机器之心&ArXiv Weekly Radiostation
参与:杜伟,楚航,罗若天
本周的重要论文有管轶课题组与胡艳玲课题组在穿山甲样本中发现冠状病毒以及 MIT 合成生物学中心研究人员利用深度学习方法发现新型抗生素分子 halicin。
Identification of 2019-nCoV related coronaviruses in Malayan pangolins in southern China
Fully hardware-implemented memristor convolutional neural network
CodeBERT: A Pre-Trained Model for Programming and Natural Languages
A Deep Learning Approach to Antibiotic Discovery
Sequence Generation with Optimal-Transport-Enhanced Reinforcement Learning
MALA: Cross-Domain Dialogue Generation with Action Learning
Gradient Boosting Neural Networks: GrowNet
ArXiv Weekly Radiostation:NLP、CV、ML更多精选论文(附音频)。
论文 1:
Identification of 2019-nCoV related coronaviruses in Malayan pangolins in southern China
摘要:
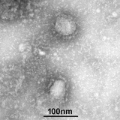
2 月 18 日,来自
香港大学管轶课题组与广西医科大学胡艳玲课题组合作
的研究被提交到生物学预印版论文平台 BiorXiv 上。研究人员对广西和广东反走私行动中查获的多个穿山甲样本进行了检测,并
在穿山甲样本中发现了冠状病毒
,属于此次新冠病毒的两个亚型,其中一个受体结合域与新冠病毒密切相关。
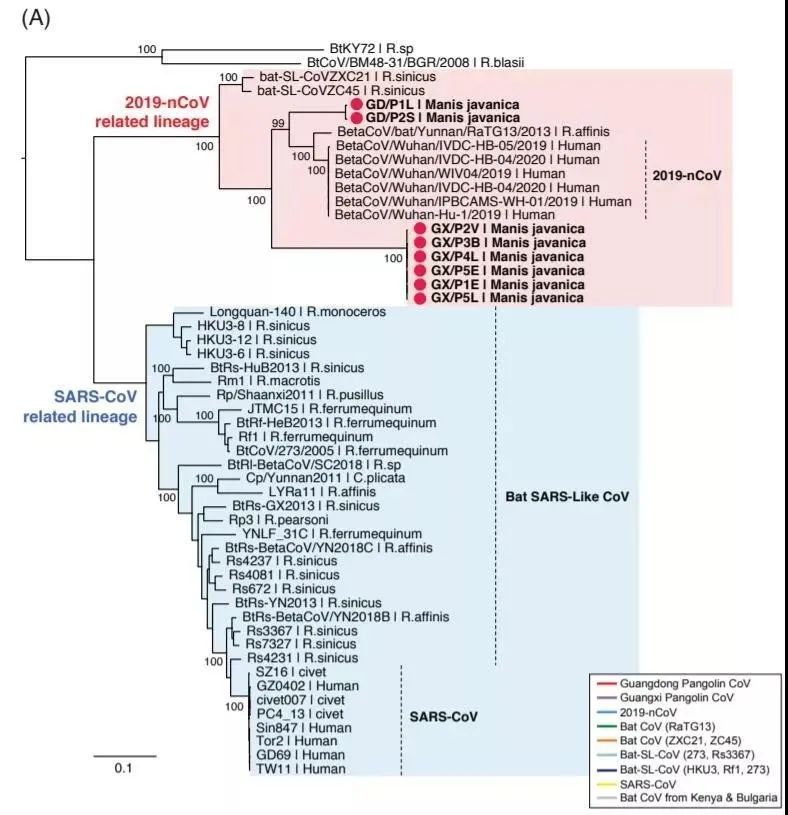
研究显示,穿山甲体内发现的冠状病毒与新冠病毒全序列相似性为 85.5-92.4%, 低于蝙蝠 RaTG13 的 96.2%。但穿山甲病毒的受体结合域(RBD)与新冠病毒更相似,达 97.4%,5 个关键位点完全相同。相比之下,蝙蝠 RBD 与新冠病毒的相似性只有 89.2%,5 个位点只有 1 个相同。此外,新冠病毒 RBD 以外序列与蝙蝠序列更相似,提示存在趋同进化或病毒重组。
![]()
通过扩增子测序等技术,研究者获得了 6 份完整或接近完整的病毒基因组序列,在系统发育分析中,这些都属于新冠肺炎(2019-nCoV)病毒的同族。
![]()
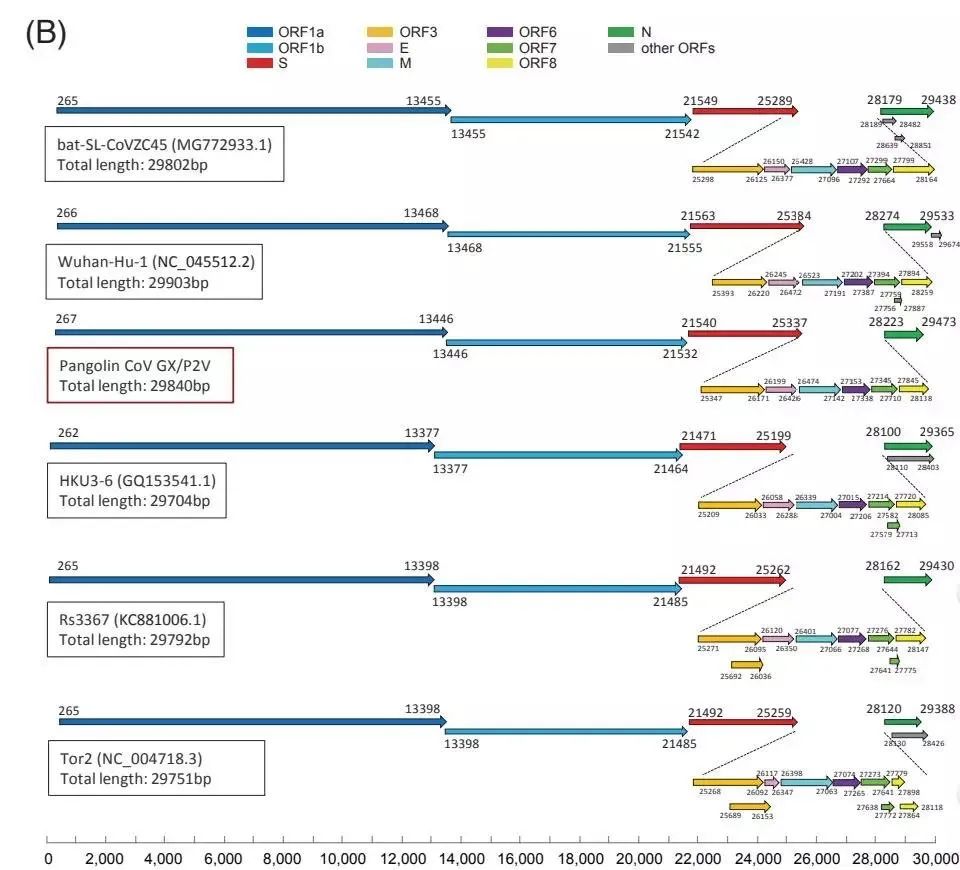
这些病毒的基因组结构也与 2019-nCoV 相似。
![]()
