伯克利&清华从GPT等预训练语言模型中无监督构建出知识图谱!

近日,图灵奖得主、深度学习教父Yann LeCun在社交媒体发出警告,称“人们对GPT-3这样的大规模语言模型能做什么有着完全不切实际的期待。”

作为一个问答系统,GPT-3不是很好。用“神经”联想记忆大量知识的方法在这方面做得更好。
作为一个对话系统,它也不是很好。其他被明确训练过与人类互动的方法在这方面做得更好。

论文链接:https://arxiv.org/abs/2010.11967
1、展示了如何从预训练语言模型中构建知识图谱。
2、提出了一种无监督的两阶段方法:MAMA。
3、构建了一类全新的知识图谱——开放知识图谱。
那么本文到底如何实现以上三点贡献的呢?
AI科技评论为此联系到了本文的一作王晨光博士和二作刘潇同学来对本文做了亲自介绍,并在之后对他们进行了十五个深度问答。
1
背景介绍

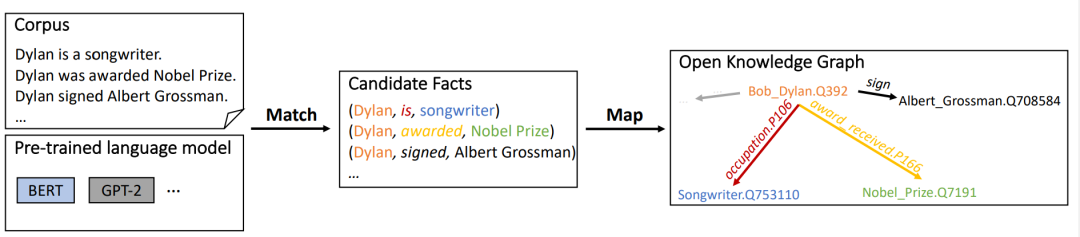 图1
图1
2
方法细节
一、MATCH阶段:注意力权重矩阵上的集束搜索生成候选知识
如图2(a)所示,在第1步生成中(即图中的橙色箭头),“is”被加入到当前生成的候选三元组中得到“(Dylan, is”:因为如图2(b)中所示,在从Dylan出发的注意力权重中(矩阵第一列),is具有最大的注意力分数。当前候选匹配度变为0.3(即0+0.3)
 图2
图2
在实际操作中,由于Transformer具有多头注意力,我们尝试了不同的注意力权重合并策略,并最后发现取多头平均注意力权重的效果最好(详情参考附录)。在第2步的生成中,我们采用相同的步骤,跳过了a生成了songwriter,进而得到“(Dylan, is songwriter”。候选的匹配度此时为0.7(即0.3+0.4)。
3. STOP(停止):如果当前候选已到达尾部实体,那么我们将这整个三元组加入到集束中作为候选知识。当集束大小为1时,(Dylan, is, songwriter)就成为了唯一的结果。对应的最终匹配度为0.7。
以上只是MATCH算法的一个简单例子,详情请参考原文。在实际的语句中,我们还会遇到知识以反向的形式存在的情况,如“… said Jason Forcier, a vice president at battery maker A123 Systems Inc.” ,因此我们允许MATCH算法进行双向的搜索。集束的大小也不局限于1,在实际搜索中以宽度优先的方式进行,最后返回匹配程度最高的k条候选知识。这一集束搜索算法的时间复杂度是O(k·d),其中d为搜索深度。
二、MAP阶段:通过映射候选知识构建开放知识图谱
在获取原始的知识三元组后,需要进行适当的映射,与既有的知识图谱schema(如Wikidata)进行比对合并的同时,我们也对开放schema的结果进行保留整理,从而构建开放知识图谱。
我们获取的第一类知识是可以完全映射到既有知识图谱schema的知识。
利用专家构建的既有知识图谱,可以避免大量重复的实体与关系,也可以为进行自动结果评测打好基础。在这里,我们构建了简单的无监督的实体链接和关系映射方法,以最小的成本来实现这一目标:
实体链接方法:基于维基百科超链接和之前Crosswikis的结果,我们构造了大规模的mention-to-entity词典来进行实体链接。同时,语境信息也对实体链接具有重要的影响,因此我们简单地采用了的Glove词向量进行消歧,从而链接到含义相近的实体。
关系映射方法:本文基本采用了Stanford OpenIE中提出的共现方法来构造关系映射。具体来说,如果一对头尾实体在抽取结果和既有知识图谱中共现,我们认为他们的关系短语很有可能是相同含义的。实际中,我们对关系短语进行词形还原并移除停用词来构建这样的映射。构建完初步的共现结果后,我们人工筛选了候选映射较多的关系短语的前15个结果。同时,我们也仿照Stanford OpenIE对部分关系的实体类型进行了简单的限制。
第二类知识,属于开放schema的知识。
具体来说有两种:
第一种属于半映射的知识,即(h, r, t)中有至少一个可以映射到既有知识图谱的schema中,而这一类也是开放schema知识的主要组成部分;
第二种属于完全开放的知识,即(h, r, t)都完全无法映射到既有的schema中。
如此一来,MAMA构建的知识图谱既包含了既有知识图谱schema范畴内的知识,也包含了更加灵活开放的开放型知识,为下一代知识图谱的构建提供了参考方向。例如图3,是MAMA在Wikipedia的Bob Dylan词条及其邻居词条中抽取出的部分知识图谱。蓝色的点边代表第一类包含于既有schema内的知识,而黄色的点边则代表了开放schema中的新知识。
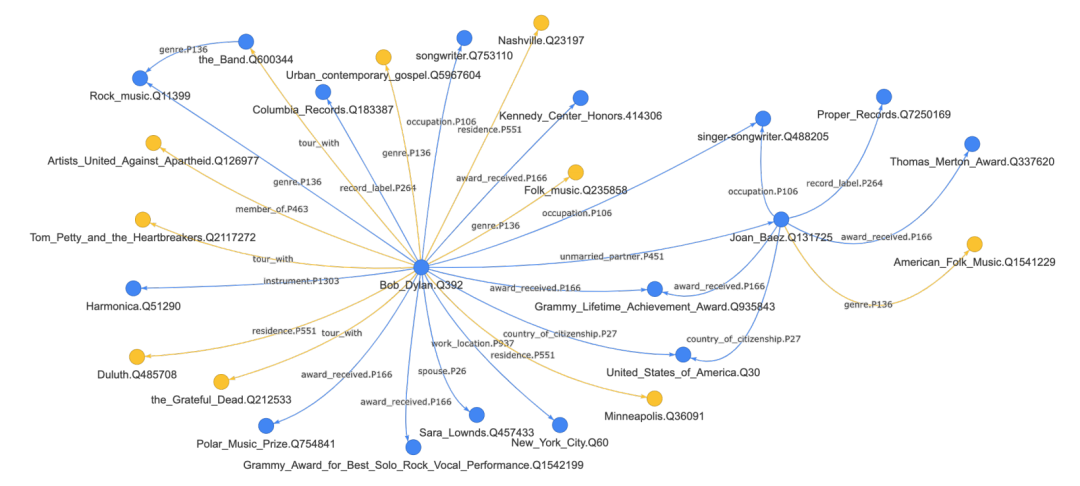 图3
图3
3
结果
 表1
表1
对于第一类可映射到既有schema内的知识,本文在两个大规模数据集上进行了评测。其一是经典的TAC Knowledge Base Population (KBP)的Slot Filling任务(本文选取2013年的数据),根据给定的实体和关系,在大规模文本中寻找填充答案。
