = list(labels).count(-1)print('聚类数:',n_clusters_)print('噪点数:',n_noise_)
聚类数: 24
噪点数: 1115
对结果可视化:
import matplotlib.pyplot as plt%matplotlib inline# 黑色点是噪点,不参与聚类unique_labels = set(labels)colors = [plt.cm.Spectral(each)for each in np.linspace(0, 1, len(unique_labels))]for k, col in zip(unique_labels, colors):if k == -1:col = [0, 0, 0, 1]class_member_mask = (labels == k)xy = X[class_member_mask & core_samples_mask]plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),markeredgecolor='k', markersize=14)xy = X[class_member_mask & ~core_samples_mask]plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),markeredgecolor='k', markersize=6)plt.title('大致聚类数: %d' % n_clusters_)plt.savefig(os.path.join(dirname('__file__'), 'py.png'))
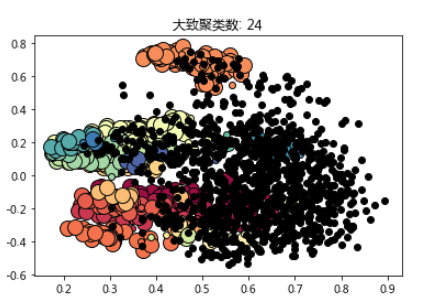
可以看到,聚出来的效果还不错,识别了大量噪点 --- 也就是在笔者的参数设定下,构不成“气候”的文章。如果换成K-means,还不知道汇聚成啥样。
结语
类似上一篇文章中提到的single pass聚类,本文中的部分环节可做如下尝试:
(1)文本的表示可以采用Doc2vec或Skip-thoughts等算法直接获取文档的向量表示;
(2)提取每个聚类中的关键主题词和代表性语句;
(3)试试短文本情况下的聚类,看效果如何?如果不好,该做怎样的改进~
以上。
欢迎看到这里的读者留言,笔者将不胜欣慰~这也是笔者继续更新文章的强大动力!
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏