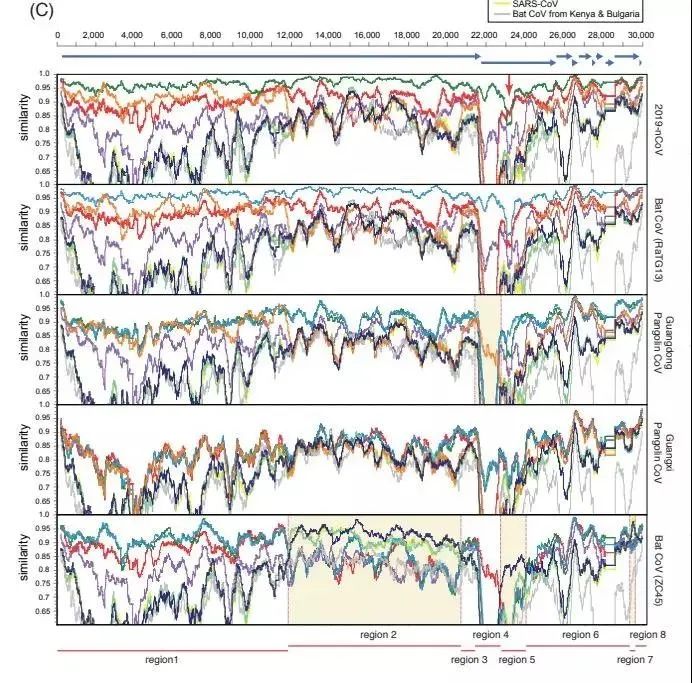
2019-nCoV 与广东穿山甲冠状病毒在受体结合域上表现出了非常高的序列相似性,尽管它的其余部分与蝙蝠冠状病毒 RaTG13 在病毒基因组方面的关系最为密切。
推荐:
在此前华南农业大学的研究报告后,
管轶等人的新论文为穿山甲作为新冠病毒中间宿主的思路提供了进一步的证据
。
论文 2:
Fully hardware-implemented memristor convolutional neural network
摘要:
基于忆阻器的神经形态计算系统为神经网络训练提供了一种快速节能的方法。但是,最重要的图像识别模型之一——卷积神经网络还没有利用忆阻器交叉阵列的完全硬件实现。此外,由于硬件实现收益小、变化大,设备特性不完善,其结果很难媲美软件实现。
不久之前,来自
清华大学和马萨诸塞大学
的研究者在《自然》杂志上发表文章,提出
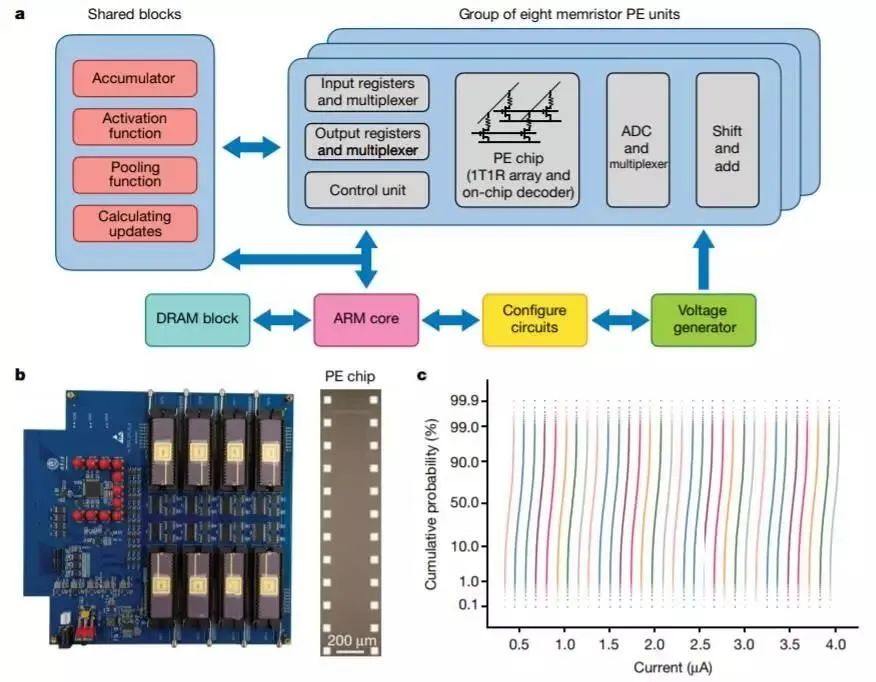
用高收益、高性能的均匀忆阻器交叉阵列实现 CNN
,该实现共集成了 8 个包含 2048 个单元的忆阻器阵列,以提升并行计算效率。此外,研究者还提出了一种高效的混合训练方法,以适应设备缺陷,改进整个系统的性能。研究者构建了基于忆阻器的五层 CNN 来执行 MNIST 图像识别任务,识别准确率超过 96%。
![]()
推荐:
研究者构建的基于忆阻器的五层 CNN
在 MNIST 手写数字识别任务中实现了 96.19% 的准确率
,为大幅提升 CNN 效率提供了可行的解决方案。
论文 3:
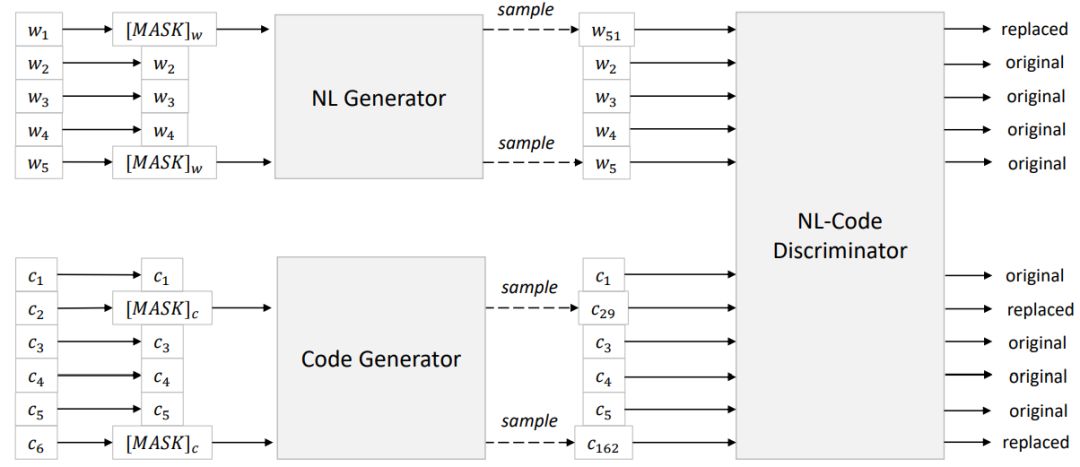
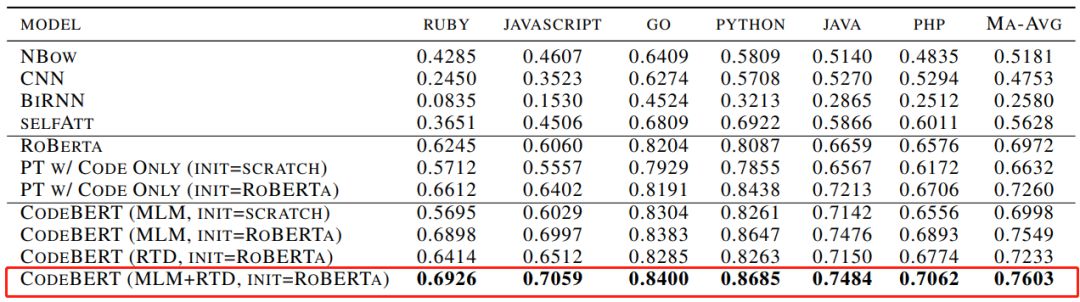
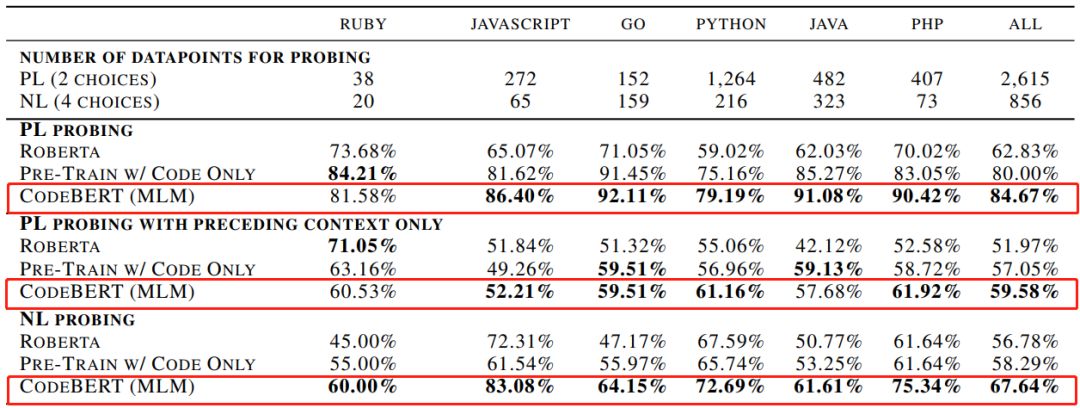
CodeBERT: A Pre-Trained Model for Programming and Natural Languages
摘要:
在本文中,研究者提出了
CodeBERT,这是一种用于编程语言(PL)和自然语言(NL)的双峰预训练模型
。CodeBERT 学习支持自然语言代码搜索以及代码文档生成等下游 NL-PL 应用的通用表征。他们使用基于 Transformer 的神经架构来开发 CodeBERT,并利用结合了 replaced token 检测预训练任务的混合目标函数进行训练,从而用于检测从生成器采样的可能替代方案。
通过对模型参数进行微调,研究者在两个 NL-PL 应用上评估 CodeBERT。结果表明
CodeBERT 在自然语言代码搜索和代码文档生成任务上均实现了 SOTA 性能
。为了调查在 CodeBERT 中学习到了哪种知识,他们还创建了 NL-PL 探测数据集,并在 zero-shot 设置中进行了评估,其中预先训练的模型的参数是固定的。结果表明
CodeBERT 在 NL-PL 探测方面的性能也优于以前的预训练模型
。
![]()
