AAAI 2020 | NAS+目标检测:AI设计的目标检测模型长啥样?

©PaperWeekly 原创 · 作者|刘畅
学校|上海交通大学博士生
研究方向|计算机视觉

太长不看版
论文标题:SM-NAS: Structural-to-Modular Neural Architecture Search for Object Detection
论文来源:AAAI 2020
论文链接:https://arxiv.org/abs/1911.09929

注:帕累托前沿(Pareto front),即 Pareto 解的集合,在这里可理解为一个模型集合,从集合里拉出任意两个成员出来,节省资源的一定准确率低。而对于不属于这个集合的模型,总有一个集合成员比他又节省资源又准确率高。本文考虑的是一个多目标搜索问题,而搜索空间则是很多热门的检测算法。

检测算法总体上(大多)由 backbone,feature fusion neck(FPN 属于这类),RPN 和 RCNN head 四种 module 组成,之前有很多工作提出了很多不错的 module,但是不知如何在硬件资源限制下寻找最优组合。
就算可以把所有的组合全在标准数据集上训一遍再比较并去除最好的,最终也只是个低效且次优(sub-optimal)的组合,因为某个组合可能只适用于特定的数据集(比如 COCO 可以,VOC 就不行)。除此之外,现有的 NAS 只关注最优化目标检测系统的一个部分而不是整体。
1. Two-stage 的模型不一定比 One-stage 模型跑得慢;
2. 通过精心组合,一个输入图片尺寸较小的复杂模型,可以在速度和精度上双重碾压一个输入尺寸较大的简单模型。
影响目标检测系统效果的要素
总结一下,本论文致力于建立了一个多目标搜索机制,寻找高效最优的目标检测整体结构。在总结了 state-of-the-art 的设计和实验的现象之后,作者总结了三个影响目标检测系统效果的要素:
-
输入图片的大小 -
检测器不同 module 的组合 每个 module 的结构
为了在这三个要素中找到一个兼顾效率和准确的权衡,作者提出了一个从粗到细的搜索策略:1)结构层级(第一步):寻找module的组合以及模型输入图片的尺寸;2)模块层级(第二部):演化每个特定的 module,去获得一个高效的网络。
搜索空间
搜索空间会随着搜索策略改变,因此每一步都有自己特定的搜索空间:
第一步:包含 one-stage 和 two-stage 的热门模块,以及输入图片的大小。
第二步:优化和搜索第一步确定下来的模块,以 backbone 为例,本来当分类的模型不太适合直接迁移到目标检测问题中。以 backbone 为例,本来当分类的模型不太适合直接拿来当检测(比如每一层的通道数和中间的空间分辨率),这些也可以通过搜索的办法微调。
搜索方法
而对于搜索方法,论文结合了演化算法和偏序剪枝(Partial Order Pruning)来进行快速搜索(具体搜索算法引用自下面两篇论文)。
除此之外,作者提出了更好的训练策略,无需 ImageNet 预训练就可以直接跑,还在分布式训练系统上并行了整个搜索过程。
创新点
首先通过研究不同模块组合以实现速度精度权衡
从粗到细的搜索策略,分解成结构-模块层级以高效推进帕累托前沿
快速训练策略,无需预训练直接搜索。因此,作者认为有机组合不同模块与输入尺寸至关重要,才有了 SM-NAS 这种从结构到模块的两步搜索策略。