但是,KBP标准答案的规模较小,无法很好地验证MAMA是否能在更大规模的数据上具有良好的扩展性,于是本文利用整个Wikidata和英文Wikipedia中的文本进行了评测。数据规模如表1所示。
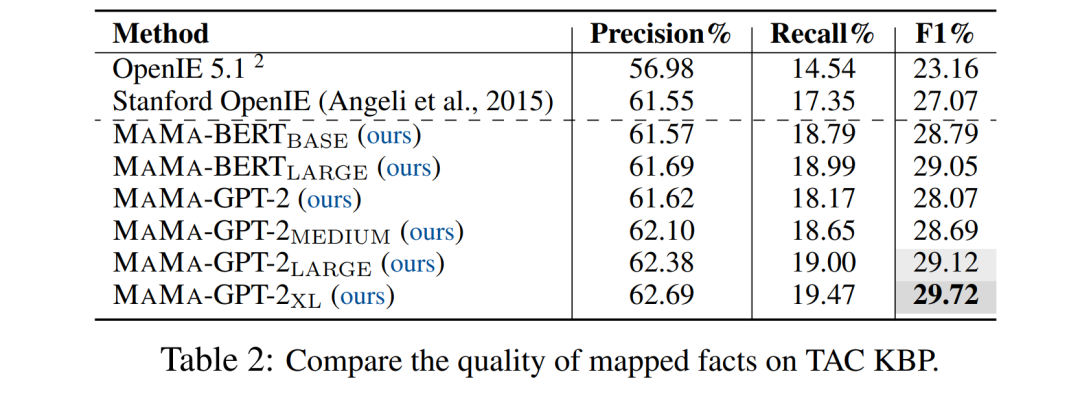
在TAC KBP上,本文与两个经典的开放信息抽取模型OpenIE 5.1(Ollie系统的后继)以及Stanford OpenIE系统(目前TAC KBP 2013任务上最好的开放信息抽取系统)的抽取结果进行了比较。
表2实验表明,MAMA-GPT-2_XL取得了最好的实验结果,也超越了传统的基于句法解析的信息抽取模型。
同时本文发现,随着预训练模型参数量的增大,生成结果的表现会更好。
另外,在同等规模的参数下,BERT在F1指标和召回率的表现相对GPT-2系列模型更好;但是GPT-2的精确度却要更高一些。
这可能是由于Masked LM的训练目标使得BERT学习到比GPT-2更灵活、但也噪音更大的知识。
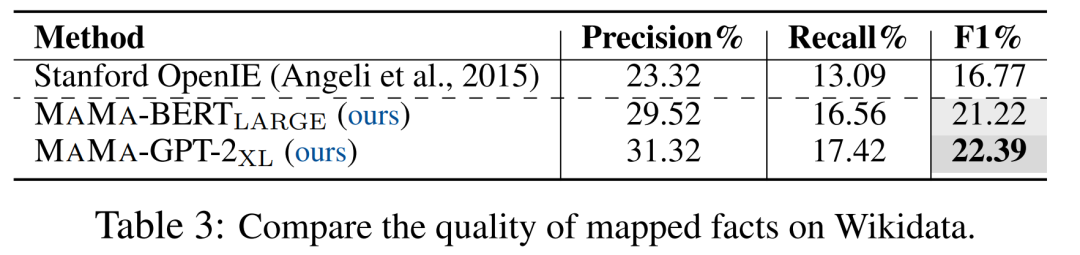
更进一步的,我们在更大规模的Wikidata上验证了我们的结果。
表3中实验结果表明,在更大规模的语料上,相比TAC KBP,MAMA取得了比开放信息抽取方法好得多的表现。同时,这也说明了MAMA具有在大规模语料上的扩展能力。
值得注意的是,Wikidata中知识的构建,很多并非从Wikipedia的文本得来,所以实验的F1表现要比小规模、完全从目标文本中构建的TAC KBP要低一些。
同时也说明了更大规模的文本语料中蕴含有更多的待发掘的知识。
最后,我们也对开放schema内的知识进行了采样和人工评估。
结果发现,抽取出的开放schema知识中,大约35%的知识都是正确的。
这也证明了当前的大规模知识图谱仍然是不完整完善、需要进一步的补充和优化的。
最后,一系列实验结果都表明预训练语言模型中存储了丰富的知识,不但数量上可以超越当前既有的知识图谱,schema上也更加灵活开放。
更多详细的实验分析,请参考原文,另外论文附录中也提供了详细的知识样例。
4
作者简介
本文的工作某种程度上具有突破意义,称得上是一个重要发现的开端,为此AI科技评论特地联系到了本文的作者,对本文的工作问了以下一些问题,以对本工作的前因后果以及存在的优缺点做一个全面的呈现。
5
AI科技评论十五问
1、AI科技评论:这项工作的完成中,哪些人对您帮助或支持很大?