![]()
![]()
推荐:
值的注意的是,
当模型参数固定时,CodeBERT 的性能要优于 RoBERTa 和仅使用代码的连续训练模型
。
论文 4:
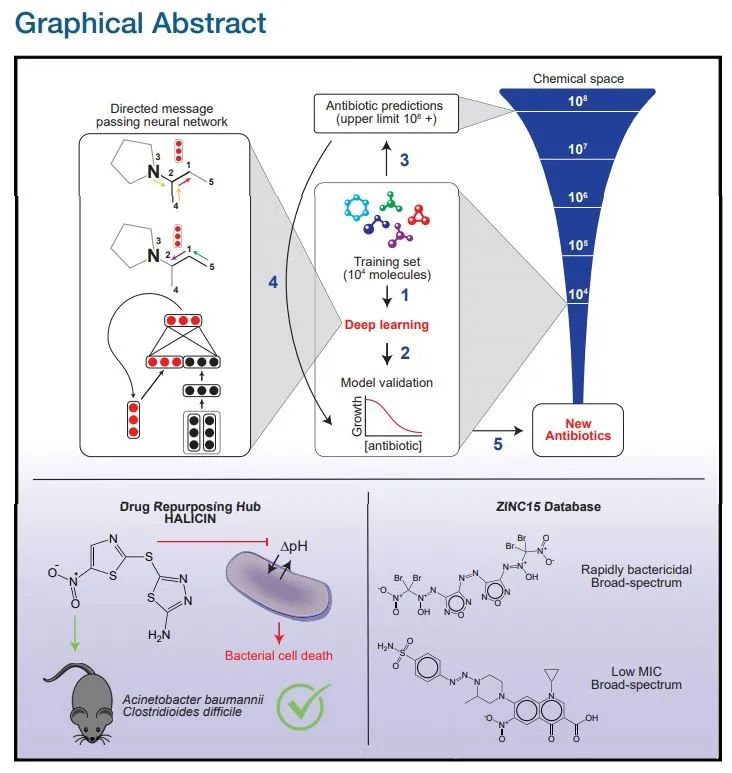
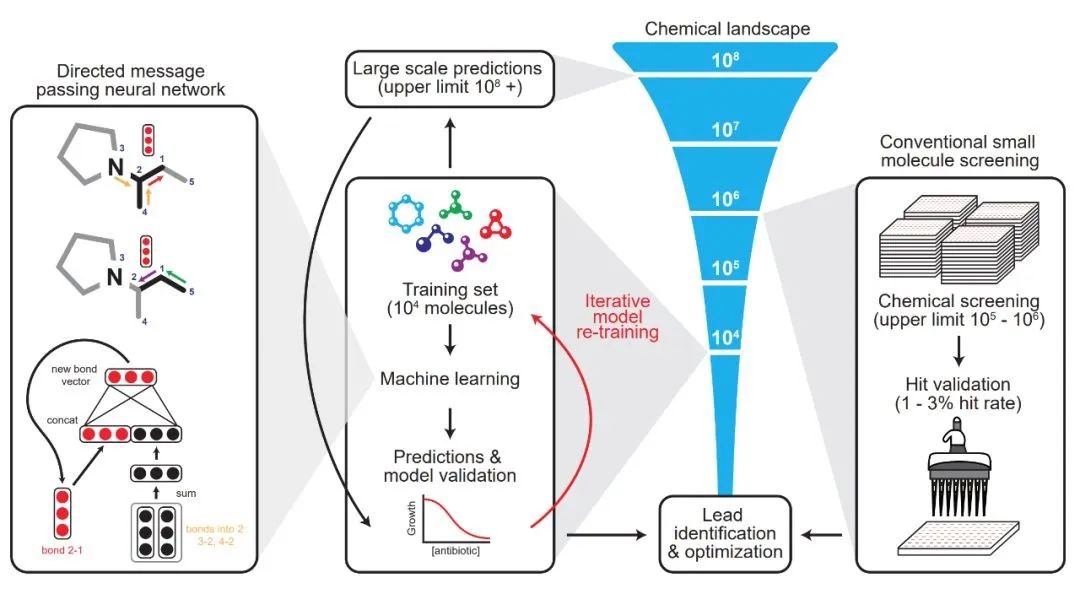
A Deep Learning Approach to Antibiotic Discovery
摘要:
在过去的几十年里,研发人员使用多种传统方法挖掘新的抗生素,但很多时候他们会一次又一次地发现相同的分子,因此新抗生素的发现步履维艰。在此背景下,生物医学界亟需新的方法来帮助发现新抗生素。
为了解决上述问题,来自 MIT 合成生物学中心的研究者开发了一种可以预测抗生素分子活性的深度学习方法,
从超过 1.07 亿种分子中识别出了强大的新型抗生素分子——halicin
。halicin 可以对抗多种细菌,如肺结核以及被认为无法治疗的菌株。而且,这种新发现的分子在结构上与已知的抗生素分子有很大不同。
虽然之前已有使用人工智能作用于部分抗生素发现的应用案例,但研究团队强调,此次最新发现是
基于没有任何先前假设的情况下,完全从零开始识别出的全新抗生素种类
。
![]()
![]()
研究者针对每一个组成部分的 SMILES 表达式建立分子图,其中 SMILES 是一种用 ASCII 字符串明确描述分子结构的规范。
推荐:
这是人类首次完全使用人工智能的方法发现新抗生素
。
论文 5:
Sequence Generation with Optimal-Transport-Enhanced Reinforcement Learning
摘要:
序列生成是 NLP 研究中极其重要的组成部分,序列生成任务包含了很多应用——机器翻译、文本摘要、图像注释以及风格迁移等。
在序列生成模型中,常见的方法之一就是使用 Maximum Likelihood Estimation(MLE)
。这里的 MLE 主要是基于自回归的形式,即最大化已知背景知识(对前面文本进行的编码)后当前单词的条件概率,这种做法导致了暴露偏差(exposure bias)问题,即在训练阶段模型对生成序列的暴露不足,从而导致测试时长序列的语义一致性快速降低。
为了解决这个问题,本文
对 RL 和 OT(Optimal Transport,最优运输)学习的不同状态进行分析
,从而发现了一种
融合了 RL 和 OT 正则化的退火调度学习策略——最优运输 RL (OTRL)
,让 OT 损失自适应地调节 RL 探索时的策略空间,从而让训练过程更加稳定。
![]()
![]()
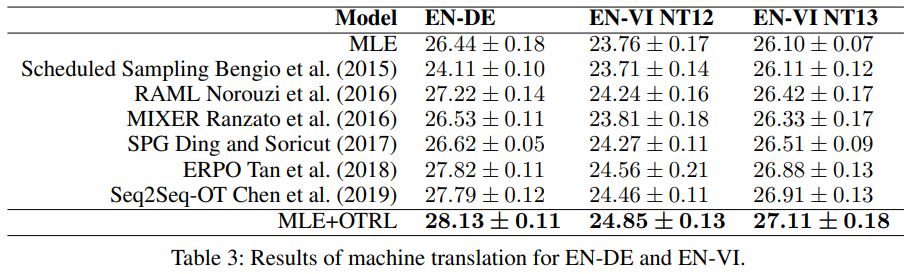
相较于其他基线模型,本文提出的 MLE+OTRL 模型在三个数据集上均实现了性能提升(机器翻译任务)。
![]()
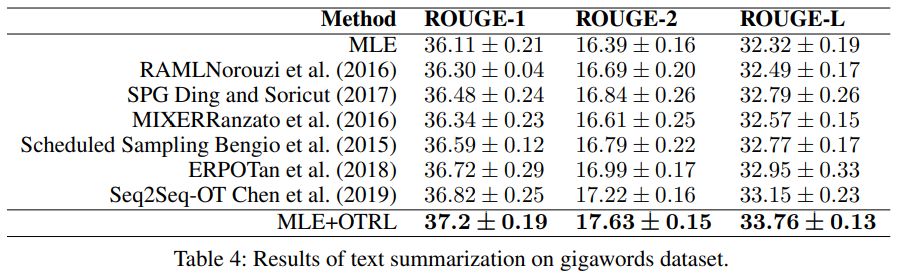
