CIKM'22「亚马逊」推荐系统中的图神经网络如何消除曝光偏差?
标题:Debiasing Neighbor Aggregation for Graph Neural Network in Recommender Systems
链接:https://arxiv.org/pdf/2208.08847.pdf
会议:CIKM 2022
公司:亚马逊
1. 导读
图神经网络 (GNN) 通过基于用户和商品的历史交互来表征用户和商品,在推荐系统中取得了显着的成功。然而,很少有人注意到 GNN 对暴露偏差的脆弱性:用户暴露于有限数量的商品,因此系统只能学习用户偏好的有偏的喜好,从而导致推荐质量次优。虽然逆倾向加权已知可以识别和减轻曝光偏差,但它通常适用于模型输出的最终目标,而 GNN 在邻居聚合期间也可能存在偏差。本文提出了一种简单但有效的方法,即通过 GNN 的逆倾向 (Navip) 进行邻居聚合。具体来说,给定一个用户-商品二分图,首先得出图中每个用户-商品交互的倾向得分。然后,将具有拉普拉斯归一化的倾向得分的倒数应用于去偏邻聚合。
2. 基础
在在线服务中,用户-商品交互数据 根据策略 收集,这是用户行为的先验。推荐系统通过基于收集的数据 找到相似的用户和商品来执行个性化推荐,这被称为协同过滤。给定一个推荐模型 及其对用户 u 与项目 i 的相关性的预测为 ,基于它们的embedding,最小化隐式反馈 的经验风险,公式如下,
2.1 基于GNN的推荐系统
GNN 与传统 CF 方法的最大区别在于,GNN 在目标节点表征的推断过程中显式地利用了目标节点的邻居。给定用户和商品作为节点的二分图,用户 u 在层 l 的embedding h 计算方式如下,
其中 表示 u 的邻居 N(u) 在层 l 的聚合embedding。可以以相同的方式得到商品 i 的embedding。GNN主要是通过AGGREGATE(·) 和 TRANSFORM(·) 来实现。
2.2 逆倾向分
在服务中,用户只接触到系统策略选择的部分项目 。因此,收集的日志数据 依赖于策略 ,这称为曝光偏差。自然地,在 上训练的推荐方法 会产生偏差,甚至会加剧偏差。为此,IPS 被广泛用于通过使用倾向分重新加权 来获得统一商品曝光策略 性能的无偏估计量R(π)。
为倾向性得分,定义为在策略 下,用户-商品的交互概率。
3. 方法

3.1 Navip
Navip 将 IPS 加权方案应用于邻居聚合,以减少有偏交互和去偏 GNN 邻居聚合的影响。Navip 可以被认为是在聚合过程中对具有低倾向的交互具有更大的权重,而对具有高倾向的交互具有更小的权重。Navip 背后的基本原理是,具有较低交互倾向的邻居更多地揭示了给定目标用户的真正兴趣,因为这种交互不太可能由有偏见的系统策略发生。另一方面,由于具有高倾向性的交互通常作为对有偏见的系统策略的响应而发生,因此它们可能不是真正的用户交互。
假设一个简单的邻居聚合, ,将上一层的邻居embedding聚合。为了清楚起见,进一步定义 为用户 u 在系统策略 π 下的聚合邻居嵌入, 是 π 在 上的蒙特卡洛近似聚合邻居嵌入。公式如下,其中 表示在策略π下第l-1层的节点embedding,在实践中, 基于 估计得到,因为 是无法得到的。
因此结合倾向性分数,可以得到Navip对 的估计如下,
然而由于相邻权重的大小未归一化,使用逆倾向会导致数值不稳定问题。为了避免这个问题,Navip 通过替换 进一步归一化邻居聚合,公式如下,其中
3.1.1 连接到拉普拉斯算子
Navip的邻居聚合函数可以用矩阵形式表示。公式如下,
那么,加权随机游走拉普拉斯算子可以表示为 ,其中A和H分别为聚合的邻居embedding和节点embedding, 为邻接矩阵,D为度矩阵。
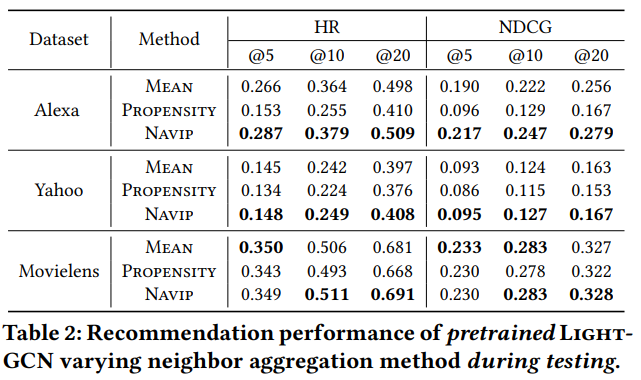
4. 结果