作者:特别感谢Dawn Song,她给文章提供了大力的全面的支持。另外,也要感谢伯克利组里的小伙伴以及一些朋友和师长,Xinyun Chen, Yu Gai, Dan Hendrycks, Qingsong Lv, Yangqiu Song, Jie Tang, and Eric Wallace,他们给文章写作、实验提供了很多很有意义的建议。
2、AI科技评论:从预训练语言模型中构建知识图谱,这项工作的idea怎么来的?
作者:源自一次偶然的实验,发现BERT和GPT-2中的注意力权重可以连接句子中可能的知识成分。
3、AI科技评论:团队之前对知识图谱有过研究吗?对预训练语言模型又有过哪些深耕研究?
作者:团队一直对知识图谱进行着深入的研究。例如Dawn Song在主导计算机安全领域的知识体系构建,王晨光的博士毕业课题就是关于知识图谱构建,刘潇参与了构建全球最大开放学术图谱Open Academic Graph (OAG)。
Dawn Song做过大量有影响力的深度学习工作,例如利用预训练模型提升分布的鲁棒性、对抗攻击、程序合成、设计更好的衡量GPT-3效果的指标等。
4、AI科技评论:传统的构建知识图谱的方式有哪些?具体举一些例子。
作者:构建知识图谱的方式大致分两种:
1)有监督的方式。例如:Wikidata, Freebase, YAGO, YAGO2, DBpedia。这些知识图谱中的知识都是人工基于类似于Wikipedia的inforbox这样的数据源贡献的。
2)半监督方式。像是开放信息抽取系统,例如OLLIE, Reverb, Stanford OpenIE, OpenIE 5.1等。这些系统利用一些语言特征,例如句法分析,从语料中抽取开放schema的知识图谱。还有一些知识图谱,例如NELL, DeepDive, Knowledge Vault或多或少都需要人工参与来贡献固定schema的知识。
不同的是,我们尝试使用预训练语言模型中的知识构建知识图谱,最后生成的知识图谱包括已在现有知识图谱schema中的知识,以及不在现有知识图谱schema中的新知识。
5、AI科技评论:这项工作做了多久?
作者:大概5个月时间。包括搭起整个系统、做到相对高效的数据处理、到运行算法、再到GPU到CPU的调度、最后再到利用数据库做测评。另外本算法实现用的PyTorch Transformers,挺顺利也挺高效。相信大家用起来也会很顺手。
6、AI科技评论:都试过哪些预训练模型,效果如何,实现上有哪些困难,耗费计算资源如何?
作者:BERT和GPT-2系列都用了。当然最想试GPT-3,可惜还没开源。遇到的困难是计算资源,因为我们需要在六百万的文本语料上运行目前公开的最大的预训练语言模型之一GPT-2_XL。最后还是老板Dawn Song帮助我们解决了这个问题。文章末尾的附录中也提到了,最后我们使用了20台4卡的K80,单卡12G显存。
7、AI科技评论:从输入和输出的角度再谈一下本文的算法,另外算法还有改进空间吗?