就 Rouge-1、Rouge-2 和 Rouge-L 三项评估指标而言,本文提出的模型在 gigaword 测试数据集上均获得最高分(文本摘要任务)。
推荐:
本文主要是结合了两种不同方法的优点,从而互补了对方的缺点,
将一些简单的算法应用到深度学习算法中去
,也可以获得一些很好的效果。
论文 6:
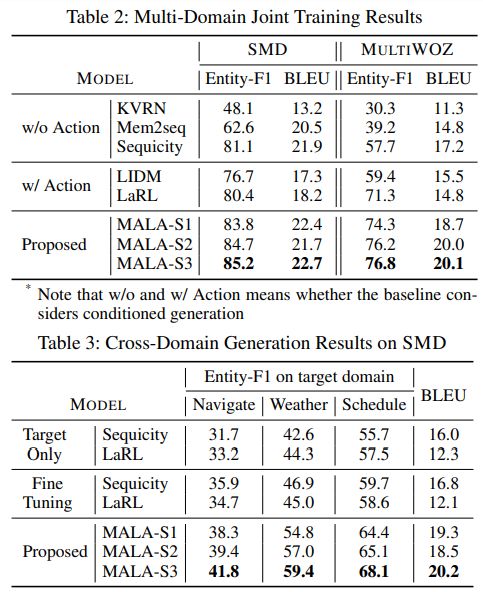
MALA: Cross-Domain Dialogue Generation with Action Learning
摘要:
任务导向的对话系统的主要工作就是在多轮对话中提取出用户的需求,并完成其需求。过去的方法将整个任务看做一个整体来解决,使用生成模型(Encoder-Decoder)直接将对话映射到对应的回答上,但实际上,这个任务是由两部分组成的——对话规划(Dialogue planning)和外部实现(surface realization)。对话规划是指找到完成用户的需求的动作(如找到用户喜欢的食谱或是向用户推荐餐厅),而外部实现则是指将这些动作变成对话内容,这两个任务是会互相影响的,在优化动作选择时会影响到生成的对话的质量,所以直接将这两步合并成一步是不可行的。
为了完成上述任务,
本文提出了一种三段式方法
。首先,为了将潜在意图编码为语义隐动作,作者将一个损失定义为 VAE 重建的对话是否会像输入话语一样引起相似的状态转换。为了更有效地区分话语之间的潜在意图,作者还引入了一种
比较两个系统话语之间结果状态转换相似性的正则化
。本文提出的三步分别是对应有标注数据、无标注数据但可以迁移、专有领域三种情况下的模型训练方法。
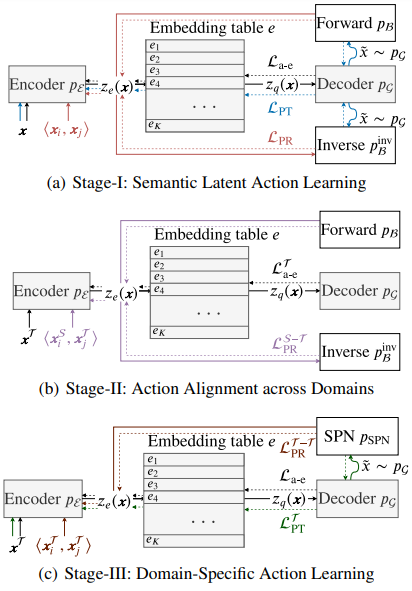
![]()
MALA 三段式整体框架,即语义隐动作学习、跨域动作对齐和特定域动作学习。
![]()
完整模型(MALA-S3)的效果在两个实验中均取得 SOTA 表现。
推荐:
本文主要贡献是通过将问题分解的更加精细、更加全面的模型(
三段式模型
)来对问题进行解决。
论文 7:
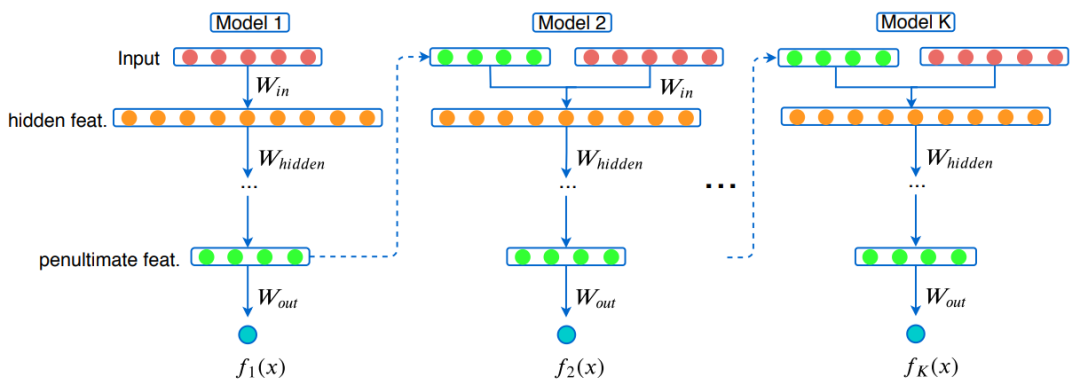
Gradient Boosting Neural Networks: GrowNet
摘要:
在本文中,来自
普渡大学、加州大学洛杉矶分校、领英和亚马逊
的研究者将浅层神经网络部署作为弱学习器,并
提出一种新型梯度提升框架 GrowNet
。在这种统一框架下,一般损失函数可以为分类、回归和排序学习(learning to rank)提供具体示例。此外,合并一个完全正确的步骤(fully corrective step)又能够弥补经典梯度提升决策树的贪婪函数近似的缺陷。
在本文中,研究者提出的 GrowNet 模型
在多个数据集的三项任务上均取得了 SOTA 结果
,控制变量研究也阐明了每个模型组件和模型超参数的影响。
![]()
本文提出的 GrowNet 架构图。在第一个弱学习器之后,根据原始输入的组合特征和前一个弱学习器倒数第二层的特征来训练每个预测器。
![]()
