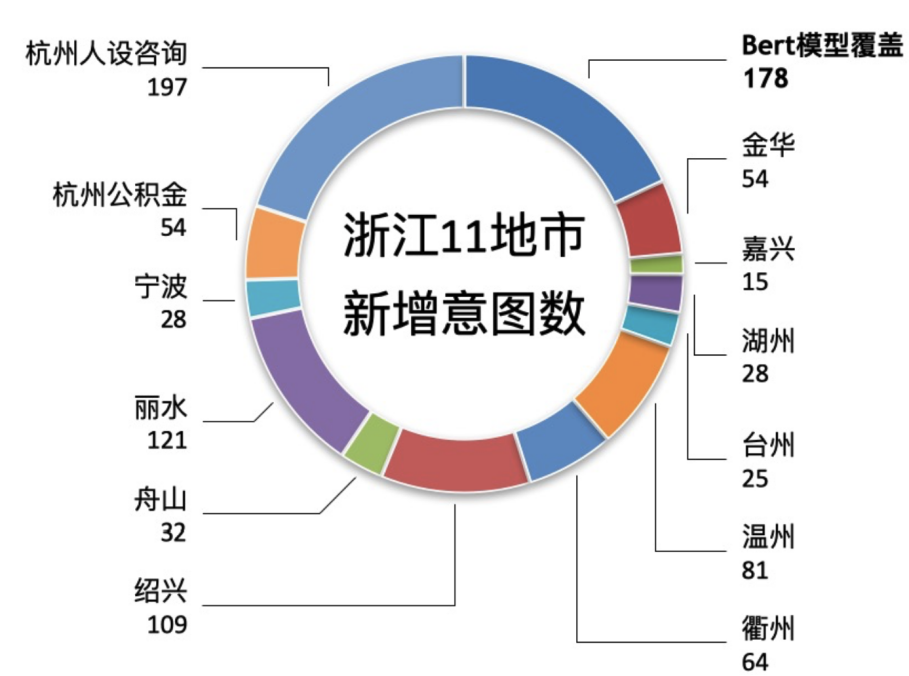
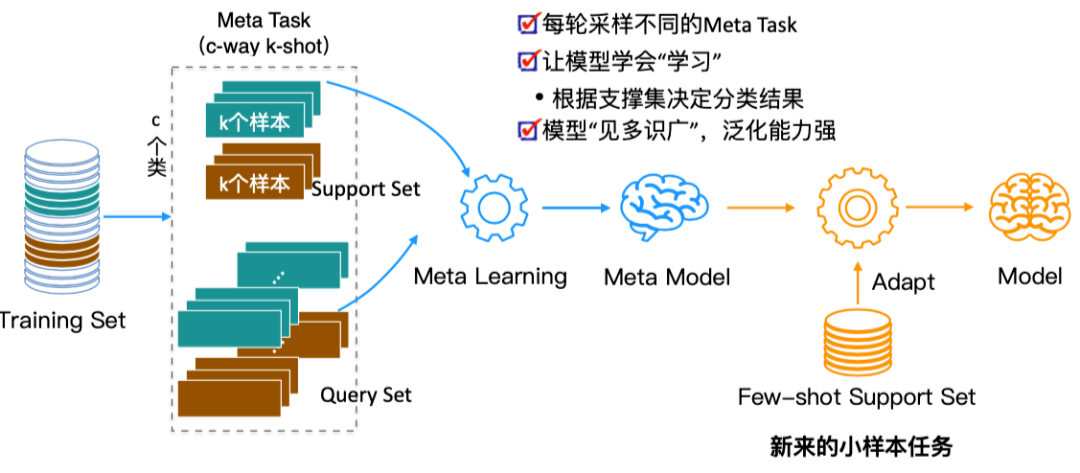
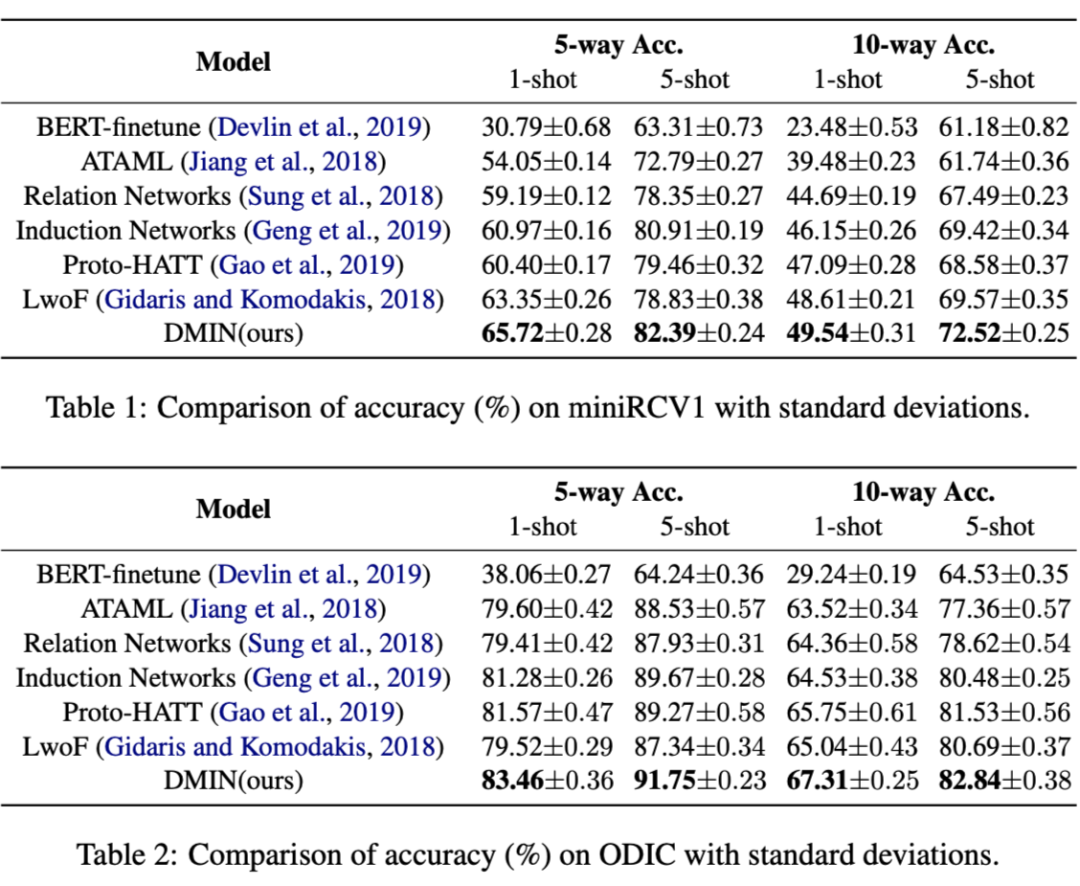
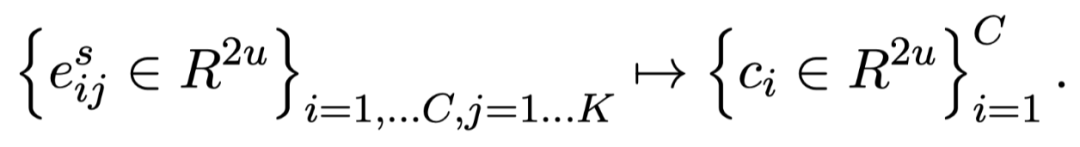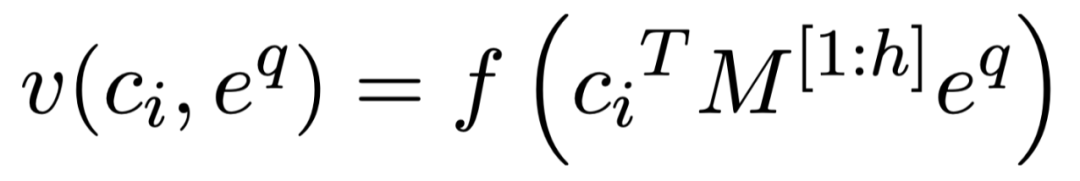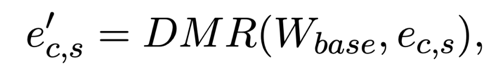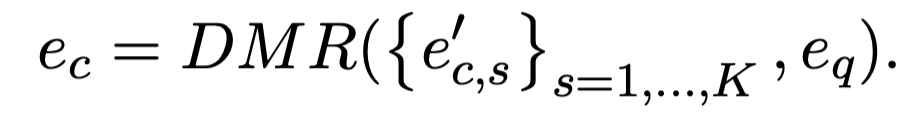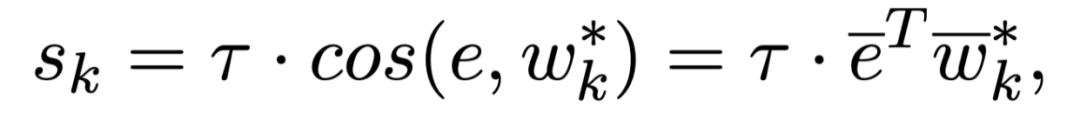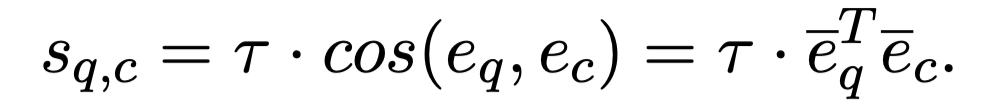人类非常擅长通过极少量的样本识别一个新物体,比如小孩子只需要书中的一些图片就可以认识什么是“斑马”,什么是“犀牛”。在人类的快速学习能力的启发下,研究人员希望机器学习模型也具备这种能力,对于新的类别,只需要少量的样本就能快速学习,这就是 Few-shot learning 要解决的问题。 小样本学习的的目标是模型在大量类别中学会通过少量数据正确地分类后,对于新的类别,只需要少量的样本就能快速学习。如图 2 所示,形式化来说,few-shot learning 的训练集中包含了大量的类别,每个类别中有少量样本。 