作者:算法的输入是语料和预训练语言模型,输出是构建好的知识图谱。
这次提出的方法算是一个将深度模型和知识图谱连接起来的初步尝试,当然可以从不同的方面继续改进,文中也提到了,例如:知识的高阶推理、利用图神经网络生成更准确的关系、提升实体识别的准确度、学习质量更高的关系映射等等,欢迎有兴趣的朋友邮件联系。
8、AI科技评论:这项工作的价值在哪里?从理论和应用两方面来谈谈。
作者:MAMA向我们展示了可能的下一代知识图谱的新形态,并对深度学习和知识图谱之间的连接有一定启示意义。
理论价值:主要是深入的解释了深度预训练语言模型学到了什么,可解释地桥接起“预训练语言模型”和“知识图谱”两个研究社群。
另外,揭示了深度预训练语言模型和知识图谱之间的关系,即他们本质上都是对于世界上相同知识的编码,只是编码形式不同。从文中初步实验结果上看,两者从知识的角度来说几乎可以等价。当然,本文提出的方法只是这一方向上的初步尝试,抛砖引玉。
应用价值:一方面可以帮助深度学习研究者更好的理解模型所学,从而进一步帮助改进深度模型;另一方面为构建知识图谱或者做基于知识图谱应用的研究者提供新思路,例如,基于文章构建出的知识图谱包含了现有知识图谱中没有的知识,这些知识能否进一步帮助推理、问答等下游任务。
9、AI科技评论:可解释方面,如何在深度学习和知识图谱之间建立起一座桥梁呢?团队对可解释性研究还有哪些感悟呢?
作者:深度语言模型参数量太大,本身确实很难解释。这个工作的目的就是初步提供一种形象的解释,通过知识的形式展现。如上面所说,预训练语言模型和知识图谱本质上或许都是对于世界上知识的编码,只是形式不同。但这个假设还需要进一步验证,我们的工作进行了初步的探索。
可解释研究的下一步,我们觉得就是要找到一种基于合理假设的解释形式,例如知识图谱的形式,就是基于深度语言模型也是在编码知识这个假设。有了这个假设,呈现的解释结果更容易被人们理解,更能引导研究者进行针对性研究。
10、AI科技评论:本文已经受到了一些关注,对一些收到的反馈有什么回应?
作者:首先感到非常幸运,非常感谢国内外同行对于工作的关注,关注的本身就是一种对于工作的认可,也有利于这个方向之后的长期发展。同时注意到大家比较关注本文跟LAMA的对比,不同很多,列举如下几点:
(1)研究的问题不同:LAMA是做填空题,即给定“Dylan is a _”,预测“_”处应该填什么词,跟知识图谱无关。
本文提的方法MAMA是做推断题,即给定一篇文章,直接生成一个三元组(Dylan, is, songwriter),然后映射到知识图谱中,MAMA在尝试解决更难的问题。
(2)数据集不同:本文中最大的数据集Wikidata比LAMA文章中最大数据集大三个数量级;
(3)本文提出的方法MAMA跟LAMA名字上的相似纯属巧合:他们的含义完全不同,本文MAMA是Match和Map的缩写,LAMA是LAnguage Model Analysis的缩写。
另外值得注意的是,该工作中我们提的方法是无监督学习,因为生成知识图谱的算法Match和Map都不需要训练数据,是通过一步前向传播完成的,无需微调或训练。事实上,在整个系统的构建中,除了使用少量人工定义的过滤规则、阈值以及开源工具,我们避免了人类进行任何直接的标注工作。无监督的方式可以与开放信息抽取系统的方法进行类比,例如开放信息抽取系统的抽取过程是无监督的,尽管抽取时使用到的规则是基于句法分析工具得来的,其中句法分析模型是基于有监督学习训练得来的。
11、AI科技评论:文中有说到用预训练语言模型生成的知识图谱可以发现传统知识图谱中不存在的知识,具体举一些例子?