在 Higgs Bozon 数据集上的分类结果(以 AUC 计),其中研究者展示了使用所有数据、10% 数据(1M)和 1% 数据(100K)三种情况下的分类结果。
![]()
在音乐发布年(music release year)和出自加州大学尔湾分校机器学习库的片定位(slice localization)数据集上的回归结果(以 RMSE 计)。
![]()
在 NDCG@5 和 NDCG@10(NDCG,归一化折损累积增益)、微软排序学习(10K 查询)和雅虎 LTR 数据集上的排序学习结果。
推荐:
研究者进一步发现,由于这种新型梯度提升框架 GrowNet 能够
实现更佳性能、更短训练时间以及更方便调整
,所以在分类、回归和排序学习任务上是 DNN 的更好替代方案。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
本周 10 篇 NLP 精选论文是:
1. SBERT-WK: A Sentence Embedding Method by Dissecting BERT-based Word Models. (from Bin Wang, C.-C. Jay Kuo)
2. Scalable Neural Methods for Reasoning With a Symbolic Knowledge Base. (from William W. Cohen, Haitian Sun, R. Alex Hofer, Matthew Siegler)
3. GameWikiSum: a Novel Large Multi-Document Summarization Dataset. (from Diego Antognini, Boi Faltings)
4. HotelRec: a Novel Very Large-Scale Hotel Recommendation Dataset. (from Diego Antognini, Boi Faltings)
5. Fine-Tuning Pretrained Language Models: Weight Initializations, Data Orders, and Early Stopping. (from Jesse Dodge, Gabriel Ilharco, Roy Schwartz, Ali Farhadi, Hannaneh Hajishirzi, Noah Smith)
6. The Microsoft Toolkit of Multi-Task Deep Neural Networks for Natural Language Understanding. (from Xiaodong Liu, Yu Wang, Jianshu Ji, Hao Cheng, Xueyun Zhu, Emmanuel Awa, Pengcheng He, Weizhu Chen, Hoifung Poon, Guihong Cao, Jianfeng Gao)
