博客 | 一个项目的经验教训:关于打乱和拆分数据

最近因为某事要准备一点材料,刚好前段时间给导师做项目的时候遇到一个大坑,浪费了很多时间,所以就着这个问题顺便做点总结。
传统的机器学习,即在深度学习流行之前的问题的一般处理流程通常是“预处理->特征变换->分类/回归”。即便现在深度学习似乎要统治业界,但要转换成这样的步骤,也不过是将“特征变换”与“分类/回归”合二为一而已,该做的预处理往往还是要做。《深度学习(Deep Learning Book)》里提过一种对深度学习的诠释思路——深度表示学习,与之类似。
但放到现实问题中来看,机器学习只不过是整个问题解决过程中一个很小的组成部分。比如在公司做业务,你要收集数据、清洗数据、建立合适的数据结构,对大规模数据可能还要顺便把大规模分布式问题解决一下。等费劲千辛万苦拿到“干净”的数据之后,才进入机器学习/模式识别问题的一般步骤。
而实际上,至少七成时间花在了准备数据的阶段。很多人学机器学习往往只重视算法或者模型,学深度学习的只看网络结构和调参方法,但不要忘了,这是因为有人为你准备好了数据集和评测流程、方法。对于实际问题,这一整套框架都要根据实际情况去设计、改进,使之贴近业务,提供更好的服务。
做科研有做科研的方法,做实际业务是另一套模式。业界需要的大量的算法工程师,往往是做这些看似琐碎的无趣的活,这样看来程序员转算法工程师其实是比较容易的。
啊哀叹一下为什么我编程这么菜……
扯淡结束。这篇博文要记录的内容,与数据集的制作与划分有关。
本文还是以大白话写就,您读着也省劲,我写得也轻松。
Part 1. 实例: 一个信号处理问题
就从实际问题的背景开始,由导师的项目说起吧。
项目需要完成一个系统,我负责实验设计、总体设计和信号处理+识别。这个项目的信号或者说数据是按时间采样得到的,比如说采样率是500Hz每秒就能得到500个点。一次采集在一分钟以上,只需要其中的不到三十秒的数据。
所以问题就来了:得到一组数据需要至少一分钟,而且这个采集过程不能长时间运行,一次实验最多采三十组数据;更尴尬的是,实验比较特殊,不是想做几组就做几组的。
也就是说,我们必须要用比较少的采集组数得到数据集,还要训练一个比较可靠的模型,用来做信号的识别/分类。
一开始我想得很简单——少就少呗,无非是个小样本学习的问题。找一个鲁棒性比较好的特征变换方法,用简单点儿的分类模型,分分钟解决问题,反正设计指标也不高。
但说归说,只有十几二十个样本,谁能保证训出来的模型能用啊。
查了一些文献,又结合系统的要求,最后选择用滑动窗分割的方法来增广数据集,即设置一个固定时长的滑动窗在时域信号上滑动,重叠时长为0,这样把一个样本切割成几十份样本,数据集扩增了几十倍。瞬间就把样本不足的问题解决了。
采取这种方式,一是有人一直在这么做,二是系统实际工作时处理过程也与之类似——总不能后台默默跑一分钟才告诉你一个结果吧?最好是几秒钟就显示一个结果,让甲方知道我们的系统在干活,而不只是琢磨着怎么把他们的钱忽悠走。
离线测试效果奔波儿灞,不是,倍儿棒,正确率直接奔着95%去了。老实说当时我是有点怀疑的,但稍微动了一下脑子,感觉最多也就是线上比离线差点儿,总不能太糟吧。
怕啥来啥。线上测试二分类正确率50%。
当时我就蒙了。接着回炉重造,想到一个比较特殊的情况,改模型再训,嚯!99%!心想这回总不至于那么差吧,一上线还是完蛋。
那几天是真烦,实在想不清楚怎么就完蛋了。
过了大概大半星期,忽然产生了一个念头——是不是数据集有问题?