作者:论文中Figure 3,Figure 17-32中黄色的结点和边代表部分传统知识图谱Wikidata中不存在的知识。Figure 8-10代表了部分不存在于TAC KBP中的知识。Figure 14-16代表了部分不存在于Wikidata中的知识。论文中从第13页开始的附录中提供了方法的更多细节和结果。
具体例子如:我们在图3中展示了基于文章中方法生成的知识图谱的一小部分。这部分展示了一些与传奇歌手诺贝尔文学奖获得者鲍勃·迪伦相关的知识。包含已经存在于现有Wikidata中的知识,例如,(鲍勃·迪伦,职业,歌手),(鲍勃·迪伦,获奖,格莱美终身成就奖),(鲍勃·迪伦,妻子,萨拉·朗兹)等。同时也含有现有知识图谱中不存在的知识,例如,(鲍勃·迪伦,曾居地,纳什维尔),(鲍勃·迪伦,音乐类型,民谣),(鲍勃·迪伦,巡回演出,感恩至死)。另外,文中方法生成的知识图谱中还包括了一些其他现有知识图谱中不存在的有趣的知识,例如,挪威冒险家索尔·海耶达尔是位无神论者,德国生物学家恩斯特·海克尔是名和平主义者和社会达尔文主义者,威尔士足球运动员内维尔·索撒尔也兼领队。
12、预训练语言模型生成的知识图谱相比传统构建的知识图谱有哪些优势和不足?该如何改进?
作者:优势主要是无监督。不足就是不存在于现有知识图谱中知识的评测问题。后续计划利用众包来加强对于新知识的评测。
13、预训练语言模型被很多人诟病缺乏知识理解能力,只是单纯的概率关联,你们构建的知识图谱会存在这样的问题吗?能否举例说明?如果存在这样的问题,要如何解决?
作者:我们提出的方法就是尽可能保证留在我们构建的知识图谱中的知识相对高质量。不过还是发现没有映射到现有知识图谱中的知识会出现一些没有太大信息量的知识,例如(He, made, breakthough)。
解决方法包括:使用更有力的生成算法,例如基于图神经网络的算法从而利用注意力权重矩阵中的结构化信息。当然也包括进一步增强Map算法,例如利用语言模型本身信息抽取更准确的实体、利用lifelong learning得到更鲁棒的关系映射等。
14、AI科技评论:很多人提出预训练语言模型的缺陷要结合知识图谱来弥补,您怎么看?
作者:语言模型和知识图谱可能在服务不同的应用时有各自的优势。例如做文本分类,语言模型因为其特征生成的优势,所以更具竞争力。但是在做逻辑推理等问题的时候,知识图谱这种更精确的知识表达,会更有优势。文章提出的方法可以看做是语言模型和知识图谱间的一座桥梁,可以用来理解和弥补各自在一些下游任务上的不足,并保有各自长处。当然如前面所说,提出的方法还有很大待改进的空间。
15、AI科技评论:最后,代码和知识图谱会开源吗,什么时候开源,后续围绕这项工作还会开展哪些研究?
作者:一定开源。后续研究会很丰富,包括
改进Match算法:如前面提到的使用图神经网络生成关系;
强化Map阶段:通过lifelong learning学习更好的知识映射;
强化评价体系:利用众包对不在既有知识图谱中的知识进行更大规模的标注和评价;
更好的知识图谱:利用更大的模型,例如GPT-3(如果开源的话),在更大的语料上,例如Common Crawl,生成质量和数量都更进一步的知识图谱。
最后,作者团队特别说明,论文是基于一个假设:预训练语言模型和知识图谱本质上都是对于世界上知识的编码,形式不同。虽然文章进行了初步探索,但这个假设需要更多人参与进来一起进一步验证。
我们期待这个假设成立,也期待着文章开头LeCun所说的预训练语言模型的诟病能得到一部分答案,至少,预训练语言模型能帮助无监督地构建出知识图谱了!





点击阅读原文,直达NeurIPS小组~