7. Transfer Learning for Abstractive Summarization at Controllable Budgets. (from Ritesh Sarkhel, Moniba Keymanesh, Arnab Nandi, Srinivasan Parthasarathy)
8. Identifying physical health comorbidities in a cohort of individuals with severe mental illness: An application of SemEHR. (from Rebecca Bendayan, Honghan Wu, Zeljko Kraljevic, Robert Stewart, Tom Searle, Jaya Chaturvedi, Jayati Das-Munshi, Zina Ibrahim, Aurelie Mascio, Angus Roberts, Daniel Bean, Richard Dobson)
9. Improving Multi-Turn Response Selection Models with Complementary Last-Utterance Selection by Instance Weighting. (from Kun Zhou, Wayne Xin Zhao, Yutao Zhu, Ji-Rong Wen, Jingsong Yu)
1. Recognizing Families In the Wild (RFIW): The 4th Edition. (from Joseph P. Robinson, Yu Yin, Zaid Khan, Ming Shao, Siyu Xia, Michael Stopa, Samson Timoner, Matthew A. Turk, Rama Chellappa, Yun Fu)
2. Residual-Sparse Fuzzy $C$-Means Clustering Incorporating Morphological Reconstruction and Wavelet frames. (from Cong Wang, Witold Pedrycz, ZhiWu Li, MengChu Zhou, Jun Zhao)
3. Automated Labelling using an Attention model for Radiology reports of MRI scans (ALARM). (from David A. Wood, Jeremy Lynch, Sina Kafiabadi, Emily Guilhem, Aisha Al Busaidi, Antanas Montvila, Thomas Varsavsky, Juveria Siddiqui, Naveen Gadapa, Matthew Townend, Martin Kiik, Keena Patel, Gareth Barker, Sebastian Ourselin, James H. Cole, Thomas C. Booth)