在训练阶段,会在训练集中随机抽取 C 个类别,每个类别 K 个样本(总共个 CxK数据)构建一个 meta-task,作为模型的支撑集(Support set)输入;再从这 C 个类中抽取一批样本作为模型的询问集(Query set)。即要求模型从CxK 个数据中学会如何区分这 C 个类别,这样的任务被称为 C-way K-shot 问题。 模型训练的过程中在每次迭代时把支撑集送入模型,并优化模型在询问集上产生的损失函数,这种训练方式一般称为 Episode-based meta-training。值得注意的是这种训练机制使得模型很难过拟合,假设我们训练集中包含 159 个类,可以产生 个不同的 5-way 任务。
▲ 图2 Few-shot Learning学习机制
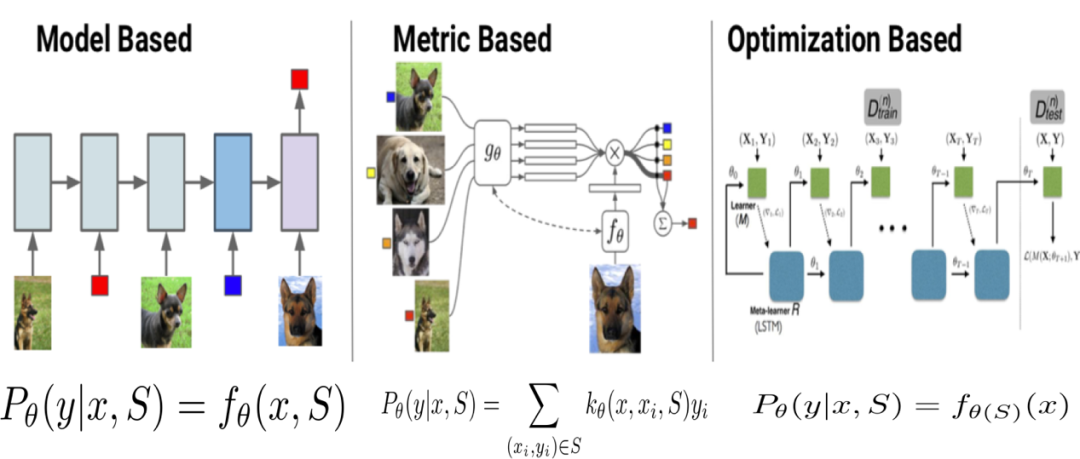
现有的 few-shot learning 模型大致可分为三类,如图 3 所示: Mode Based,Metric Based 和 Optimization Based。其中 Model Based 旨在通过模型结构的设计快速在少量样本上更新参数,直接建立输入 x 和预测值 P 的应设函数;Metric Based 方法通过度量 batch 集中的样本和 support 集中样本的距离,借助最近邻的思想完成分类;Optimization Based 方法认为普通的梯度下降方法难以在 few-shot 场景下拟合,因此通过调整优化方法来完成小样本分类的任务。具体内容可以参考我们之前的小样本学习综述。