NAS Pipeline
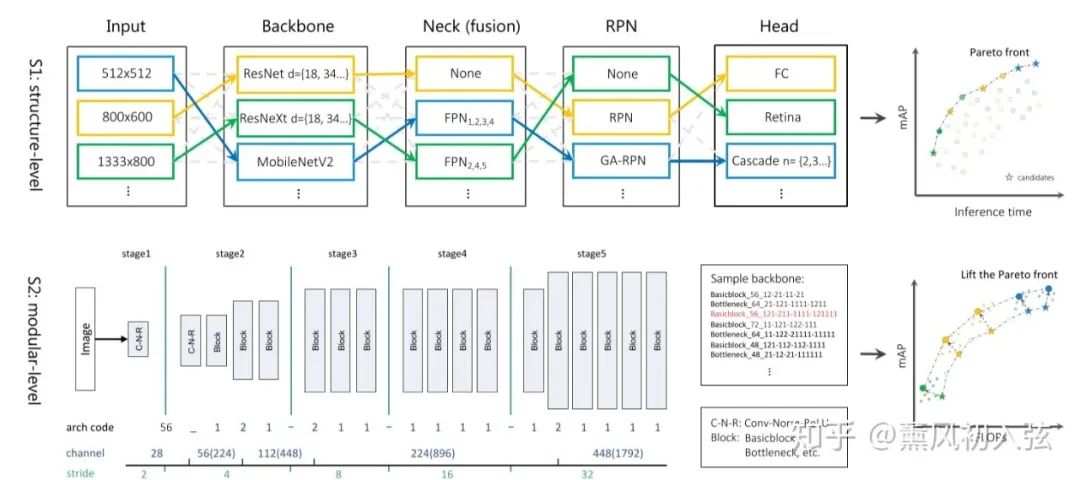
如上图所示,上面是搜索的第一个层级:结构层级。该层级把整个模型分成了 backbone + feature fusion neck + RPN + RCNN head 四个部分,把所有 state-of-the-art 放到了搜索空间里,并且还额外加入了输入图片尺寸这一维度。
1. Backbone: ResNet(18,34,50,101) | ResNeXt(50,101) | Mobilenet V2
注意,结构层级搜索里还是用的 ImageNet 预训练(说好的所谓快速搜索策略呢)。
2. Feature Fusion Neck: 该 module 旨在融合不同层的特征,也对应了图片中不同大小的目标
NO FPN (Faster RCNN) | FPN(输入输出特征层级可调,有多种选项)
3. RPN: NO RPN (即1-stage模型) | RPN | Guided Anchoring RPN
4. RCNN Heads: Regular | Cascade (几个输出待定) | RetinaNet
5. Input Resolution: 512x512 | 800x600 | 1080x720 | 1333x800
在第一阶段,搜索的指标是精度和推理时间,结合验证数据集的准确性,生成一个 Pareto 前沿,显示在不同资源约束下目标检测模型的最佳结构。
而下面则是搜索的第二个层级:模块层级。
当第一个层级生成了一个帕累托前沿时,我们可以选择几个不错的模型,并在第二个阶段里对每个模型进行微调,并提升速度/精度的权衡效果。
ThunderNet 提出,目标检测的 backbone,在前面的特征图更大,充满描述空间细节的低级特征。而后面的特征图则更小,但更具有高层的可描述性。
检测任务有定位与分类两个子任务,定位任务对低级的细节特征比较敏感,而分类任务则高层特征显得更加关键。因此,一个很自然的问题就是如何在减少计算资源占用的情况下获得兼顾高底层特征的模型。
因此,在 backbone 中,我们设计了一个灵活的搜索空间以寻找最优的通道数,以及下采样与通道数提高的位置。
顺便一提,在搜索 backbone 的过程中,作者根据前人工作的先验知识固定了其中的几个层的类型,并且维持了同一种大类的模型结构(如 ResNet 模型微调了还是 ResNet,ResNeXt 怎么都是 ResNeXt)。因此 backbone 就可以简单地使用字符串编码。具体地可以看论文。
除了 backbone 之外,FPN 的通道数也是可调的,输入的通道数在 128,256,512 中选取,而 head 的通道数也会相应调整。
快速训练方法
作者提出两个在目标检测训练中的致命问题,以及其解决方法,使得模型可以不通过 Image net 进行预训练。错误的 Batch Normalization,因为训练时 GPU 显存的限制,目标检测的 batchsize 通常较小,这导致模型很难估计batch中真实的统计数据,因此极大提高了模型的误差。
为了解决这个问题,使用了 Group Normalization (GN)。GN 将通道分成组,并在每个组中计算用于标准化的平均值和方差。GN 的计算与 batchsize 无关,因此在 batchsize 大幅变化时表现稳定。
复杂的损失函数,检测中的多重损失(分类损失,位置损失,而且不同坐标位置损失还不一样算法)以及 ROI pooling 层阻碍了梯度从 RPN 向 backbone 回传。因此,在从头开始的训练中会出现明显的损失函数震荡以及梯度爆炸现象。
Batch Normalization 可以显著解决梯度爆炸问题,而因为目标检测的 batchsize 比较小不太合适,因此使用了 Weight Standardization (WS) 来进一步平滑 Loss,WS 与 BN/GN 不同,直接标准化了卷积层的权重值,其通过实验展示了这样的操作可以减少损失和梯度值的 Lipschitz 常数。
实验表明,加了 GN 和 WS 之后,训练时可使用更大的学习率,因此也比预训练方法收敛速度快了许多。
多目标搜索算法
在训练的每个层级上,想做的都是生成一个 Pareto 前沿以显示精度和计算资源的一些最佳权衡。
为了生成 Pareto 前沿,本文使用了非支配排序(nondominate sorting)确定模型是否在效率和准确率上支配其他模型。
在第一个层级中,使用一块 V100 GPU 的推断时间作为效率指标,而第二层及中,使用 FLOPs 而不是真实的时间,因为 FLOPs 更加精确(毕竟 backbone 之类的模型都是一个种类的)。除此之外,因为第一层级训练还是预训练+BN,而第二层级转为了 GN+WS,因此使用 FLOPs 可以保持排名的一致性。
搜索基于:
用进化算法来突变Pareto前沿上的最佳的架构;
使用偏序剪枝(Partial Order Pruning),结合“更深更宽的模型更精确”这个先验知识进行剪枝以降低搜索空间。
其他实现细节
第一层级的实现是先随机生成各种模型组合,然后使用演化算法迭代寻找最优组合。经验上跑 5 个 epoch 就可以进行模型比较了。在这个阶段,评估了 500 个模型并花了 2000 GPU hours。
PS:在搜索过程中,MobileNet 的表现最差,这是因为 MobileNet 以时间换空间的做法在 GPU 上反而会降低速度,具体请看我关于 MobileNet 的笔记 [2]。
第二层级使用 GN 和 WS 作为训练策略,而搜索……论文好像没提怎么搜的,可能和第一层级一样?最终第二层级评估了 300 个模型,并消耗了 2500 GPU hours。
[1] https://zhuanlan.zhihu.com/p/78160468
[2] https://zhuanlan.zhihu.com/p/80177088

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。