4. Weakly-Supervised Semantic Segmentation by Iterative Affinity Learning. (from Xiang Wang, Sifei Liu, Huimin Ma, Ming-Hsuan Yang)
5. Model-Agnostic Structured Sparsification with Learnable Channel Shuffle. (from Xin-Yu Zhang, Kai Zhao, Taihong Xiao, Ming-Ming Cheng, Ming-Hsuan Yang)
6. When Radiology Report Generation Meets Knowledge Graph. (from Yixiao Zhang, Xiaosong Wang, Ziyue Xu, Qihang Yu, Alan Yuille, Daguang Xu)
7. Directional Deep Embedding and Appearance Learning for Fast Video Object Segmentation. (from Yingjie Yin, De Xu, Xingang Wang, Lei Zhang)
8. DivideMix: Learning with Noisy Labels as Semi-supervised Learning. (from Junnan Li, Richard Socher, Steven C.H. Hoi)
9. Deep Learning-Based Feature Extraction in Iris Recognition: Use Existing Models, Fine-tune or Train From Scratch?. (from Aidan Boyd, Adam Czajka, Kevin Bowyer)
10. An interpretable classifier for high-resolution breast cancer screening images utilizing weakly supervised localization. (from Yiqiu Shen, Nan Wu, Jason Phang, Jungkyu Park, Kangning Liu, Sudarshini Tyagi, Laura Heacock, S. Gene Kim, Linda Moy, Kyunghyun Cho, Krzysztof J. Geras)
1. Set2Graph: Learning Graphs From Sets. (from Hadar Serviansky, Nimrod Segol, Jonathan Shlomi, Kyle Cranmer, Eilam Gross, Haggai Maron, Yaron Lipman)