众所周知,我们一般做机器学习要在数据集上 shuffle,然后按比例划分训练、验证和测试集。这个系统模型比较简单没几个超参,样本又少,出于侥幸心理干脆就省略了验证集。
但问题在于,这个数据集是怎么得到的?是从大约二十组信号上“片”出来的。
我隐约察觉问题在哪儿了。然后就实验验证呗。
从时间的角度考虑,系统需要用“过去”的数据去预测“未来”。所以这一回我先划分了训练和测试集数据,然后再做切片。其实在这里,数据根本不需要 shuffle ——分类器是 linear classifier 或 SVM,训练过程是一次把所有数据喂进去。Shuffle 没有任何意义。
这回的测试结果看起来比较“正常”了——在50%和60%之间浮动。好嘛问题终于是定位到了,但新的问题是,这样一来我用的信号处理方法对分类根本没效果,简直一夜回到解放前。
后来我对一些小细节做了一点调整,最近参与的三个人差不多把全新的系统调试完了,具体效果……我猜设计要求的70%还是能达到吧。不再细说。
Part 2. 数据集的制作与划分,方法要根据问题而定
所以说,通过这一课我学到了什么?
shuffle 不要乱用
算法一定要贴在具体业务上
为什么我的模型会线下99%、线上50%?
显然是对线下模型过拟合了。但我明明做了训练集和测试集啊?问题就出在这儿:
我增广之后,先 shuffle、再划分。对学术界的很多数据集,这么做可能完全没影响,但没影响不代表它是对的。Kaggle 、天池之类的数据竞赛,训练集和测试集都是提前划分好的,有没有想过其中的道理?
打个比方,我的错误操作,就像中学时候不会做的题目抄答案,但每次只看一半,理由是“只要给个思路我就会做了”。当然,这纯粹是自己骗自己。
先 shuffle 再划分,就相当于“答案只看一半”——“过去”的数据和“现在”的数据混到了一起,模型既学到了“过去”的模式,又学到了“现在”的模式,准确率自然可观;而“未来”的数据是不可见的,模型显然学不到“未来”的模式。
所以正确的方法是先划分。Shuffle 可以不用。因为 shuffle 的作用体现在 mini-batch learning 的时候。一次性训练的分类器使用 shuffle 并没有什么意义。
第二点体会就结合我的方向来说了。去年去北京听课,天津大学的一位博后在讲实验设计和信号处理方法的时候提到,我们这个领域多年来已经遇到了瓶颈,具体体现在算法的提升作用越来越小,实验设计反倒比处理方法重要得多。
我非常赞同。
深度学习火起来之后,领域内不少人也研究过基于深度学习的处理方法,但经得起考验的成果不多。一方面深度学习不是万能的,另一方面,多年来进展缓慢,侧面说明我们这个领域可能真地存在这么一个天花板。我觉得具体问题就在信号采集的方式和设备上面——这个话题不展开讨论——结果就是,受制于“硬件”限制,在实验设计上出成果比在算法上出成果要容易。