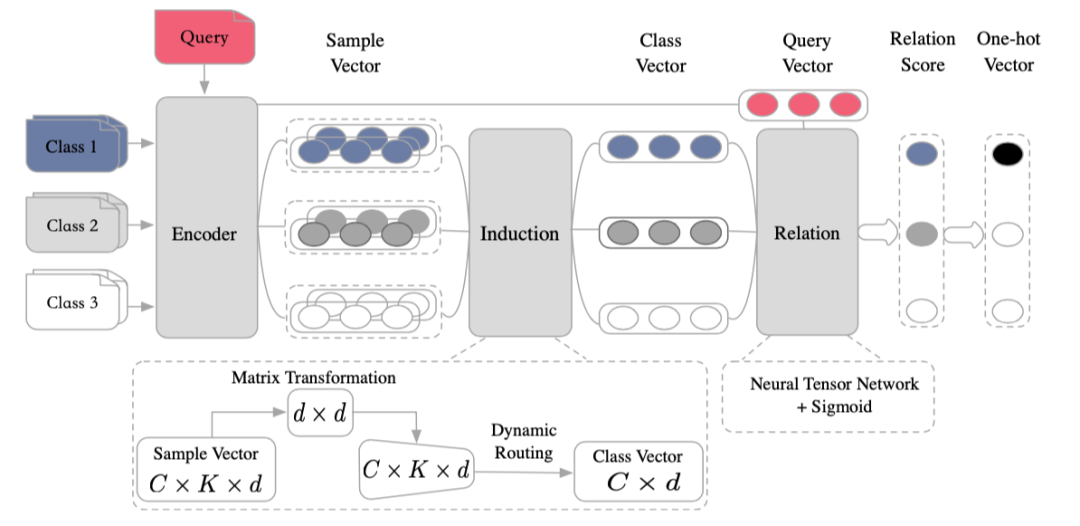
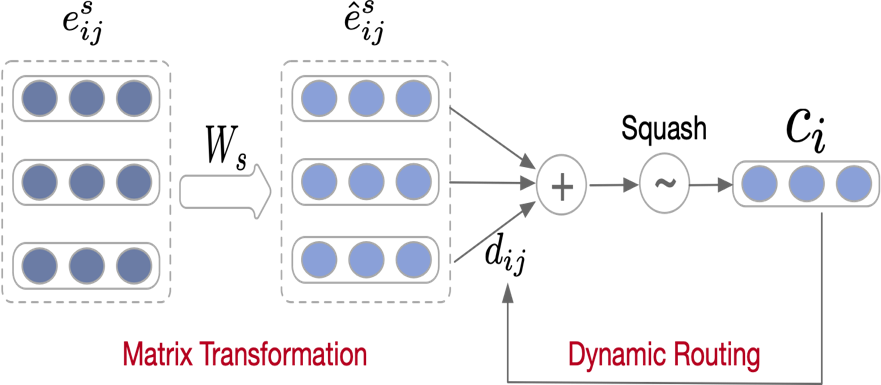
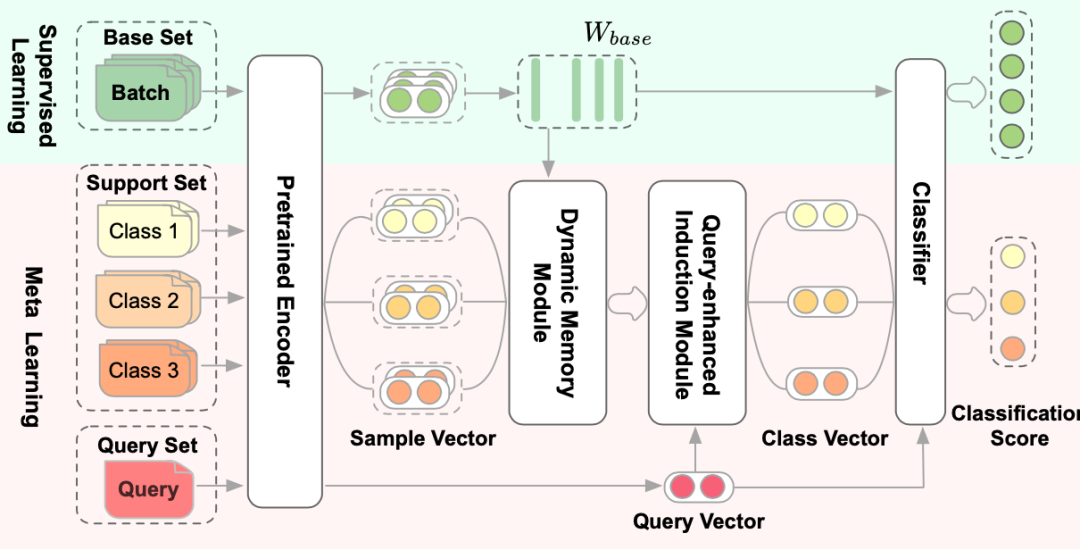
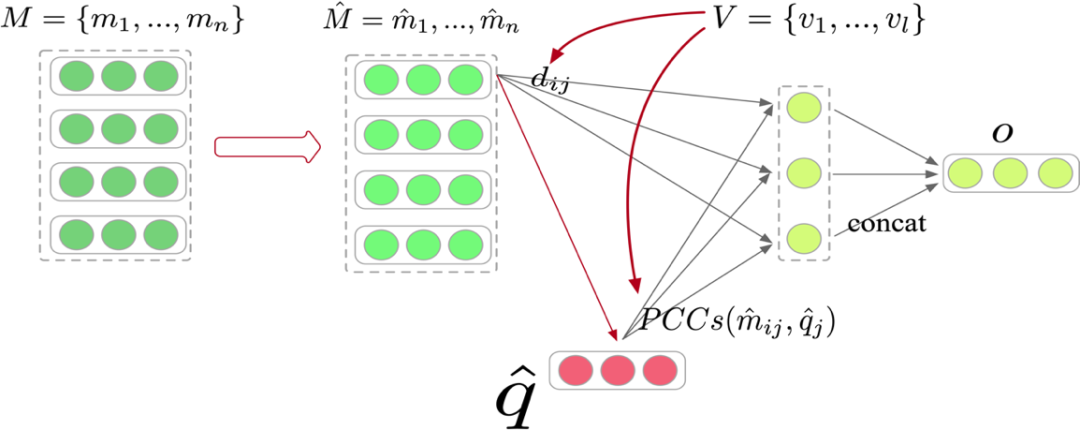
通过这种方式训练的 base 分类器,属于同一个类的特征向量必然会和对应的分类参数特别接近,所以最后的分类参数 W 就可以做为 base 类的类别特征,进而做为 meta learning 的记忆模块。 在 meta learning 阶段,我们将类别向量和 query 向量一起输入该分类器,得到新类别的分类打分:
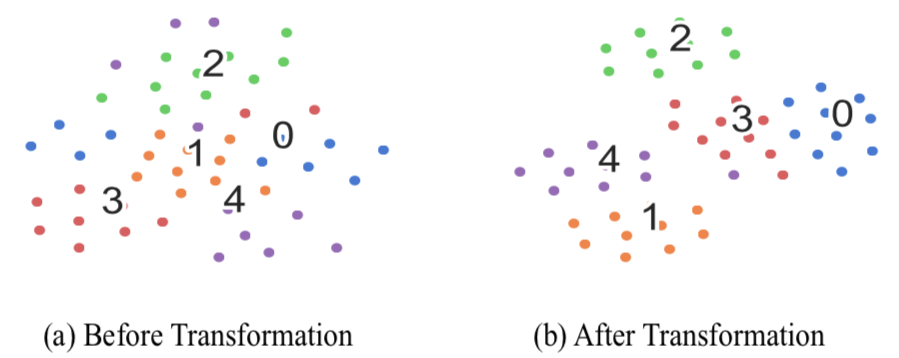
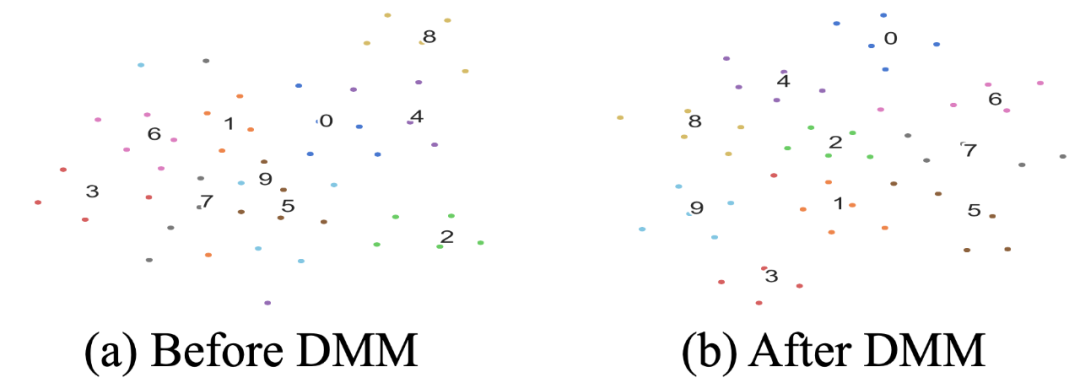
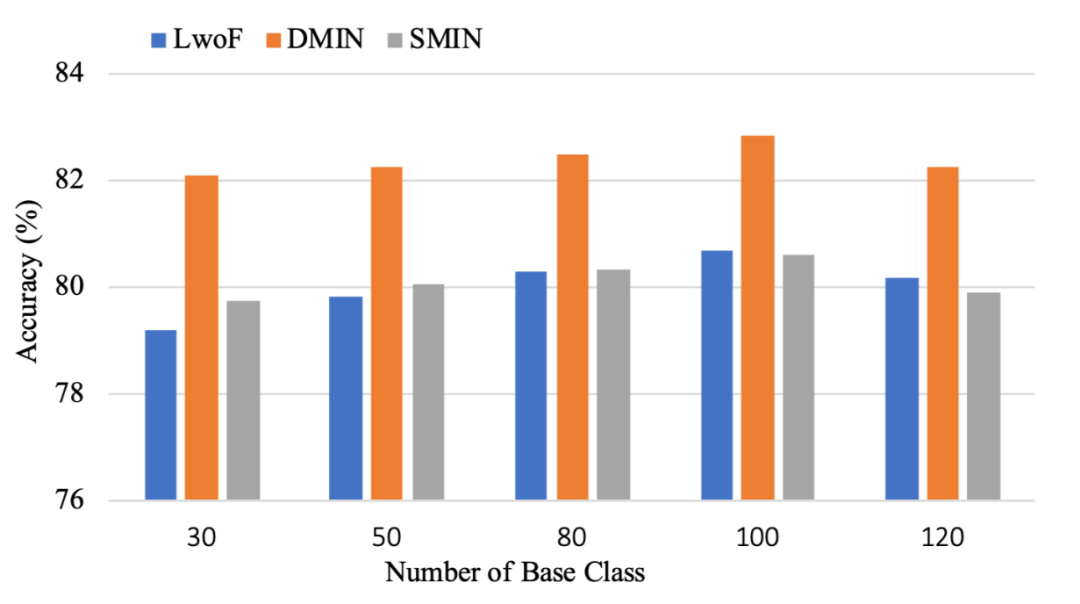
▲ 图8 DMM模块分析 我们在 ODIC 数据集上变化监督学习阶段 base 类别的数量,然后观察其对小样本学习结果的影响,图 9 可以发现当 base 类别从 30 增长到 100 的时候,由于在监督学习阶段学到了更强的文本 embedding 特征,最终结果是随着 base 类的数量而提升的。但是在 base 类为 120 的时候出现下降,这是由于 unseen 类别的占比太低的时候,模型整体对 unseen 类别的识别能力也会受到影响。
