北大数学系毕业,UIUC助理教授60页论文综述深度学习优化

转载自:新智元
深度学习理论是当下研究的热点之一。最近来自UIUC的助理教授孙若愚撰写了一篇关于深度学习优化的综述论文《Optimization for deep learning: theory and algorithms》,共60页257篇文献,概述了神经网络的优化算法和训练理论,并得到众多大佬的推荐,比如模仿学习带头人加州理工Yisong Yue,欢迎大家阅览,需要一番数学理论功底,方能扛过。
摘要
为什么一个复杂的神经网络居然可以被成功训练出来? 到底是哪些要素促成的? 为了理解这些问题,本文概述了神经网络的算法和优化理论。首先,我们讨论梯度爆炸/消失问题和更一般的谱控制问题,然后讨论实际中常用的解决方案,包括初始化方法和归一化方法。其次,我们回顾用于训练神经网络的一般优化方法,如SGD、自适应梯度方法和大规模分布式训练方法,以及这些算法的现有理论结果。第三,我们回顾了最近关于神经网络训练的全局问题的研究,包括局部极值、模式连接、彩票假设和无限宽度分析等方面的结果。
1. 概述
神经网络包含大量的参数,这些参数一般通过求解一个优化问题来找到,这是一个很复杂的非凸优化问题。本文的主旨是理解如此复杂的神经网络得以被成功训练的关键要素,以及可能导致训练失败的因素。想象你在1980年试图用神经网络解决一个图像分类问题,没有任何关于神经网络的知识,很可能你最初的几次尝试都会得到很差的结果,比如算法不收敛或者最终收敛到的解的误差很大。你需要哪些变化才能让你的算法成功运行? 总体上来说,你需要三样东西(除了硬件和数据之外): 合适的神经网络、合适的训练算法和合适的训练技巧。
1)合适的神经网络。这包括神经网络架构和激活函数。对于神经网络架构,你可以用一个至少有5层和足够多神经元的卷积网络来替换一个全连接网络。为了获得更好的性能,你可以将深度增加到20甚至100,并添加跳跃连接 (skip connection)。对于激活函数,一个好的选择是ReLU激活函数,但是使用tanh或swish激活也可以得到不错的结果。
2)训练算法。一个重要的选择是使用随机版本的梯度下降(SGD)并坚持下去 。经过仔细调整的常数学习率(learning rate)表现已经可以相当好了,而使用动量和自适应的学习率可以提供额外的好处。
3)训练技巧。适当的初始化对于算法的训练是非常重要的。要训练一个超过10层的网络,通常需要两个额外的技巧:添加归一化层 (normalization layer) 和添加跳跃连接。
在上述诸多元素中, 哪些元素是必要的? 目前我们已经了解了一些元素的作用,包括初始化策略、归一化方法、跳跃连接、过参数化 (大宽度)和SGD,如图1所示。我们将它们对优化算法的影响大致分为三部分: 控制Lipschitz常数(以使算法收敛)、更快的收敛速度和更好的函数全局性质 (landscape)。还有许多其他的元素是很难理解的,尤其是神经架构。话说回来,要理解这个复杂系统的每个部分是几乎不可能的,而这个领域目前的研究已经可以提供一些有用的理解和启发。
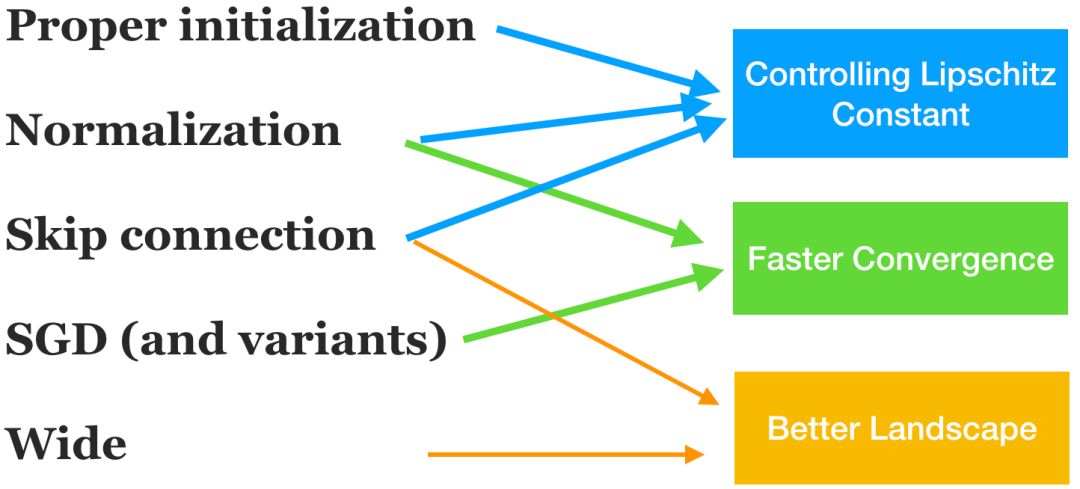
图1: 对神经网络训练的几个主要元素的理论解读。它们对算法收敛的三个方面有影响:使收敛成为可能、更快的收敛和更好的全局解。这三个方面有一定的联系,因此上述分类只是一个粗略的分类。请注意,对一些重要元素(特别是神经网络架构)的理论理解还非常欠缺,因此在该图中被省略了。还有一些重要理论方面(比如泛化能力和表示能力),在这个图中被省略了。
为了简单起见,我们将主要讨论前馈神经网络的监督学习问题。我们几乎不讨论一些更复杂的问题,如GANs(生成对抗网络)和深度强化学习,也不讨论更复杂的神经网络架构,如RNN(递归神经网络)、attention和Capsule。从一个更广泛的视角来看,监督学习理论至少包含表示、优化和泛化(参见1.1节),而我们不详细讨论表示理论和泛化理论。注意,虽然本文主要讨论监督学习,但一个主要目标是理解神经网络结构(即一种特殊的参数化方式)如何影响优化算法的设计和分析,其数学本质并不仅仅局限于监督学习问题的具体模型,因此可以推广到更一般的使用了神经网络的问题上(例如GAN)。
这篇文章的目标读者是对神经网络的理论理解(尤其是优化算法方面)感兴趣的研究人员。为了理解这篇文章,了解机器学习和优化的一些基本理论会很有帮助 (参见[24,200,29]),但也不需要很多优化知识。我们注意到现有的关于深度学习算法的介绍主要针对一般的机器学习研究者,如Goodfellow等[76]的第8章。这些介绍通常不深入讨论算法背后的理论。相反,在本文中我们更多地强调理论分析,但同时尽量使其对非理论背景的读者易于理解。如果可能的话,我们将提供一些简单的例子来说明理论背后的直觉,但我们一般不会解释定理的细节。本文尝试厘清大框架和主要的脉络,会重点介绍一部分文章的主要想法,而由于篇幅所限,对绝大多数文章着墨甚少(如果读者想进一步了解,有些地方会指出一些可继续阅读的参考文献)。
1.1 大局观:对理论的分解
分解 (reductionism, 或还原论) 是研究科学的一个很有用且流行的元方法。我们首先简要回顾如何分解机器学习理论以及优化在其中的作用,然后讨论如何对深度学习的优化理论进行进一步的分解。
表示、优化和泛化。监督学习的目标是根据观察到的样本找到一个近似真实函数的函数。第一步是找到一个丰富的函数族(如神经网络)以表示真实的函数。第二步是通过最小化某个目标来计算出这个函数的参数。第三步是使用第二步中找到的函数对新的测试数据进行预测,产生的错误称为测试误差。测试误差可以分解为表示误差、优化误差和泛化误差,分别对应这三个步骤引起的误差。
在机器学习中,表示、优化和泛化这三个学科经常被分开研究。例如,在研究一类函数的表示能力时,我们往往不关心优化问题能否很好地解决。在研究泛化误差时,我们通常假设已经找到了全局最优值 (可参考一个关于泛化能力的综述[95])。类似地,在研究优化理论 时,研究者经常不考虑泛化误差(但有时假定表示误差为零)。注意,理想的研究方式是对多个方面做综合分析而不仅仅只考虑一个方面,但如果一个方面都没有理解清楚,合并在一起分析只会更加困难,这是所有学科研究者都会面临的一个权衡取舍。我们希望未来会有更多的综合性研究出现。
优化问题的分解。深度学习的优化问题比较复杂,需要进一步分解。大致上来说,对优化算法的设计可以分为三个步骤。第一步是使算法开始运行,并收敛到一个合理的解,如一个驻点 (stationary point)。第二步是使算法尽快收敛。第三步是确保算法收敛到一个低目标值的解 (如全局极小值, 可使得训练误差小)。除了这三步之外,还有一个额外的步骤是取得比较小的测试误差,但是这超出了优化分析的范围。简而言之,我们将优化问题分为三个考量: 收敛性、收敛速度和全局表现。