这就是说,对很多实际问题来说,算法并不是关键。按照 Andrew Ng. 和国外很多博客的观点,围绕你的目标设计一个好的 pipeline,包括如何对数据的建模、一个衡量模型好坏的基准等等,然后不断改进,这才是使用机器学习的有效方式,而不是只针对其中算法的部分尝试各种分类/回归器,或者想用深度学习调参搞定一切。这正是 NFL 定理的意义:如果不考虑具体问题,所有的算法都是随机猜测,没有好坏之分。
Part 3. 另一个案例: Google MLCC 十八世纪文学
因为一些缘故不太想把我的方向说太细,结果刚好前几天把 Google 新出的机器学习课程 MLCC 过了一遍,发现最后有个案例跟我遇到的问题简直一模一样,在这里简单介绍一下吧。
课程页面见 https://developers.google.com/machine-learning/crash-course/ ,显然需要翻~墙。课程自带中文、中文字幕和机器配音(非常带感,建议体验一下)。案例在 https://developers.google.com/machine-learning/crash-course/18th-century-literature。
Google 工程师与一位研究十八世纪文学的教授合作,开发了一个“心灵隐喻(the metaphors to the mind)”数据库,记录了十八世纪所有的文学作品中关于“心灵”的隐喻的句子,比如“心灵是一座花园”“心灵是一块白板”。这位教授想了解是否能从这些作者使用的隐喻中得知他们的政治派别。
把数据集划分、训练之后,发现准确率非常高。他们觉得这里面肯定有问题。
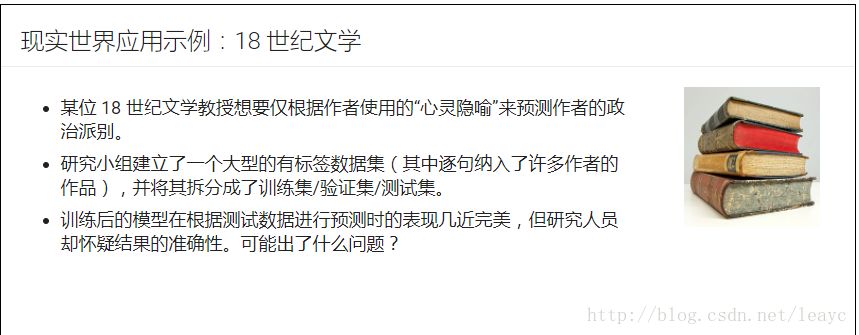
这是他们最开始划分数据集的方式:
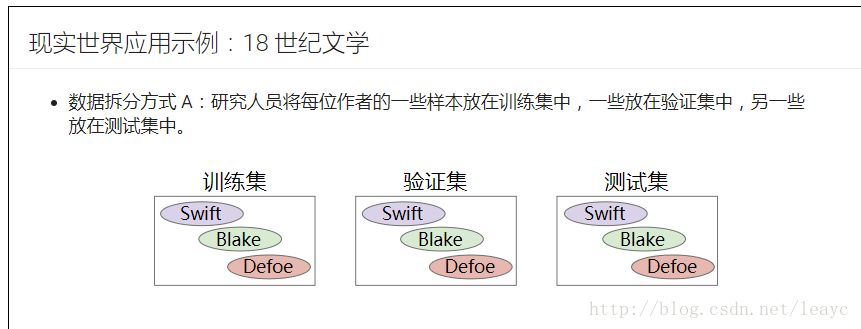
逐句拆分样本。某位作者的句子在训练、验证和测试集中均存在。这样一来,模型不仅学到了隐喻,还学到了这位作者写作语言的特点,即模型记忆了关于作者的额外信息。
发现这个问题后,他们重新划分数据集,把某位作者的作品仅放在训练或测试或验证集中,即:
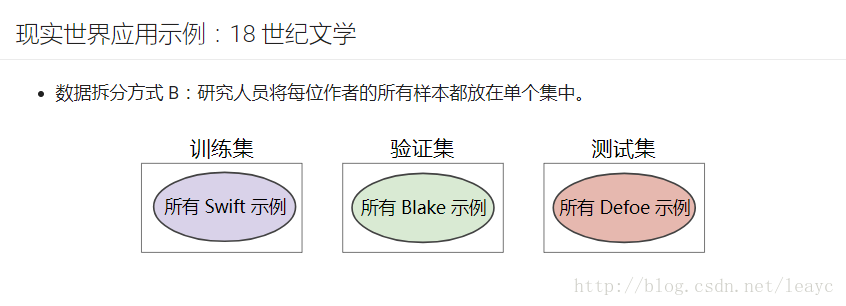
现在准确率大幅下降,而且很难得到比较高的准确率,即仅根据隐喻来判断政治派别,是一件非常困难的事情。

讲师最后总结说,这个案例说明:在随机打乱数据和拆分数据之前,需要考虑数据本身的意义。

Update
写完发出去才反应过来:
正在跑着的程序,一篇 AAAI-18 上本领域的文章,我顺着作者找到了他们没有公开的 Github 地址。当时看到 paper 就怀疑他们结果有问题,准确率未免太高了。
看了一下代码,发现跟上面讲过的一样,也是把所有数据拿出来打乱再划分。唉,简直是……特么的在逗我。
一叶知秋,可见顶会 paper 也未必靠谱。