▲ 图9 Base Class 分析 5.3 结论 在本工作中,我们针对小样本文本分类问题提出了动态记忆归纳算法,该网络基于动态路由机制和外部的记忆模块进行交互,使用记忆模块跟踪过去的学习经历,使用动态路由机制快速适应支撑集中新的类别。 该模型在 miniRCV1 和 ODIC 数据集上获得了最新的 SOTA 结果。由于动态记忆可能是一种比我们在这里进行过的小样本学习实验更通用的学习机制,因此我们在对话领域的其他任务上也会继续探索该模型的使用。
[1] Zi-Yi Dou, Keyi Yu, and Antonios Anastasopoulos.2019. Investigating meta-learning algorithms for low-resource natural language understanding tasks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Lan-guage Processing (EMNLP-IJCNLP), pages 1192–1197.
[2] Hu Z, Chen T, Chang K W, et al. Few-Shot Representation Learning for Out-Of-Vocabulary Words[J]. arXiv preprint arXiv:1907.00505, 2019.
[3] Gu J, Wang Y, Chen Y, et al. Meta-Learning for Low-Resource Neural Machine Translation[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018: 3622-3631.
[4] Gidaris S, Komodakis N. Dynamic few-shot visual learning without forgetting[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 4367-4375.
[5] Geng R, Li B, Li Y, et al. Induction Networks for Few-Shot Text Classification[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019: 3895-3904.
[6] Sun Q, Liu Y, Chua T S, et al. Meta-transfer learning for few-shot learning[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2019: 403-412.
[7] Qi H, Brown M, Lowe D G. Low-shot learning with imprinted weights[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 5822-5830.
[8] Wu J, Xiong W, Wang W Y. Learning to Learn and Predict: A Meta-Learning Approach for Multi-Label Classification[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019: 4345-4355.
[9] Yang Z, Zhang J, Meng F, et al. Enhancing Context Modeling with a Query-Guided Capsule Network for Document-level Translation[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019: 1527-1537.
[10] Ye Z X, Ling Z H. Multi-Level Matching and Aggregation Network for Few-Shot Relation Classification[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 2872-2881.
[11] Dou Z Y, Yu K, Anastasopoulos A. Investigating Meta-Learning Algorithms for Low-Resource Natural Language Understanding Tasks[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019: 1192-1197.
[12] Chen M, Zhang W, Zhang W, et al. Meta Relational Learning for Few-Shot Link Prediction in Knowledge Graphs[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019: 4208-4217.
[13] Allen K, Shelhamer E, Shin H, et al. Infinite Mixture Prototypes for Few-Shot Learning[J].
[14] Cai Q, Pan Y, Yao T, et al. Memory matching networks for one-shot image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 4080-4088.