本综述涉及的文献分三个主要部分: 第四节 (Section 4),第五节 (Section 5) 和第六节 (Section 6)。大致说来,每个部分主要由上述优化分析的三个考量之一所驱动。这三个部分之间的边界是比较模糊的。例如,第四节中讨论的一些技术也可以提高收敛速度,第六节中的一些分析也解决了收敛问题而不仅仅是解的全局表现。我们划分这三节的另一个原因是它们代表了神经网络优化的三个相当独立的子领域:从历史上来说它们在一定程度上是独立发展的。
1.2 文章结构
这篇文章的结构如下。在第二节中,我们介绍监督学习中的神经网络优化问题。在第三节中,我们介绍了反向传播(BP),并分析了将经典收敛定理应用于梯度下降的主要困难。在第四节中,我们讨论训练神经网络的一些特定技巧,以及一些基本理论。这些是和神经网络相关的方法,它们打开了神经网络的黑盒子。我们讨论了一个称为梯度爆炸/消失的主要挑战,以及控制频谱这个更一般的挑战,并回顾了主要的解决方案,如仔细的初始化和归一化方法。在第五节中,我们讨论了将神经网络视为一般非凸优化问题的泛型算法设计。特别地,我们回顾了SGD的各种学习速率调整方式 (learning rate schedule)、自适应梯度方法、大规模分布式训练、二阶方法以及关于它们的现有理论结果。在第六节中,我们回顾了神经网络的全局优化研究,包括全局函数图景 (global landscape)、模式连接、彩票假设和无限宽度分析(如神经切线核)等等。
论文地址:
https://arxiv.org/pdf/1912.08957.pdf
作者简介

孙若愚
孙若愚是UIUC(伊利诺伊大学香槟分校)助理教授,研究数学优化和机器学习 。在加入UIUC之前,曾担任FAIR (Facebook AI Research) 的访问科学家,并曾于斯坦福大学从事博士后研究,本科毕业于北京大学。最近的研究方向包括神经网络的优化理论和算法、生成对抗网络、非凸矩阵分解、大规模优化算法的设计和分析等等。
https://ruoyus.github.io/
补充说明:此文是作者在UIUC开设的”深度学习的优化理论”一课的重要基础,也是作者在北京大学应用数学暑期学校所教“深度学习中的数学”一课的基础。
课程网址:
https://wiki.illinois.edu/wiki/spaces/viewspace.action?key=IE598ODLSP19
注:本文部分内容转载自“专知”
https://mp.weixin.qq.com/s/sLmm6mVecRTwV-vbw9xGLQ
——END——