2. Algorithmic Recourse: from Counterfactual Explanations to Interventions. (from Amir-Hossein Karimi, Bernhard Schölkopf, Isabel Valera)
3. SYMOG: learning symmetric mixture of Gaussian modes for improved fixed-point quantization. (from Lukas Enderich, Fabian Timm, Wolfram Burgard)
4. Learning Not to Learn in the Presence of Noisy Labels. (from Liu Ziyin, Blair Chen, Ru Wang, Paul Pu Liang, Ruslan Salakhutdinov, Louis-Philippe Morency, Masahito Ueda)
5. Unifying Graph Convolutional Neural Networks and Label Propagation. (from Hongwei Wang, Jure Leskovec)
6. Entity Context and Relational Paths for Knowledge Graph Completion. (from Hongwei Wang, Hongyu Ren, Jure Leskovec)
7. Query2box: Reasoning over Knowledge Graphs in Vector Space using Box Embeddings. (from Hongyu Ren, Weihua Hu, Jure Leskovec)
8. Adaptive Region-Based Active Learning. (from Corinna Cortes, Giulia DeSalvo, Claudio Gentile, Mehryar Mohri, Ningshan Zhang)
9. Jelly Bean World: A Testbed for Never-Ending Learning. (from Emmanouil Antonios Platanios, Abulhair Saparov, Tom Mitchell)
10. BatchEnsemble: an Alternative Approach to Efficient Ensemble and Lifelong Learning. (from Yeming Wen, Dustin Tran, Jimmy Ba)
点击
阅读原文
,查看 ArXiv Weekly Radiostation 全部图文内容。
![]()